Bayesian Statistical Modeling with Predictors from LLMs
作者: Michael Franke, Polina Tsvilodub, Fausto Carcassi
分类: cs.CL
发布日期: 2024-06-13
备注: 20 pages, 10 figures, parallel submission to a journal
💡 一句话要点
利用LLM预测器进行贝叶斯统计建模,评估其人类行为预测能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 贝叶斯统计建模 人类行为预测 语用语言 决策任务
📋 核心要点
- 现有方法难以评估LLM在多大程度上能模拟人类认知和语言使用,尤其是在决策任务中。
- 论文核心思想是使用贝叶斯统计建模框架,评估LLM预测与人类行为数据之间的拟合程度。
- 实验表明,LLM在项目级别无法捕捉人类数据方差,但在条件级别上,某些预测方法能较好拟合人类数据。
📝 摘要(中文)
当前先进的大型语言模型(LLMs)在各种基准测试中表现出色,并日益被用作大型应用中的组件,其中基于LLM的预测充当人类判断或决策的代理。这引发了关于LLM衍生信息的人类相似性、与人类直觉的一致性,以及LLM是否可以被视为人类认知或语言使用(某些方面)的解释模型的疑问。为了更深入地了解这些问题,我们从贝叶斯统计建模的角度研究了LLM对多项选择决策任务预测的人类相似性。使用来自关于语用语言使用的强制选择实验的人类数据,我们发现LLM无法捕捉项目级别的人类数据方差。我们提出了从LLM中导出用于聚合的、条件级别数据的完整分布预测的不同方法,并发现一些(但不是全部)获得条件级别预测的方法能够充分拟合人类数据。这些结果表明,对LLM性能的评估在很大程度上取决于方法论中看似细微的选择,并且LLM最多只能在聚合的、条件级别上预测人类行为,而它们最初并非为此目的而设计或使用。
🔬 方法详解
问题定义:论文旨在评估大型语言模型(LLMs)在预测人类决策行为方面的能力,尤其是在语用语言使用场景下。现有方法缺乏对LLM预测结果与人类行为数据之间差异的系统性分析,难以判断LLM是否能作为人类认知或语言使用的有效代理模型。现有方法通常只关注整体性能指标,忽略了在不同粒度级别(如个体项目或条件)上的差异。
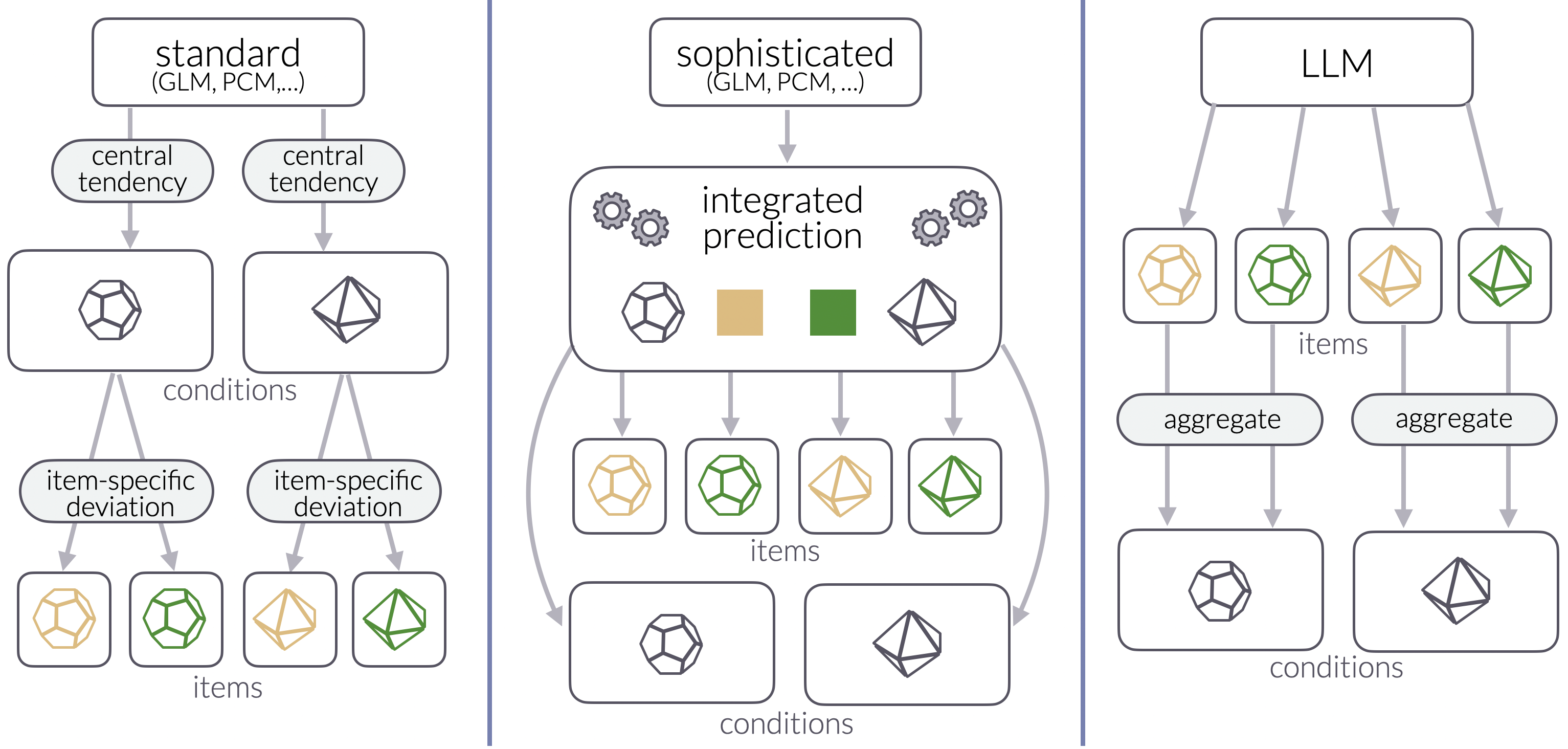
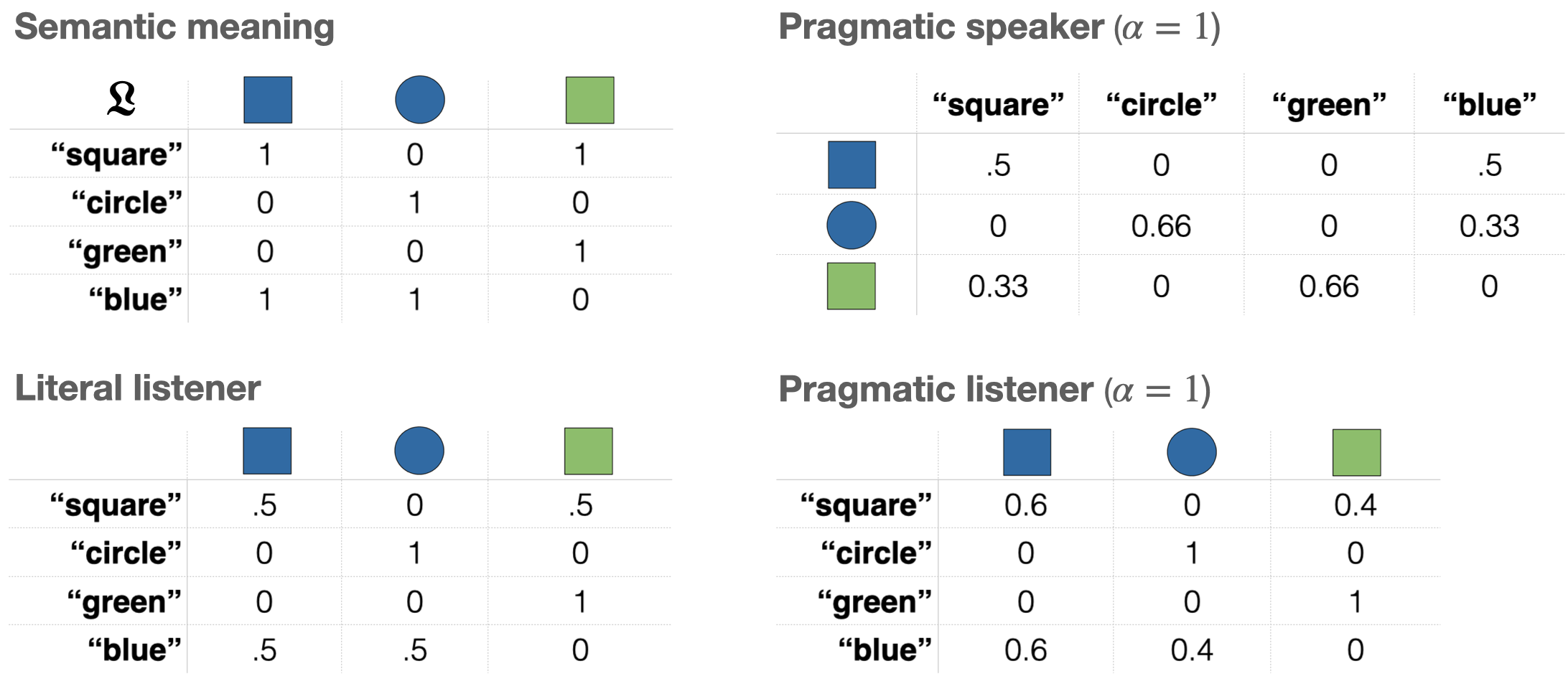
