Multi-Modal Retrieval For Large Language Model Based Speech Recognition
作者: Jari Kolehmainen, Aditya Gourav, Prashanth Gurunath Shivakumar, Yile Gu, Ankur Gandhe, Ariya Rastrow, Grant Strimel, Ivan Bulyko
分类: cs.CL, cs.AI, cs.IR, cs.SD, eess.AS
发布日期: 2024-06-13
💡 一句话要点
提出多模态检索方法,提升基于大语言模型的语音识别性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态检索 语音识别 大语言模型 kNN-LM 交叉注意力 Spoken-Squad 信息融合
📋 核心要点
- 现有语言模型依赖外部信息的方法主要基于文本,无法有效利用其他模态信息。
- 本文提出多模态检索方法,通过kNN-LM和交叉注意力机制,融合语音和其他模态信息。
- 实验表明,该方法在语音识别任务中显著优于文本检索,并在Spoken-Squad数据集上取得SOTA结果。
📝 摘要(中文)
本文提出了一种多模态检索方法,旨在利用外部信息增强大语言模型在语音识别任务中的表现。该方法包含两种实现方式:k近邻语言模型(kNN-LM)和交叉注意力机制。实验结果表明,基于语音的多模态检索优于基于文本的检索,并且在多模态语言模型基线之上,词错误率(WER)最多可降低50%。此外,在Spoken-Squad问答数据集上,该方法取得了当前最佳的识别效果。
🔬 方法详解
问题定义:现有基于大语言模型的语音识别方法,在利用外部信息时,主要集中于文本模态。然而,在许多实际应用场景中,存在其他模态的信息(例如图像、视频等),这些信息可以为语音识别提供额外的上下文线索。因此,如何有效地利用多模态信息来提升语音识别的性能是一个关键问题。现有方法无法充分利用这些非文本模态的信息,导致识别精度受限。
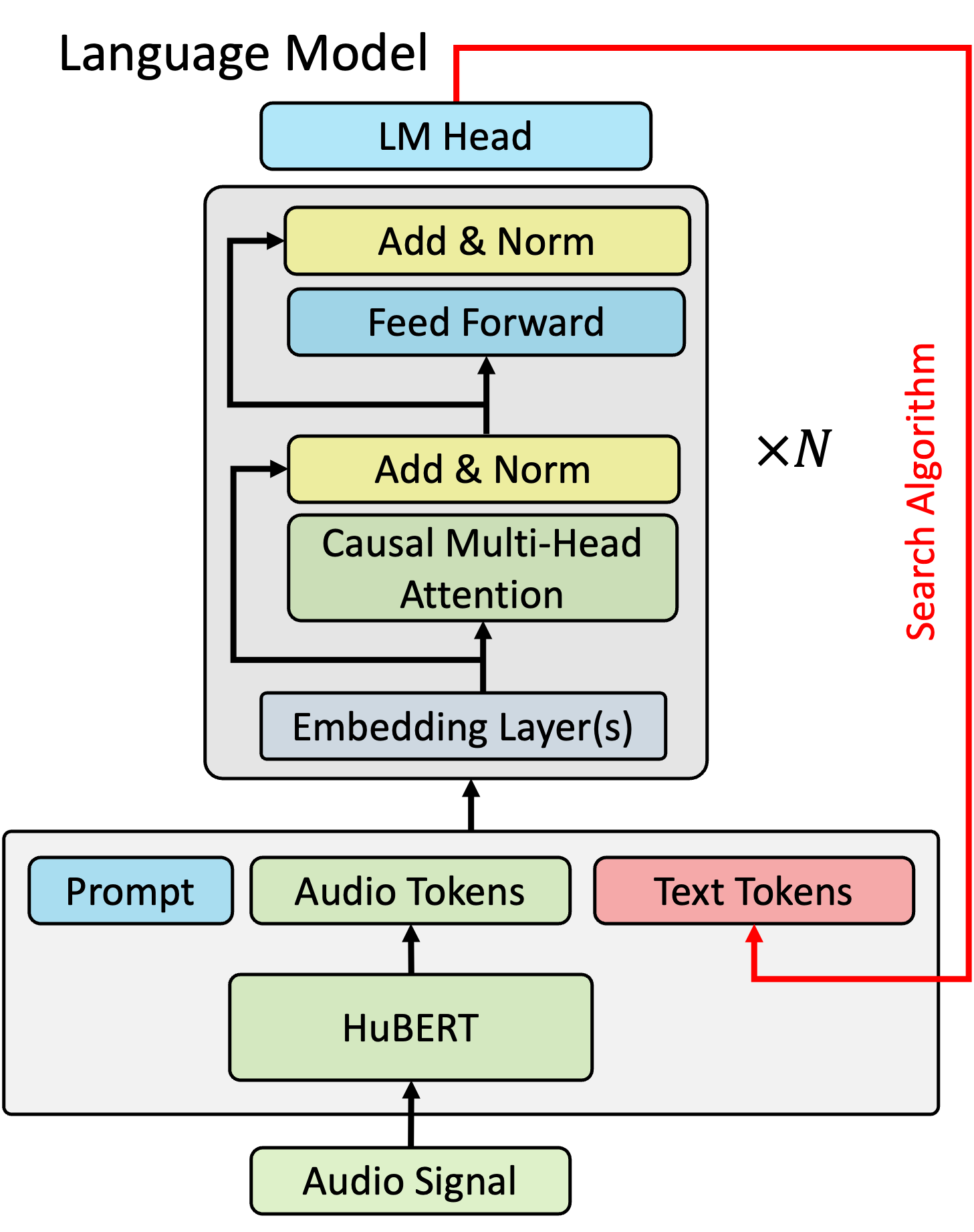
核心思路:本文的核心思路是引入多模态检索机制,允许模型在检索外部信息时,不仅考虑文本信息,还考虑语音信息。通过将语音信息纳入检索过程,模型可以更准确地找到与当前语音输入相关的外部知识,从而提升语音识别的准确性。这种方法的核心在于构建一个能够同时处理多种模态信息的检索系统。
技术框架:该方法包含两个主要的技术框架:kNN-LM和交叉注意力机制。在kNN-LM框架中,模型首先根据语音特征检索最相关的k个外部信息片段,然后利用这些片段来调整语言模型的预测。在交叉注意力机制中,模型通过注意力机制将语音特征与外部信息进行融合,从而更好地利用外部信息。整体流程包括:语音特征提取、多模态信息检索、信息融合和语音识别。
关键创新:该方法最重要的技术创新点在于将语音信息纳入了检索过程,实现了真正的多模态检索。与传统的基于文本的检索方法相比,该方法能够更准确地找到与当前语音输入相关的外部知识。此外,该方法还提出了两种不同的多模态信息融合方式:kNN-LM和交叉注意力机制,为多模态信息的利用提供了更多的选择。
