DefAn: Definitive Answer Dataset for LLMs Hallucination Evaluation
作者: A B M Ashikur Rahman, Saeed Anwar, Muhammad Usman, Ajmal Mian
分类: cs.CL, cs.AI, cs.CV, cs.LG
发布日期: 2024-06-13
🔗 代码/项目: GITHUB
💡 一句话要点
DefAn:用于评估大型语言模型幻觉的权威答案数据集
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 幻觉评估 基准数据集 事实性 一致性
📋 核心要点
- 大型语言模型存在幻觉问题,即生成与事实不符或不一致的内容,严重影响其可靠性。
- 论文构建了一个包含75,000多个提示的DefAn数据集,旨在全面评估LLM在多个领域的幻觉程度。
- 实验结果表明,现有LLM在事实性、提示对齐和一致性方面存在显著缺陷,突显了数据集的价值。
📝 摘要(中文)
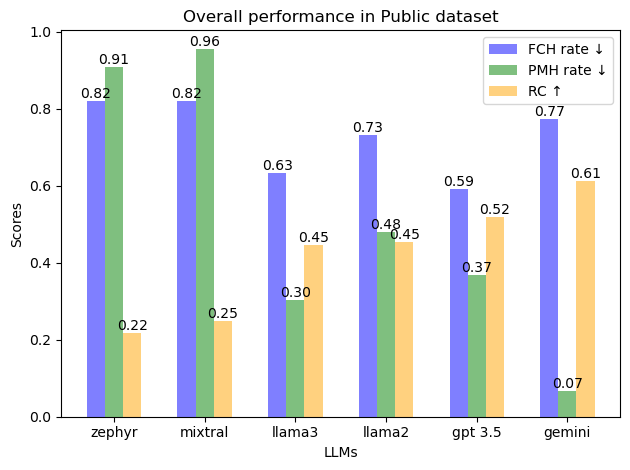
大型语言模型(LLMs)展现了卓越的能力,彻底改变了人工智能在日常生活应用中的集成。然而,它们容易产生幻觉,生成与既定事实相悖的声明,偏离提示,并在多次呈现相同提示时产生不一致的响应。由于缺乏全面且易于评估的基准数据集,解决这些问题具有挑战性。大多数现有数据集都很小,并且依赖于多项选择题,这不足以评估LLM的生成能力。为了衡量LLM中的幻觉,本文介绍了一个全面的基准数据集,包含跨八个领域的超过75,000个提示。这些提示旨在引出明确、简洁和信息丰富的答案。该数据集分为两个部分:一个公开可用,用于测试和评估LLM性能;一个隐藏部分,用于对各种LLM进行基准测试。在我们的实验中,我们测试了六个LLM——GPT-3.5、Llama 2、Llama 3、Gemini、Mixtral和Zephyr——结果表明,在公共数据集上,总体事实幻觉范围为59%到82%,在隐藏基准中为57%到76%。提示未对齐幻觉在公共数据集中为6%到95%,在隐藏数据集中为17%到94%。平均一致性分别在21%到61%和22%到63%之间。领域分析表明,当要求提供特定的数字信息时,LLM的性能会显著下降,而在处理人物、地点和日期查询时,性能表现尚可。我们的数据集证明了其有效性,并作为LLM性能评估的全面基准。
🔬 方法详解
问题定义:大型语言模型(LLMs)在生成文本时容易出现“幻觉”现象,即生成不真实、不一致或与输入提示不符的内容。现有评估LLM幻觉的数据集通常规模较小,形式单一(如多项选择),难以全面评估LLM的生成能力。因此,需要一个更大、更全面的数据集来准确衡量和诊断LLM的幻觉问题。
核心思路:论文的核心思路是构建一个名为DefAn(Definitive Answer)的大规模数据集,该数据集包含超过75,000个提示,覆盖八个不同的领域。这些提示被设计成能够引出明确、简洁和信息丰富的答案,从而更容易判断LLM生成的答案是否真实、一致和符合提示。通过分析LLM在DefAn数据集上的表现,可以更准确地评估其幻觉程度。
技术框架:DefAn数据集分为两个部分:公开部分和隐藏部分。公开部分用于测试和评估LLM的性能,研究人员可以利用它来开发和改进LLM的幻觉检测和缓解方法。隐藏部分则用于对不同的LLM进行基准测试,以比较它们的性能并跟踪LLM幻觉问题的进展。数据集的构建过程包括提示的设计、答案的收集和验证等步骤。
关键创新:DefAn数据集的关键创新在于其规模和全面性。与现有数据集相比,DefAn包含更多的提示和更广泛的领域,能够更全面地评估LLM的幻觉程度。此外,DefAn数据集的设计侧重于引出明确的答案,使得评估过程更加客观和准确。
关键设计:DefAn数据集的提示设计考虑了多个因素,包括领域的多样性、问题的难度和答案的明确性。为了确保答案的质量,论文作者采用了多种验证方法,包括人工审核和自动验证。此外,论文还定义了多种评估指标,如事实幻觉率、提示未对齐幻觉率和一致性,以便更全面地评估LLM的性能。
🖼️ 关键图片

📊 实验亮点
实验结果表明,现有LLM在DefAn数据集上的事实幻觉率高达59%到82%(公共数据集)和57%到76%(隐藏数据集),提示未对齐幻觉率也高达6%到95%(公共数据集)和17%到94%(隐藏数据集)。这些数据突显了现有LLM在幻觉问题上的严重性,并证明了DefAn数据集在评估LLM性能方面的有效性。
🎯 应用场景
该研究成果可应用于LLM的评估和改进,帮助开发者更好地了解和解决LLM的幻觉问题。通过使用DefAn数据集,可以更准确地评估LLM的性能,并开发更有效的幻觉检测和缓解方法。这有助于提高LLM的可靠性和实用性,使其在各种应用场景中发挥更大的作用,例如智能客服、内容生成和知识问答等。
📄 摘要(原文)
Large Language Models (LLMs) have demonstrated remarkable capabilities, revolutionizing the integration of AI in daily life applications. However, they are prone to hallucinations, generating claims that contradict established facts, deviating from prompts, and producing inconsistent responses when the same prompt is presented multiple times. Addressing these issues is challenging due to the lack of comprehensive and easily assessable benchmark datasets. Most existing datasets are small and rely on multiple-choice questions, which are inadequate for evaluating the generative prowess of LLMs. To measure hallucination in LLMs, this paper introduces a comprehensive benchmark dataset comprising over 75,000 prompts across eight domains. These prompts are designed to elicit definitive, concise, and informative answers. The dataset is divided into two segments: one publicly available for testing and assessing LLM performance and a hidden segment for benchmarking various LLMs. In our experiments, we tested six LLMs-GPT-3.5, LLama 2, LLama 3, Gemini, Mixtral, and Zephyr-revealing that overall factual hallucination ranges from 59% to 82% on the public dataset and 57% to 76% in the hidden benchmark. Prompt misalignment hallucination ranges from 6% to 95% in the public dataset and 17% to 94% in the hidden counterpart. Average consistency ranges from 21% to 61% and 22% to 63%, respectively. Domain-wise analysis shows that LLM performance significantly deteriorates when asked for specific numeric information while performing moderately with person, location, and date queries. Our dataset demonstrates its efficacy and serves as a comprehensive benchmark for LLM performance evaluation. Our dataset and LLMs responses are available at \href{https://github.com/ashikiut/DefAn}{https://github.com/ashikiut/DefAn}.