A Better LLM Evaluator for Text Generation: The Impact of Prompt Output Sequencing and Optimization
作者: KuanChao Chu, Yi-Pei Chen, Hideki Nakayama
分类: cs.CL
发布日期: 2024-06-14
备注: Presented in JSAI 2024. The first two authors contributed equally. arXiv admin note: substantial text overlap with arXiv:2406.02863
DOI: 10.11517/pjsai.JSAI2024.0_2G5GS604
💡 一句话要点
通过优化提示词结构提升LLM在文本生成评估中的性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 文本生成评估 提示词工程 输出指令排序 评分对齐
📋 核心要点
- 现有方法在利用LLM评估文本生成质量时,面临模型敏感性和评估主观性的挑战。
- 本研究通过调整提示词的结构,特别是输出指令的顺序和解释性原因的包含,来优化LLM的评估能力。
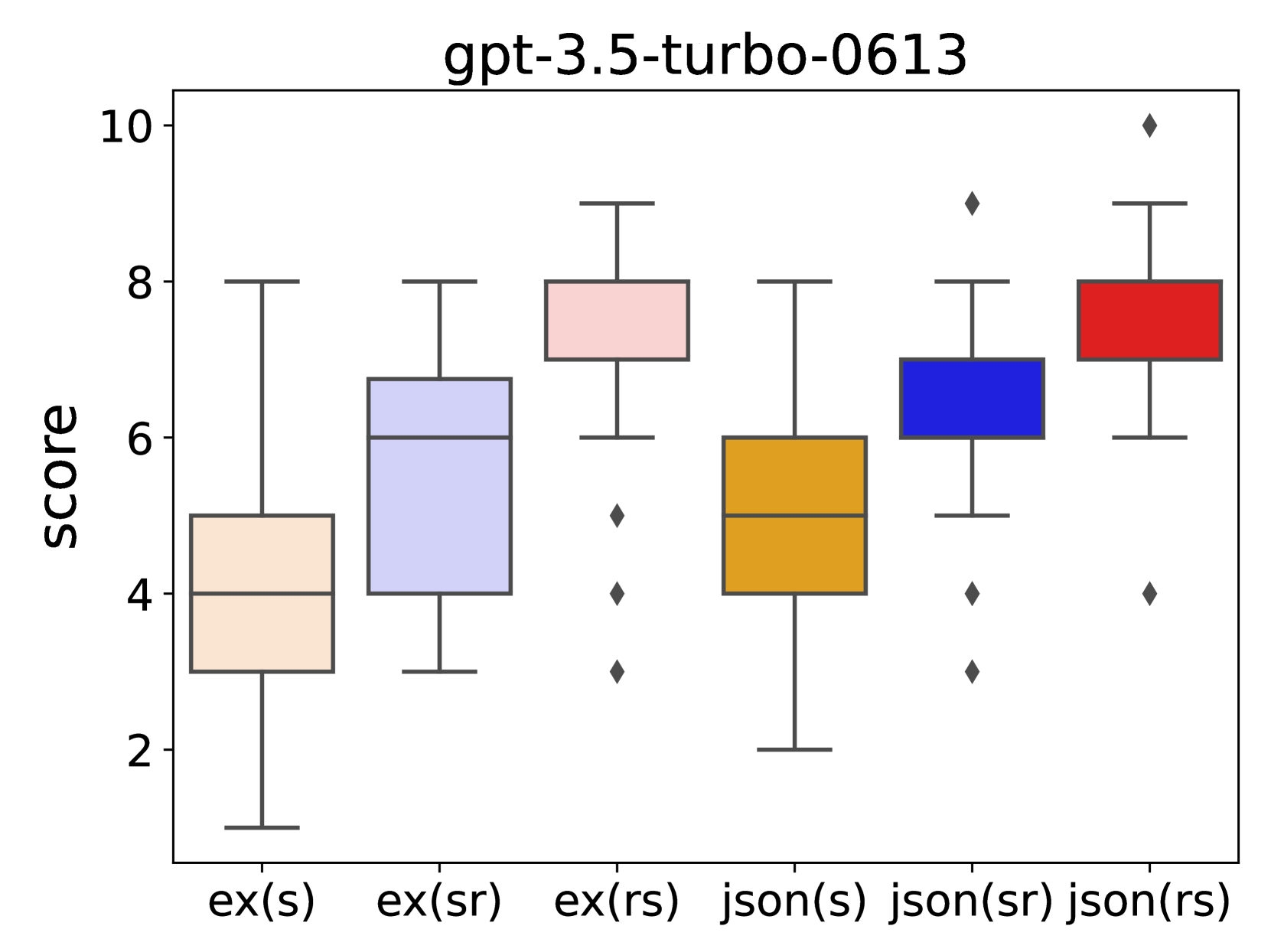
- 实验表明,原因和分数呈现顺序显著影响LLM评分,额外优化在数据充足时可提升评分对齐。
📝 摘要(中文)
本研究探讨了使用大型语言模型(LLM)评估生成文本时,提示词设计的有效性。尽管LLM越来越多地用于对各种输入进行评分,但由于模型敏感性和文本生成评估的主观性,为开放式文本评估创建有效的提示词仍然具有挑战性。我们的研究实验了不同的提示结构,改变了输出指令的顺序,并包含了解释性原因。我们发现,呈现原因和分数的顺序会显著影响LLM的评分,并且在提示中对规则的理解程度也不同。如果数据充足,额外的优化可以增强评分对齐。这一发现对于提高基于LLM的评估的准确性和一致性至关重要。
🔬 方法详解
问题定义:论文旨在解决如何更有效地利用大型语言模型(LLM)来评估文本生成质量的问题。现有方法在设计用于LLM评估的提示词时,常常受到模型敏感性和评估主观性的影响,导致评估结果不稳定且难以解释。因此,如何设计更有效的提示词结构,以提高LLM评估的准确性和一致性,是本研究要解决的核心问题。
核心思路:论文的核心思路是通过优化提示词的结构,特别是输出指令的顺序和解释性原因的包含,来引导LLM进行更准确和一致的评估。研究者认为,合理的提示词结构能够更好地激发LLM的规则理解能力,从而减少主观性和提高评估质量。此外,论文还探索了在数据充足的情况下,通过额外的优化来进一步提升评分对齐的可能性。
技术框架:本研究的技术框架主要围绕提示词工程展开。具体而言,研究者设计并实验了多种不同的提示词结构,这些结构在输出指令的顺序(例如,先给出原因还是先给出分数)以及是否包含解释性原因等方面存在差异。然后,通过对比不同提示词结构下LLM的评估结果,分析其对评估准确性和一致性的影响。如果数据充足,还会进行额外的优化,以进一步提升评分对齐。
