HIRO: Hierarchical Information Retrieval Optimization
作者: Krish Goel, Mahek Chandak
分类: cs.CL, cs.AI, cs.IR
发布日期: 2024-06-14 (更新: 2024-09-04)
💡 一句话要点
提出HIRO,通过深度优先搜索优化RAG中的层级信息检索,提升性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 检索增强生成 层级信息检索 深度优先搜索 分支剪枝 信息过载
📋 核心要点
- RAG方法在处理层级数据时面临信息过载问题,导致LLM性能下降。
- HIRO采用基于DFS的递归相似度计算和分支剪枝,减少LLM接收的上下文信息量。
- 实验表明,HIRO在NarrativeQA数据集上性能提升了10.85%,验证了其有效性。
📝 摘要(中文)
检索增强生成(RAG)通过将外部知识动态集成到大型语言模型(LLM)中,彻底改变了自然语言处理,解决了LLM静态训练数据集的局限性。最近的RAG实现利用层级数据结构,在不同的摘要级别和信息密度上组织文档。然而,这种复杂性可能导致LLM因信息过载而“窒息”,因此需要更复杂的查询机制。在此背景下,我们引入了层级信息检索优化(HIRO),这是一种新颖的查询方法,它采用基于深度优先搜索(DFS)的递归相似度评分计算和分支剪枝。该方法独特地最小化了传递给LLM的上下文,而不会造成信息丢失,从而有效地管理了数据过多的挑战。HIRO的改进方法通过在NarrativeQA数据集上提高10.85%的性能得到了验证。
🔬 方法详解
问题定义:论文旨在解决检索增强生成(RAG)系统中,当使用层级数据结构时,大型语言模型(LLM)因信息过载而导致的性能下降问题。现有的RAG方法在处理多层级、高信息密度的文档时,容易将大量无关信息传递给LLM,影响其生成质量和效率。
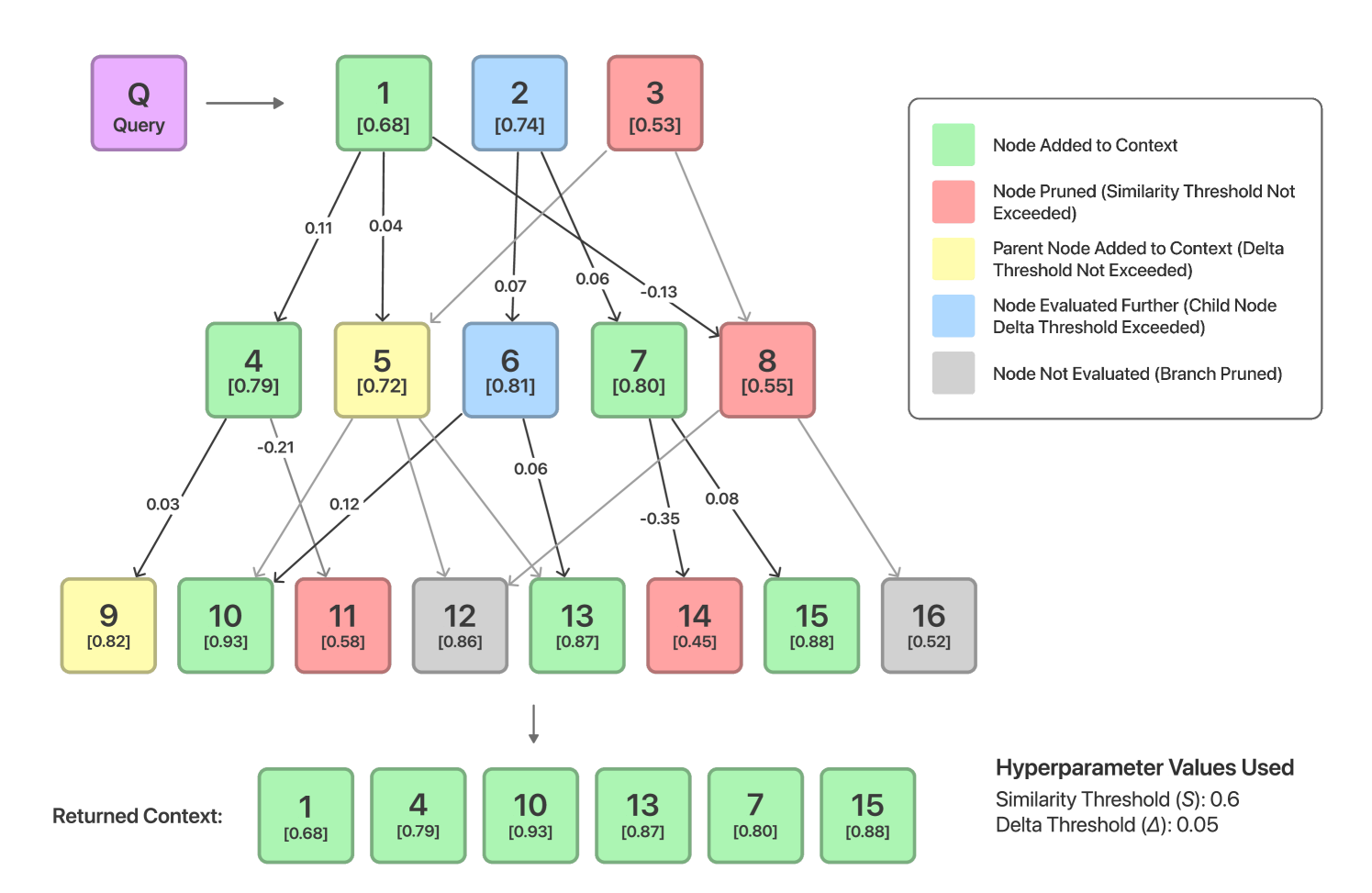
核心思路:HIRO的核心思路是通过一种优化的查询策略,在层级数据结构中选择最相关的上下文信息传递给LLM,从而避免信息过载。该策略基于深度优先搜索(DFS),递归地计算不同层级文档的相似度,并进行分支剪枝,只保留最相关的分支。
技术框架:HIRO的技术框架主要包含以下几个阶段:1) 构建层级数据结构:将文档组织成多层级的结构,例如文档、段落、句子等。2) 深度优先搜索:从根节点开始,使用DFS遍历层级结构。3) 相似度计算:在每个节点,计算查询与该节点文档的相似度得分。4) 分支剪枝:根据相似度得分,剪掉不相关的分支,只保留最相关的路径。5) 上下文传递:将保留路径上的文档作为上下文传递给LLM。
关键创新:HIRO的关键创新在于其基于DFS的递归相似度计算和分支剪枝策略。与传统的RAG方法相比,HIRO能够更有效地选择最相关的上下文信息,避免信息过载,从而提高LLM的性能。此外,HIRO的递归方法能够自适应地处理不同层级的文档,具有更好的灵活性和鲁棒性。
