Regularizing Hidden States Enables Learning Generalizable Reward Model for LLMs
作者: Rui Yang, Ruomeng Ding, Yong Lin, Huan Zhang, Tong Zhang
分类: cs.CL, cs.AI
发布日期: 2024-06-14 (更新: 2024-10-23)
备注: NeurIPS 2024
💡 一句话要点
通过正则化隐状态,提升LLM奖励模型的泛化能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 奖励模型 泛化能力 隐状态正则化 大型语言模型 强化学习 人类反馈 分布外泛化
📋 核心要点
- 现有奖励模型泛化性不足,易导致奖励过度优化,降低LLM实际性能。
- 通过正则化隐状态,保留文本生成能力,提升奖励模型对分布偏移的泛化性。
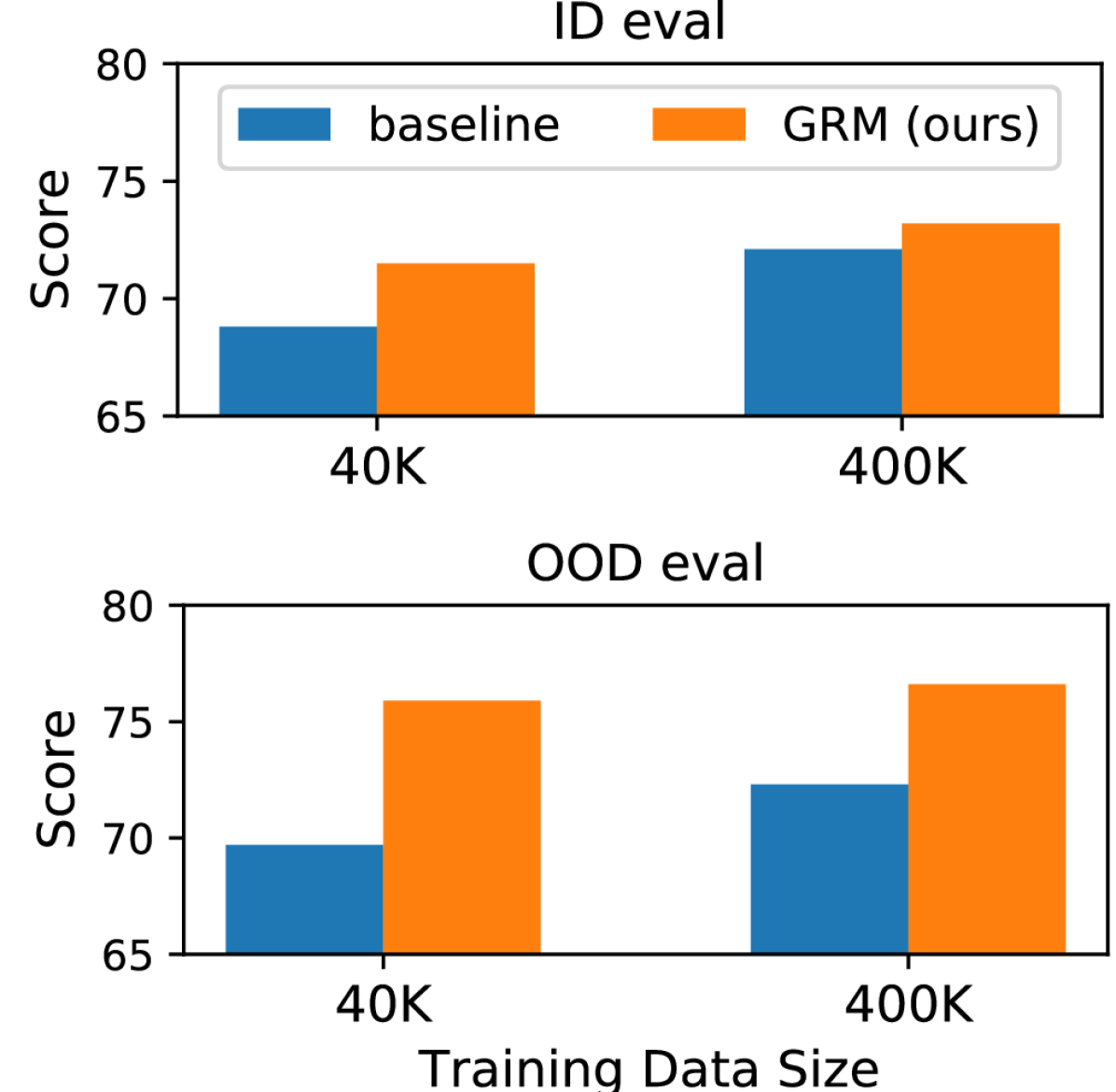
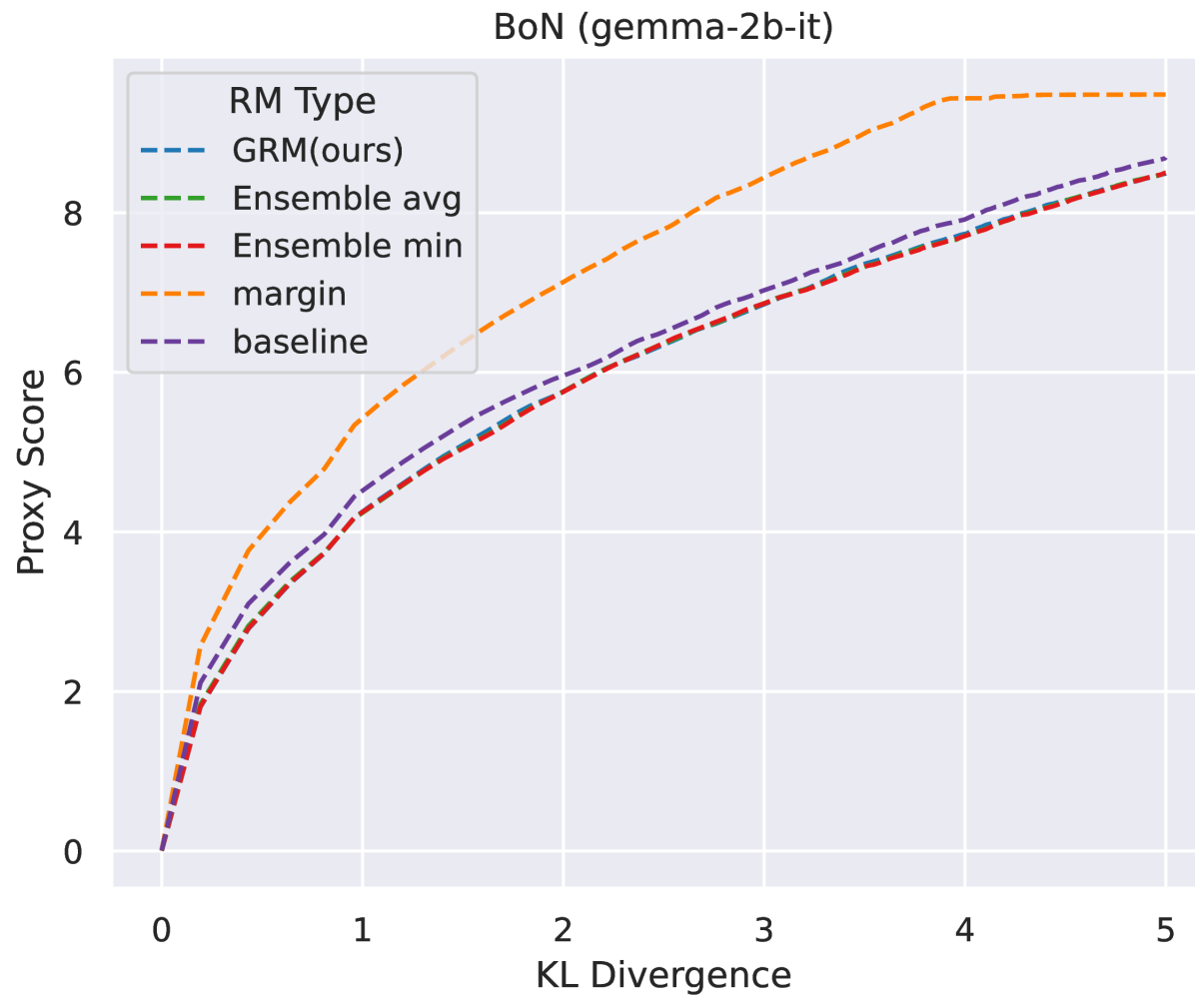
- 实验表明,该方法显著提升了奖励模型在OOD任务中的准确性,缓解了过度优化问题。
📝 摘要(中文)
奖励模型在基于人类偏好数据的训练中,已被证明能有效对齐大型语言模型(LLMs)与人类意图,这得益于从人类反馈中进行强化学习(RLHF)的框架。然而,当前的奖励模型对未见过的提示和响应的泛化能力有限,这可能导致一种称为奖励过度优化(reward over-optimization)的意外现象,由于对奖励的过度优化,导致实际性能下降。虽然之前的研究提倡约束策略优化,但我们的研究引入了一种新方法,通过正则化隐状态来增强奖励模型对分布偏移的泛化能力。具体来说,我们保留了基础模型的语言模型头,并结合了一套文本生成损失,以保持隐状态的文本生成能力,同时在相同的隐状态后学习一个奖励头。我们的实验结果表明,所引入的正则化技术显著提高了学习到的奖励模型在各种分布外(OOD)任务中的准确性,并有效缓解了RLHF中的过度优化问题,从而提供了一种更可靠和稳健的偏好学习范式。
🔬 方法详解
问题定义:现有基于人类反馈的强化学习(RLHF)框架下的奖励模型,在面对未见过的提示和响应时,泛化能力不足。这导致奖励模型容易被过度优化,即模型在训练集上表现良好,但在实际应用中性能下降。现有方法主要集中在约束策略优化上,但忽略了奖励模型本身的泛化能力问题。