关键创新:本研究的关键创新在于发现了提示词结构对LLM评估结果的显著影响,特别是原因和分数呈现顺序的重要性。这一发现颠覆了以往对LLM评估的认知,强调了提示词工程在LLM评估中的关键作用。此外,论文还提出了通过额外优化来提升评分对齐的可能性,为未来的研究提供了新的方向。
关键设计:论文的关键设计包括:1) 设计多种不同的提示词结构,这些结构在输出指令的顺序和解释性原因的包含等方面存在差异;2) 使用不同的LLM模型进行实验,以验证结果的普适性;3) 采用合适的评估指标来衡量LLM评估的准确性和一致性;4) 在数据充足的情况下,探索额外的优化方法,例如微调LLM或使用强化学习等。
🖼️ 关键图片


📊 实验亮点
实验结果表明,原因和分数呈现顺序显著影响LLM评分。例如,先呈现原因的提示词结构通常能够获得更准确的评估结果。此外,在数据充足的情况下,通过额外的优化可以进一步提升评分对齐。这些发现为优化LLM评估提供了重要的指导。
🎯 应用场景
该研究成果可应用于各种文本生成任务的自动评估,例如机器翻译、文本摘要、对话生成等。通过优化提示词结构,可以提高LLM评估的准确性和一致性,从而减少人工评估的需求,降低成本,并加速文本生成系统的开发和迭代。未来,该研究还可以扩展到其他类型的评估任务,例如图像生成评估和代码生成评估。
📄 摘要(原文)
This research investigates prompt designs of evaluating generated texts using large language models (LLMs). While LLMs are increasingly used for scoring various inputs, creating effective prompts for open-ended text evaluation remains challenging due to model sensitivity and subjectivity in evaluation of text generation. Our study experimented with different prompt structures, altering the sequence of output instructions and including explanatory reasons. We found that the order of presenting reasons and scores significantly influences LLMs' scoring, with a different level of rule understanding in the prompt. An additional optimization may enhance scoring alignment if sufficient data is available. This insight is crucial for improving the accuracy and consistency of LLM-based evaluations.