Sharing Matters: Analysing Neurons Across Languages and Tasks in LLMs
作者: Weixuan Wang, Barry Haddow, Minghao Wu, Wei Peng, Alexandra Birch
分类: cs.CL
发布日期: 2024-06-13 (更新: 2025-09-26)
💡 一句话要点
分析LLM跨语言和任务的神经元共享模式,揭示多语言模型内部机制
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多语言LLM 神经元分析 跨语言知识共享 模型可解释性 消融实验
📋 核心要点
- 现有研究主要集中在单语LLM上,缺乏对多语言LLM内部机制的深入理解,限制了模型优化和跨语言应用。
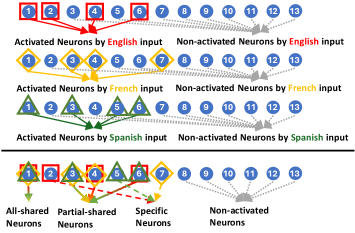
- 该研究通过分析神经元在不同语言和任务中的激活模式,将神经元分为四种类型,从而揭示LLM的跨语言知识共享。
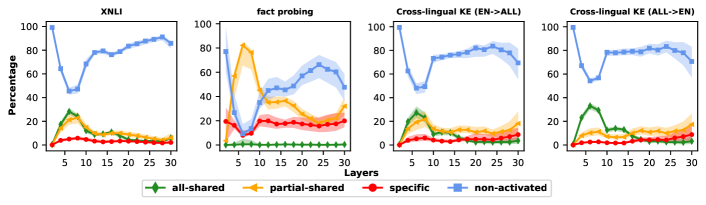
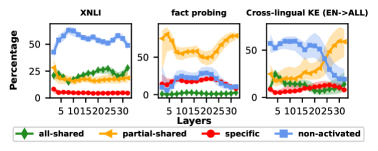
- 实验结果表明,共享神经元对LLM性能至关重要,尤其全共享神经元,且神经元激活模式对任务、模型和语言敏感。
📝 摘要(中文)
大型语言模型(LLMs)彻底改变了自然语言处理(NLP)领域,近期的研究致力于理解其底层机制。然而,大多数研究主要在单语环境下进行,尤其侧重于英语。鲜有研究尝试探索LLMs在多语言环境下的内部运作。本研究旨在填补这一空白,通过检验神经元激活如何在任务和语言之间共享,来分析多语言LLM。我们基于神经元对不同语言输入的响应,将其分为四类:全共享、部分共享、特定和非激活。在此基础上,我们使用多个LLM,在九种语言的三个任务上进行了广泛的实验,并进行了深入分析。我们的发现表明:(i)停用全共享神经元会显著降低性能;(ii)共享神经元在生成响应中起着至关重要的作用,尤其是全共享神经元;(iii)神经元激活模式高度敏感,并且因任务、LLM和语言而异。这些发现揭示了多语言LLM的内部运作机制,并为未来的研究铺平了道路。我们发布了代码,以促进该领域的研究。
🔬 方法详解
问题定义:现有研究对大型语言模型(LLM)的理解主要集中在单语环境,特别是英语。对于多语言LLM,我们对其内部神经元如何在不同语言和任务之间共享信息知之甚少。这阻碍了我们更好地理解和优化多语言LLM,也限制了其在跨语言场景中的应用。因此,本研究旨在深入探究多语言LLM中神经元的共享模式,从而揭示其内部运作机制。
核心思路:本研究的核心思路是通过分析LLM中神经元对不同语言和任务输入的激活响应,来识别和分类神经元。根据神经元在不同语言输入下的激活情况,将其分为全共享、部分共享、特定和非激活四种类型。通过分析这些不同类型神经元在模型性能中的作用,以及它们对不同任务和语言的敏感性,从而揭示LLM的跨语言知识表示和共享机制。
技术框架:该研究的技术框架主要包括以下几个步骤:1) 选择多个LLM和多种语言;2) 设计多个NLP任务;3) 对LLM输入不同语言的相同任务数据,记录每个神经元的激活值;4) 基于神经元对不同语言输入的激活响应,将其分为四类:全共享、部分共享、特定和非激活;5) 通过消融实验(deactivation),评估不同类型神经元对模型性能的影响;6) 分析神经元激活模式在不同任务、LLM和语言之间的差异。
关键创新:本研究的关键创新在于提出了一个系统性的方法来分析多语言LLM中神经元的共享模式。通过将神经元分为四种类型,并分析它们在模型性能中的作用,从而揭示了LLM的跨语言知识表示和共享机制。此外,该研究还发现神经元激活模式对任务、模型和语言高度敏感,这为未来的研究提供了重要的启示。
关键设计:在实验设计方面,该研究选择了多个LLM(具体模型未知)和九种语言(具体语言未知),并在三个不同的NLP任务(具体任务未知)上进行了实验。为了评估不同类型神经元的作用,研究人员采用了消融实验,即通过停用特定类型的神经元,观察模型性能的变化。具体的消融方法和性能评估指标未知。
🖼️ 关键图片
📊 实验亮点
实验结果表明,停用全共享神经元会导致LLM性能显著下降,这突显了共享神经元在生成响应中的关键作用。研究还发现,神经元激活模式对任务、LLM和语言高度敏感,表明LLM内部的知识表示方式复杂且多样。具体的性能下降幅度和其他量化指标未知。
🎯 应用场景
该研究成果可应用于多语言LLM的优化和改进,例如,通过增强共享神经元的训练,提高模型在跨语言任务上的性能。此外,该研究还可以帮助我们更好地理解LLM的内部运作机制,为开发更高效、更通用的自然语言处理模型提供理论指导。未来,该研究或可用于开发更具语言迁移能力的模型,减少对大规模多语言数据的依赖。
📄 摘要(原文)
Large language models (LLMs) have revolutionized the field of natural language processing (NLP), and recent studies have aimed to understand their underlying mechanisms. However, most of this research is conducted within a monolingual setting, primarily focusing on English. Few studies have attempted to explore the internal workings of LLMs in multilingual settings. In this study, we aim to fill this research gap by examining how neuron activation is shared across tasks and languages. We classify neurons into four distinct categories based on their responses to a specific input across different languages: all-shared, partial-shared, specific, and non-activated. Building upon this categorisation, we conduct extensive experiments on three tasks across nine languages using several LLMs and present an in-depth analysis in this work. Our findings reveal that: (i) deactivating the all-shared neurons significantly decreases performance; (ii) the shared neurons play a vital role in generating responses, especially for the all-shared neurons; (iii) neuron activation patterns are highly sensitive and vary across tasks, LLMs, and languages. These findings shed light on the internal workings of multilingual LLMs and pave the way for future research. We release the code to foster research in this area.