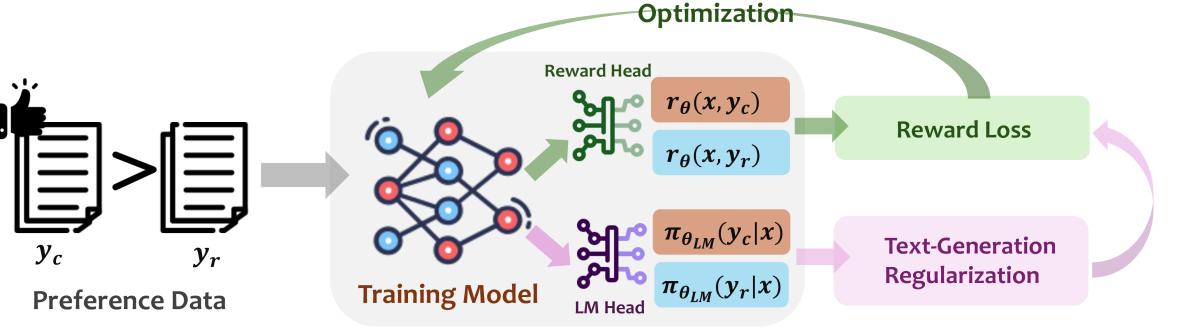
核心思路:论文的核心思路是通过正则化奖励模型的隐状态,使其在学习奖励的同时,保持其原有的文本生成能力。这样可以防止奖励模型过度拟合训练数据,从而提高其对分布外数据的泛化能力。具体来说,就是在训练奖励模型时,不仅要学习一个奖励头,还要保留基础模型的语言模型头,并使用文本生成损失来约束隐状态。
技术框架:该方法的技术框架主要包括以下几个部分:1)一个预训练的语言模型作为基础模型;2)一个奖励头,用于预测给定文本的奖励值;3)一个语言模型头,与基础模型共享隐状态;4)一个文本生成损失函数,用于约束隐状态的文本生成能力。整个训练过程是联合训练奖励头和语言模型头,目标是最小化奖励预测误差和文本生成损失。
关键创新:该论文的关键创新在于提出了一种通过正则化隐状态来提高奖励模型泛化能力的方法。与现有方法不同,该方法不是直接约束策略优化,而是从奖励模型本身入手,通过保留隐状态的文本生成能力来提高其泛化能力。这种方法可以有效地缓解奖励过度优化问题,提高LLM的实际性能。
关键设计:关键设计包括:1)选择合适的文本生成损失函数,例如交叉熵损失或语言模型困惑度;2)设置合适的正则化系数,以平衡奖励预测误差和文本生成损失;3)选择合适的网络结构,例如Transformer或LSTM,作为基础模型和奖励模型。
🖼️ 关键图片
📊 实验亮点
实验结果表明,该方法显著提高了奖励模型在各种分布外(OOD)任务中的准确性,并有效缓解了RLHF中的过度优化问题。具体来说,该方法在多个OOD数据集上取得了显著的性能提升,并且在RLHF训练中,能够使LLM获得更高的实际性能,避免了奖励过度优化导致的性能下降。
🎯 应用场景
该研究成果可广泛应用于各种需要对齐LLM与人类意图的场景,例如对话系统、文本摘要、代码生成等。通过提高奖励模型的泛化能力,可以使LLM在更广泛的任务上表现更好,并减少人工干预的需求。此外,该方法还可以应用于其他类型的机器学习模型,以提高其泛化能力和鲁棒性。
📄 摘要(原文)
Reward models trained on human preference data have been proven to effectively align Large Language Models (LLMs) with human intent within the framework of reinforcement learning from human feedback (RLHF). However, current reward models have limited generalization capabilities to unseen prompts and responses, which can lead to an unexpected phenomenon known as reward over-optimization, resulting in a decline in actual performance due to excessive optimization of rewards. While previous research has advocated for constraining policy optimization, our study introduces a novel approach to enhance the reward model's generalization ability against distribution shifts by regularizing the hidden states. Specifically, we retain the base model's language model head and incorporate a suite of text-generation losses to preserve the hidden states' text-generation capabilities, while concurrently learning a reward head behind the same hidden states. Our experimental results demonstrate that the introduced regularization technique markedly improves the accuracy of learned reward models across a variety of out-of-distribution (OOD) tasks and effectively alleviates the over-optimization issue in RLHF, offering a more reliable and robust preference learning paradigm.