核心思路:论文的核心思路是将LLM的预测结果纳入贝叶斯统计建模框架中,通过比较LLM预测分布与人类行为数据的拟合程度,来评估LLM的人类相似性。这种方法能够更细致地分析LLM在不同条件下的预测能力,并揭示其潜在的局限性。通过比较不同方法获得的LLM预测分布,可以探讨如何更好地利用LLM进行人类行为预测。
技术框架:论文的技术框架主要包括以下几个步骤:1) 从语用语言使用的强制选择实验中获取人类行为数据;2) 使用LLM对相同任务进行预测,并尝试不同的方法将LLM的输出转换为概率分布;3) 构建贝叶斯统计模型,将LLM的预测分布作为先验,人类行为数据作为似然函数;4) 使用贝叶斯模型评估LLM预测分布与人类行为数据的拟合程度,并比较不同LLM预测方法的性能。
关键创新:论文的关键创新在于:1) 将贝叶斯统计建模方法应用于评估LLM的人类相似性,提供了一种更细致、更全面的评估框架;2) 提出了多种从LLM中导出概率分布的方法,并比较了它们在预测人类行为方面的性能;3) 揭示了LLM在项目级别预测人类行为方面的局限性,并强调了在条件级别上进行评估的重要性。
关键设计:论文的关键设计包括:1) 选择了语用语言使用的强制选择实验作为研究对象,该任务具有明确的决策目标和可量化的人类行为数据;2) 尝试了不同的方法将LLM的输出转换为概率分布,例如直接使用LLM的logits作为概率,或使用softmax函数进行归一化;3) 使用了贝叶斯因子(Bayes factor)作为评估LLM预测分布与人类行为数据拟合程度的指标。
🖼️ 关键图片

📊 实验亮点
实验结果表明,LLM在项目级别上无法有效捕捉人类数据的方差。然而,通过适当的方法,例如对LLM的输出进行聚合和归一化,可以在条件级别上获得与人类数据较好的拟合。这表明LLM在预测人类行为方面具有一定的潜力,但需要谨慎选择评估方法和数据处理策略。研究结果强调了评估LLM性能时,方法论选择的重要性。
🎯 应用场景
该研究成果可应用于评估和改进LLM在模拟人类决策过程方面的能力,尤其是在需要考虑语境和意图的场景中,例如人机交互、智能助手、对话系统等。通过更准确地理解LLM的优势和局限性,可以更好地利用LLM来辅助人类决策,并开发更符合人类直觉和期望的AI系统。此外,该研究也为评估其他类型AI模型的人类相似性提供了借鉴。
📄 摘要(原文)
State of the art large language models (LLMs) have shown impressive performance on a variety of benchmark tasks and are increasingly used as components in larger applications, where LLM-based predictions serve as proxies for human judgements or decision. This raises questions about the human-likeness of LLM-derived information, alignment with human intuition, and whether LLMs could possibly be considered (parts of) explanatory models of (aspects of) human cognition or language use. To shed more light on these issues, we here investigate the human-likeness of LLMs' predictions for multiple-choice decision tasks from the perspective of Bayesian statistical modeling. Using human data from a forced-choice experiment on pragmatic language use, we find that LLMs do not capture the variance in the human data at the item-level. We suggest different ways of deriving full distributional predictions from LLMs for aggregate, condition-level data, and find that some, but not all ways of obtaining condition-level predictions yield adequate fits to human data. These results suggests that assessment of LLM performance depends strongly on seemingly subtle choices in methodology, and that LLMs are at best predictors of human behavior at the aggregate, condition-level, for which they are, however, not designed to, or usually used to, make predictions in the first place.