A Training-free Sub-quadratic Cost Transformer Model Serving Framework With Hierarchically Pruned Attention
作者: Heejun Lee, Geon Park, Youngwan Lee, Jaduk Suh, Jina Kim, Wonyoung Jeong, Bumsik Kim, Hyemin Lee, Myeongjae Jeon, Sung Ju Hwang
分类: cs.CL, cs.CV, cs.DC, cs.LG
发布日期: 2024-06-14 (更新: 2025-01-23)
备注: 44 pages
💡 一句话要点
提出HiP:一种无需训练的子二次复杂度Transformer模型服务框架,通过分层剪枝注意力机制实现高效长文本处理。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 长文本处理 Transformer 注意力机制 模型优化 分层剪枝 KV缓存卸载 低资源部署
📋 核心要点
- 现有LLM扩展上下文长度受限于二次复杂度,导致时间和空间成本过高,线性或稀疏注意力机制虽能缓解,但需重新训练且性能下降。
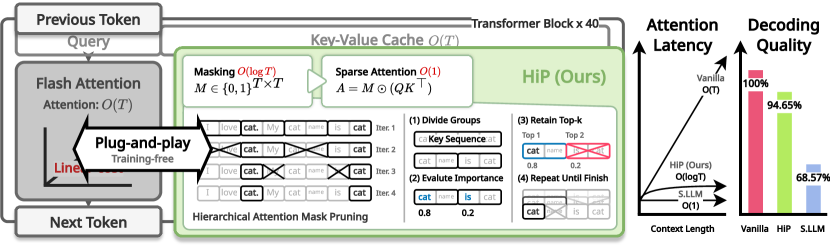
- HiP利用“注意力局部性”特性,通过分层剪枝注意力机制,将时间复杂度降至O(T log T),空间复杂度降至O(T),无需重新训练。
- 实验表明,HiP显著降低了预填充和解码延迟,减少了内存使用,同时保持了高质量的生成效果,使LLM能在普通GPU上处理百万token。
📝 摘要(中文)
现代大型语言模型(LLM)中,增加上下文长度对于提高长文本、多模态和检索增强语言生成中的理解和连贯性至关重要。尽管最近许多Transformer模型试图将上下文长度扩展到数百万个token,但由于二次时间和空间复杂度,它们仍然不实用。虽然最近关于线性和稀疏注意力机制的工作可以实现这一目标,但它们的实际应用往往受到需要从头开始重新训练和性能显著下降的限制。为此,我们提出了一种新颖的方法,即分层剪枝注意力(HiP),它将注意力机制的时间复杂度降低到O(T log T),空间复杂度降低到O(T),其中T是序列长度。我们注意到预训练LLM的注意力分数中存在一种模式,即彼此靠近的token往往具有相似的分数,我们称之为“注意力局部性”。基于这一观察,我们利用一种新颖的类似树搜索的算法,动态地估计给定查询的前k个关键token,这在数学上保证了比随机注意力剪枝更好的性能。除了提高注意力机制的时间复杂度外,我们还通过实现KV缓存卸载来进一步优化GPU内存使用,该卸载仅在GPU上存储O(log T)个token,同时保持相似的解码吞吐量。基准测试表明,HiP具有无需训练的特性,可显著减少预填充和解码延迟以及内存使用,同时保持高质量的生成效果,且性能下降极小。HiP使预训练的LLM能够在商品GPU上扩展到数百万个token,从而可能解锁以前认为不可行的长文本LLM应用。
🔬 方法详解
问题定义:现有大型语言模型在处理长文本时,由于Transformer的注意力机制的二次方复杂度,导致计算和内存开销巨大,限制了其在长上下文场景下的应用。即使采用线性或稀疏注意力机制,也往往需要从头开始重新训练模型,并且性能会显著下降。因此,如何在不重新训练模型的前提下,降低注意力机制的复杂度,成为一个亟待解决的问题。
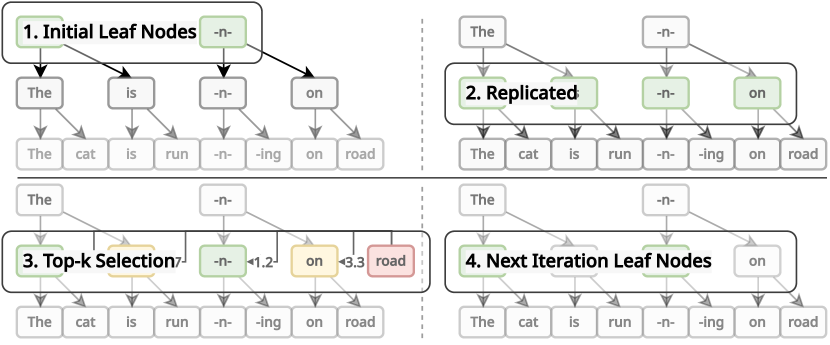
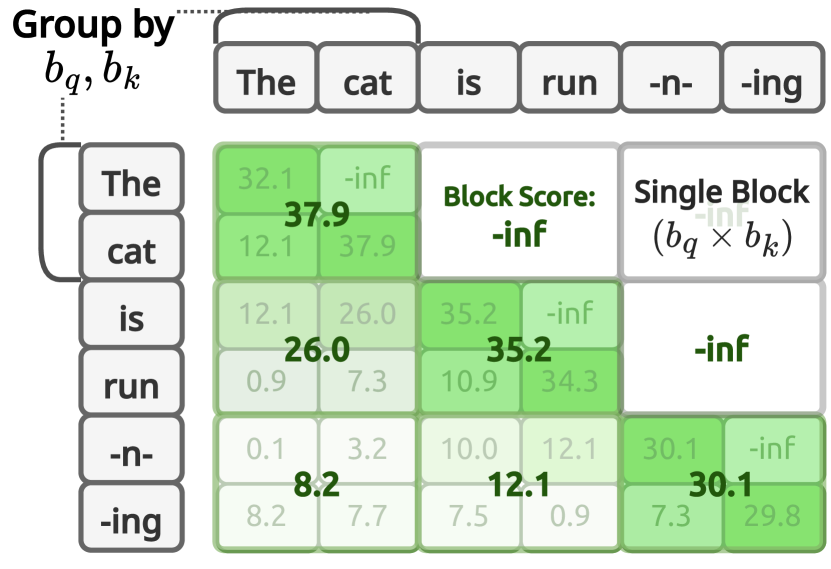
核心思路:论文的核心思路是利用预训练语言模型中存在的“注意力局部性”现象,即相邻token之间的注意力分数往往相似。基于此,设计一种分层剪枝注意力机制(HiP),通过类似树搜索的算法,快速找到每个query token最重要的key token,从而减少需要计算的注意力权重数量。这种方法无需重新训练模型,并且在数学上保证了比随机剪枝更好的性能。
技术框架:HiP框架主要包含两个核心部分:分层剪枝注意力机制和KV缓存卸载。分层剪枝注意力机制首先构建一个token的层次结构,然后使用类似树搜索的算法,快速找到每个query token最重要的key token。KV缓存卸载则将大部分KV缓存存储在CPU内存中,只在GPU上保留少量必要的token,从而减少GPU内存的使用。整体流程包括:输入序列 -> 分层剪枝注意力计算 -> 输出序列。
关键创新:HiP的关键创新在于其分层剪枝注意力机制,它利用了预训练语言模型中存在的“注意力局部性”现象,通过类似树搜索的算法,动态地选择每个query token最重要的key token。与传统的注意力机制相比,HiP的时间复杂度从O(T^2)降低到O(T log T),空间复杂度从O(T^2)降低到O(T)。与现有的稀疏注意力机制相比,HiP无需重新训练模型,并且在数学上保证了更好的性能。
