Retrieval Augmented Fact Verification by Synthesizing Contrastive Arguments
作者: Zhenrui Yue, Huimin Zeng, Lanyu Shang, Yifan Liu, Yang Zhang, Dong Wang
分类: cs.CL, cs.AI
发布日期: 2024-06-14
备注: Accepted to ACL 2024
💡 一句话要点
提出RAFTS:通过合成对比论证进行检索增强的事实核查
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 事实核查 检索增强 对比论证 大型语言模型 自然语言处理
📋 核心要点
- 现有事实核查方法依赖LLM内部知识或黑盒API,在小模型或不可靠上下文中表现欠佳。
- RAFTS通过检索相关证据,合成支持和反驳的对比论证,进行细粒度决策。
- 实验表明,RAFTS在不使用复杂提示的情况下,显著优于监督和LLM基线方法。
📝 摘要(中文)
错误信息的快速传播对公共利益构成重大风险。为了对抗错误信息,大型语言模型(LLMs)被用于自动验证声明的可信度。然而,现有方法严重依赖于LLMs内部的嵌入知识和/或黑盒API进行证据收集,导致较小的LLMs或在不可靠的上下文中表现不佳。本文提出了一种通过合成对比论证进行检索增强的事实核查方法(RAFTS)。对于输入的声明,RAFTS首先进行证据检索,我们设计了一个检索流程来收集和重新排序来自可验证来源的相关文档。然后,RAFTS根据检索到的证据形成对比论证(即支持或反驳)。此外,RAFTS利用嵌入模型来识别信息丰富的演示,然后通过上下文提示生成预测和解释。我们的方法有效地检索相关文档作为证据,并从不同的角度评估论证,从而整合细微的信息以进行细粒度的决策。结合信息丰富的上下文示例作为先验,RAFTS在没有复杂提示的情况下,对监督和LLM基线实现了显著改进。通过大量的实验,我们证明了该方法的有效性,RAFTS可以使用一个更小的7B LLM优于基于GPT的方法。
🔬 方法详解
问题定义:现有事实核查方法依赖于大型语言模型(LLMs)内部的知识或黑盒API进行证据收集,这限制了它们在资源受限环境(例如,使用较小的LLMs)或面对不可靠上下文时的性能。这些方法缺乏透明性和可解释性,难以理解模型做出判断的依据。因此,需要一种更有效、更可靠、更透明的事实核查方法。
核心思路:RAFTS的核心思路是通过检索外部知识来增强事实核查过程,并利用对比论证来提高决策的准确性和可解释性。通过检索相关文档,RAFTS能够获取更全面的证据,避免过度依赖LLM内部的知识。合成对比论证(支持和反驳)允许模型从多个角度评估声明,从而做出更细致的判断。
技术框架:RAFTS包含以下几个主要阶段:1) 证据检索:设计检索流程,从可信来源收集并重新排序相关文档。2) 对比论证合成:根据检索到的证据,生成支持和反驳声明的论证。3) 上下文提示:利用嵌入模型识别信息丰富的示例,并通过上下文提示指导LLM生成预测和解释。整体流程是先检索证据,然后基于证据生成对比论证,最后利用上下文学习进行预测和解释。
关键创新:RAFTS的关键创新在于对比论证的合成。与传统的仅依赖支持性证据的方法不同,RAFTS同时考虑支持和反驳的证据,从而更全面地评估声明的真实性。此外,RAFTS通过检索外部知识来增强LLM的能力,使其能够在资源受限的环境中表现良好。
关键设计:在证据检索阶段,使用了特定的检索模型和排序算法来提高检索的准确性。在对比论证合成阶段,使用了特定的提示工程技术来指导LLM生成高质量的论证。在上下文提示阶段,使用了嵌入模型来选择信息丰富的示例,以提高LLM的预测准确性。具体的参数设置和损失函数等细节在论文中进行了详细描述(未知)。
🖼️ 关键图片
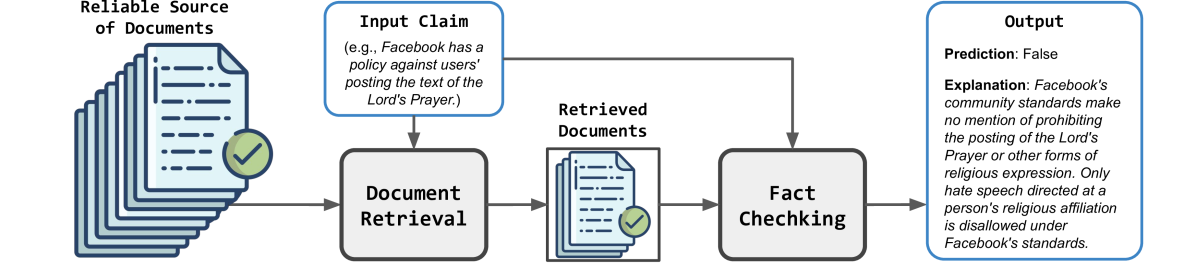

📊 实验亮点
实验结果表明,RAFTS在事实核查任务上取得了显著的性能提升。具体而言,RAFTS使用一个更小的7B LLM,其性能优于基于GPT的方法。该方法在不使用复杂提示的情况下,对监督和LLM基线实现了显著改进。这些结果表明,RAFTS是一种有效且高效的事实核查方法。
🎯 应用场景
该研究成果可应用于新闻媒体、社交平台等领域,用于自动检测和识别虚假信息,提高信息的可信度。该方法还可以用于教育领域,帮助学生批判性地评估信息来源,培养独立思考能力。未来,该方法可以扩展到其他领域,例如医疗诊断、金融风险评估等,以提高决策的准确性和可靠性。
📄 摘要(原文)
The rapid propagation of misinformation poses substantial risks to public interest. To combat misinformation, large language models (LLMs) are adapted to automatically verify claim credibility. Nevertheless, existing methods heavily rely on the embedded knowledge within LLMs and / or black-box APIs for evidence collection, leading to subpar performance with smaller LLMs or upon unreliable context. In this paper, we propose retrieval augmented fact verification through the synthesis of contrasting arguments (RAFTS). Upon input claims, RAFTS starts with evidence retrieval, where we design a retrieval pipeline to collect and re-rank relevant documents from verifiable sources. Then, RAFTS forms contrastive arguments (i.e., supporting or refuting) conditioned on the retrieved evidence. In addition, RAFTS leverages an embedding model to identify informative demonstrations, followed by in-context prompting to generate the prediction and explanation. Our method effectively retrieves relevant documents as evidence and evaluates arguments from varying perspectives, incorporating nuanced information for fine-grained decision-making. Combined with informative in-context examples as prior, RAFTS achieves significant improvements to supervised and LLM baselines without complex prompts. We demonstrate the effectiveness of our method through extensive experiments, where RAFTS can outperform GPT-based methods with a significantly smaller 7B LLM.