关键设计:HIRO的关键设计包括:1) 相似度度量:可以使用各种相似度度量方法,例如余弦相似度、BM25等。2) 分支剪枝阈值:需要设置一个阈值来决定是否剪掉某个分支。该阈值可以根据具体任务和数据集进行调整。3) 递归深度:需要限制DFS的递归深度,以避免无限循环。4) 上下文长度限制:需要限制传递给LLM的上下文长度,以避免超出LLM的处理能力。
🖼️ 关键图片


📊 实验亮点
HIRO在NarrativeQA数据集上取得了显著的性能提升,相较于基线方法,性能提高了10.85%。这一结果表明,HIRO能够有效地解决RAG系统中信息过载的问题,并提高LLM的生成质量。该实验结果验证了HIRO的有效性和实用性。
🎯 应用场景
HIRO可以应用于各种需要检索增强生成的场景,例如问答系统、文档摘要、知识图谱推理等。该方法尤其适用于处理包含层级结构的数据,例如法律文档、医学报告、新闻文章等。通过优化信息检索过程,HIRO可以提高LLM的生成质量和效率,从而提升用户体验。
📄 摘要(原文)
Retrieval-Augmented Generation (RAG) has revolutionized natural language processing by dynamically integrating external knowledge into Large Language Models (LLMs), addressing their limitation of static training datasets. Recent implementations of RAG leverage hierarchical data structures, which organize documents at various levels of summarization and information density. This complexity, however, can cause LLMs to "choke" on information overload, necessitating more sophisticated querying mechanisms. In this context, we introduce Hierarchical Information Retrieval Optimization (HIRO), a novel querying approach that employs a Depth-First Search (DFS)-based recursive similarity score calculation and branch pruning. This method uniquely minimizes the context delivered to the LLM without informational loss, effectively managing the challenge of excessive data. HIRO's refined approach is validated by a 10.85% improvement in performance on the NarrativeQA dataset.