FreeCtrl: Constructing Control Centers with Feedforward Layers for Learning-Free Controllable Text Generation
作者: Zijian Feng, Hanzhang Zhou, Zixiao Zhu, Kezhi Mao
分类: cs.CL
发布日期: 2024-06-14
备注: ACL 2024
💡 一句话要点
FreeCtrl:通过前馈层构建控制中心,实现免学习的可控文本生成
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 可控文本生成 免学习 前馈神经网络 大型语言模型 属性控制
📋 核心要点
- 现有可控文本生成方法依赖大量数据和计算资源进行训练或微调,成本高昂。
- FreeCtrl通过动态调整FFN向量权重来控制LLM输出,无需额外学习过程。
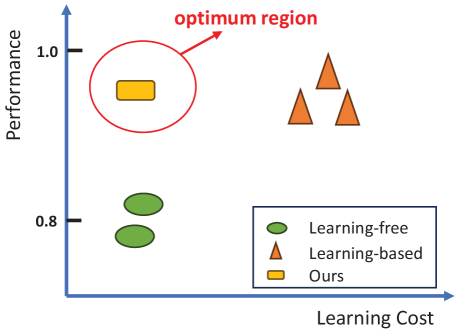
- 实验表明,FreeCtrl在单属性和多属性控制上优于其他免学习和基于学习的方法。
📝 摘要(中文)
可控文本生成(CTG)旨在生成符合特定属性的文本,传统方法通常采用基于学习的技术,如训练、微调或使用特定属性数据集进行前缀调整。这些方法虽然有效,但需要大量的计算和数据资源。相比之下,一些提出的免学习替代方案虽然避免了学习过程,但通常会产生较差的结果,体现了机器学习中计算成本和模型效果之间的基本权衡。为了克服这些限制,我们提出了FreeCtrl,一种免学习方法,它动态调整选定的前馈神经网络(FFN)向量的权重,以引导大型语言模型(LLM)的输出。FreeCtrl基于以下原则:不同FFN向量的权重会影响输出中不同token出现的可能性。通过识别和自适应地调整与属性相关的FFN向量的权重,FreeCtrl可以控制生成内容中属性关键词的输出可能性。在单属性和多属性控制方面的大量实验表明,免学习的FreeCtrl优于其他免学习和基于学习的方法,成功地解决了学习成本和模型性能之间的困境。
🔬 方法详解
问题定义:可控文本生成旨在生成具有特定属性的文本。现有方法,如微调和前缀调整,需要大量特定属性的数据集和计算资源。免学习方法虽然避免了这些成本,但通常牺牲了生成质量和控制精度。因此,如何在不进行额外学习的情况下,实现高质量的可控文本生成是一个挑战。
核心思路:FreeCtrl的核心思想是利用大型语言模型(LLM)中前馈神经网络(FFN)层的内在属性控制能力。它假设不同的FFN向量对不同token的生成概率有不同的影响。通过识别并调整与目标属性相关的FFN向量的权重,可以有效地控制生成文本中特定关键词的出现概率,从而实现属性控制。
技术框架:FreeCtrl的整体框架包括以下几个步骤:1) 属性关键词识别:确定与目标属性相关的关键词。2) FFN向量选择:识别对这些关键词影响最大的FFN向量。这可以通过分析不同FFN向量权重变化对关键词生成概率的影响来实现。3) 权重调整:根据目标属性,自适应地调整所选FFN向量的权重。正向调整增加关键词的生成概率,负向调整则降低其生成概率。4) 文本生成:使用调整后的LLM生成文本。
关键创新:FreeCtrl的关键创新在于它是一种完全免学习的方法,无需任何训练或微调。它直接利用了LLM中FFN层的固有属性控制能力,通过动态调整权重来实现可控文本生成。与现有方法相比,FreeCtrl显著降低了计算和数据成本,同时保持了较高的生成质量和控制精度。
关键设计:FreeCtrl的关键设计包括:1) FFN向量选择策略:论文可能采用某种策略来选择对目标属性影响最大的FFN向量,例如基于梯度或注意力机制。2) 权重调整策略:论文可能设计了一种自适应的权重调整策略,根据目标属性和当前生成状态动态调整FFN向量的权重。具体的参数设置、损失函数和网络结构等技术细节未知,需要查阅原始论文。
🖼️ 关键图片


📊 实验亮点
FreeCtrl在单属性和多属性控制任务上均表现出色,超越了其他免学习和基于学习的方法。具体性能数据未知,但摘要强调其成功解决了学习成本和模型性能之间的权衡问题,表明其在效率和效果上都具有显著优势。
🎯 应用场景
FreeCtrl可应用于多种场景,如个性化内容生成、风格迁移、情感控制等。例如,可以用于生成具有特定情感色彩的新闻报道、符合特定风格的文学作品,或针对特定用户群体定制的广告文案。该研究降低了可控文本生成的门槛,使得在资源有限的情况下也能实现高质量的文本控制。
📄 摘要(原文)
Controllable text generation (CTG) seeks to craft texts adhering to specific attributes, traditionally employing learning-based techniques such as training, fine-tuning, or prefix-tuning with attribute-specific datasets. These approaches, while effective, demand extensive computational and data resources. In contrast, some proposed learning-free alternatives circumvent learning but often yield inferior results, exemplifying the fundamental machine learning trade-off between computational expense and model efficacy. To overcome these limitations, we propose FreeCtrl, a learning-free approach that dynamically adjusts the weights of selected feedforward neural network (FFN) vectors to steer the outputs of large language models (LLMs). FreeCtrl hinges on the principle that the weights of different FFN vectors influence the likelihood of different tokens appearing in the output. By identifying and adaptively adjusting the weights of attribute-related FFN vectors, FreeCtrl can control the output likelihood of attribute keywords in the generated content. Extensive experiments on single- and multi-attribute control reveal that the learning-free FreeCtrl outperforms other learning-free and learning-based methods, successfully resolving the dilemma between learning costs and model performance.