关键设计:HiP的关键设计包括:1) 层次结构的构建方式,例如可以使用k-means聚类等算法将token分组;2) 树搜索算法的具体实现,例如可以使用二分查找等算法快速找到top-k个key token;3) KV缓存卸载的策略,例如可以根据token的重要性程度决定是否将其存储在GPU内存中。论文中并没有给出具体的参数设置、损失函数或网络结构,因为HiP是一种通用的注意力机制优化方法,可以应用于各种Transformer模型。
🖼️ 关键图片
📊 实验亮点
实验结果表明,HiP在保持高质量生成效果的同时,显著降低了预填充和解码延迟以及内存使用。具体来说,HiP使得预训练的LLM能够在商品GPU上扩展到数百万个token,而性能下降极小。与基线方法相比,HiP在处理长文本时,能够实现显著的加速和内存节省。
🎯 应用场景
HiP具有广泛的应用前景,尤其是在需要处理长文本的场景中,例如长篇文档摘要、机器翻译、对话生成、代码生成等。通过降低计算和内存开销,HiP使得在资源有限的设备上运行大型语言模型成为可能,从而可以应用于移动设备、嵌入式系统等。此外,HiP还可以用于加速模型的训练过程,提高训练效率。
📄 摘要(原文)
In modern large language models (LLMs), increasing the context length is crucial for improving comprehension and coherence in long-context, multi-modal, and retrieval-augmented language generation. While many recent transformer models attempt to extend their context length over a million tokens, they remain impractical due to the quadratic time and space complexities. Although recent works on linear and sparse attention mechanisms can achieve this goal, their real-world applicability is often limited by the need to re-train from scratch and significantly worse performance. In response, we propose a novel approach, Hierarchically Pruned Attention (HiP), which reduces the time complexity of the attention mechanism to $O(T \log T)$ and the space complexity to $O(T)$, where $T$ is the sequence length. We notice a pattern in the attention scores of pretrained LLMs where tokens close together tend to have similar scores, which we call ``attention locality''. Based on this observation, we utilize a novel tree-search-like algorithm that estimates the top-$k$ key tokens for a given query on the fly, which is mathematically guaranteed to have better performance than random attention pruning. In addition to improving the time complexity of the attention mechanism, we further optimize GPU memory usage by implementing KV cache offloading, which stores only $O(\log T)$ tokens on the GPU while maintaining similar decoding throughput. Experiments on benchmarks show that HiP, with its training-free nature, significantly reduces both prefill and decoding latencies, as well as memory usage, while maintaining high-quality generation with minimal degradation. HiP enables pretrained LLMs to scale up to millions of tokens on commodity GPUs, potentially unlocking long-context LLM applications previously deemed infeasible.