关键设计:在kNN-LM中,需要选择合适的距离度量方法来衡量语音特征之间的相似度。在交叉注意力机制中,需要设计合适的注意力网络结构来融合语音特征和外部信息。具体的参数设置和网络结构的选择需要根据具体的任务和数据集进行调整。损失函数通常采用交叉熵损失函数,用于优化语音识别模型的参数。
🖼️ 关键图片


📊 实验亮点
实验结果表明,基于语音的多模态检索方法显著优于基于文本的检索方法,词错误率(WER)最多可降低50%。在Spoken-Squad问答数据集上,该方法取得了当前最佳的识别效果,证明了其在实际应用中的有效性。这些结果表明,多模态检索是提升语音识别性能的有效途径。
🎯 应用场景
该研究成果可广泛应用于智能语音助手、语音搜索、语音翻译等领域。通过引入多模态检索,可以提升这些应用在复杂场景下的识别准确率和用户体验。未来,该技术还可以扩展到其他多模态任务中,例如视频字幕生成、多模态对话系统等,具有广阔的应用前景。
📄 摘要(原文)
Retrieval is a widely adopted approach for improving language models leveraging external information. As the field moves towards multi-modal large language models, it is important to extend the pure text based methods to incorporate other modalities in retrieval as well for applications across the wide spectrum of machine learning tasks and data types. In this work, we propose multi-modal retrieval with two approaches: kNN-LM and cross-attention techniques. We demonstrate the effectiveness of our retrieval approaches empirically by applying them to automatic speech recognition tasks with access to external information. Under this setting, we show that speech-based multi-modal retrieval outperforms text based retrieval, and yields up to 50 % improvement in word error rate over the multi-modal language model baseline. Furthermore, we achieve state-of-the-art recognition results on the Spoken-Squad question answering dataset.