Navigating the Shadows: Unveiling Effective Disturbances for Modern AI Content Detectors
作者: Ying Zhou, Ben He, Le Sun
分类: cs.CL, cs.AI, cs.LG
发布日期: 2024-06-13
备注: Accepted by ACL 2024, Main Conference
🔗 代码/项目: GITHUB
💡 一句话要点
系统性评估AI文本检测器鲁棒性:揭示有效扰动方法与对抗学习策略
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: AI文本检测 鲁棒性评估 文本扰动 对抗学习 数据增强
📋 核心要点
- 现有AI文本检测器在面对文本扰动时鲁棒性不足,难以有效区分人类修改后的机器生成文本。
- 通过构建多种黑盒文本扰动方法,系统性评估现有AI文本检测器在不同扰动下的性能表现。
- 利用对抗学习,研究扰动数据增强对提升AI文本检测器鲁棒性的影响,并开源代码和数据。
📝 摘要(中文)
随着ChatGPT的发布,大型语言模型(LLMs)受到了全球关注。在文章写作领域,LLMs得到了广泛应用,但也引发了知识产权保护、个人隐私和学术诚信等问题。为了应对这些问题,AI文本检测技术应运而生,旨在区分人类生成的内容和机器生成的内容。然而,最近的研究表明,这些检测系统通常缺乏鲁棒性,难以有效区分受扰动的文本。目前,对于检测器在实际应用中的性能缺乏系统的评估,也缺乏对扰动技术和检测器鲁棒性的全面考察。为了弥补这一差距,我们的工作模拟了非正式和专业写作中的真实场景,探索了当前检测器的开箱即用性能。此外,我们构建了12种黑盒文本扰动方法,以评估当前检测模型在各种扰动粒度下的鲁棒性。更进一步,通过对抗学习实验,我们研究了扰动数据增强对AI文本检测器鲁棒性的影响。我们已在https://github.com/zhouying20/ai-text-detector-evaluation上发布了我们的代码和数据。
🔬 方法详解
问题定义:论文旨在解决现有AI文本检测器在面对真实场景下的文本扰动时,鲁棒性不足的问题。现有方法缺乏系统性的评估,无法有效区分经过人为修改或润色的机器生成文本,导致检测准确率下降。这给知识产权保护、学术诚信等领域带来了挑战。
核心思路:论文的核心思路是通过模拟真实场景下的文本扰动,系统性地评估现有AI文本检测器的鲁棒性。通过构建多种黑盒扰动方法,模拟人类对机器生成文本的修改行为,从而考察检测器在不同程度扰动下的性能表现。此外,利用对抗学习,通过扰动数据增强的方式,提升检测器的鲁棒性。
技术框架:论文的技术框架主要包含三个部分:1) 模拟真实场景,构建非正式和专业写作两种场景下的数据集;2) 构建12种黑盒文本扰动方法,模拟不同粒度的文本扰动;3) 利用对抗学习,通过扰动数据增强的方式训练AI文本检测器。整体流程为:首先,利用LLM生成文本,然后对文本进行扰动,最后利用扰动后的数据评估和训练AI文本检测器。
关键创新:论文的关键创新在于:1) 系统性地评估了现有AI文本检测器在真实场景下的鲁棒性,填补了该领域的空白;2) 构建了多种黑盒文本扰动方法,能够模拟不同粒度的文本扰动,更贴近真实场景;3) 利用对抗学习,通过扰动数据增强的方式,有效提升了AI文本检测器的鲁棒性。
关键设计:论文的关键设计包括:1) 12种黑盒文本扰动方法,例如同义词替换、句子重排、语法错误注入等,这些方法模拟了人类对机器生成文本的常见修改方式;2) 对抗学习中的损失函数设计,旨在使检测器能够区分原始文本和扰动后的文本;3) 实验中对不同扰动粒度的控制,以便评估检测器在不同程度扰动下的性能表现。
🖼️ 关键图片

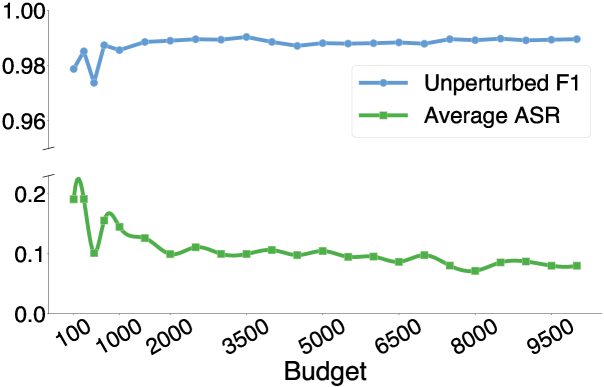
📊 实验亮点
实验结果表明,现有AI文本检测器在面对文本扰动时性能显著下降。例如,在经过同义词替换等简单扰动后,检测准确率下降超过20%。通过对抗学习和扰动数据增强,可以有效提升检测器的鲁棒性,在相同扰动条件下,准确率提升超过10%。该研究揭示了现有检测器的脆弱性,并为提升其鲁棒性提供了有效方法。
🎯 应用场景
该研究成果可应用于多个领域,包括:1) 知识产权保护,帮助检测抄袭或未经授权的AI生成内容;2) 学术诚信,辅助判断论文或作业是否由AI生成;3) 内容审核,过滤由AI生成的虚假信息或恶意内容。通过提高AI文本检测器的鲁棒性,可以有效应对AI内容生成带来的挑战,维护网络空间的健康发展。
📄 摘要(原文)
With the launch of ChatGPT, large language models (LLMs) have attracted global attention. In the realm of article writing, LLMs have witnessed extensive utilization, giving rise to concerns related to intellectual property protection, personal privacy, and academic integrity. In response, AI-text detection has emerged to distinguish between human and machine-generated content. However, recent research indicates that these detection systems often lack robustness and struggle to effectively differentiate perturbed texts. Currently, there is a lack of systematic evaluations regarding detection performance in real-world applications, and a comprehensive examination of perturbation techniques and detector robustness is also absent. To bridge this gap, our work simulates real-world scenarios in both informal and professional writing, exploring the out-of-the-box performance of current detectors. Additionally, we have constructed 12 black-box text perturbation methods to assess the robustness of current detection models across various perturbation granularities. Furthermore, through adversarial learning experiments, we investigate the impact of perturbation data augmentation on the robustness of AI-text detectors. We have released our code and data at https://github.com/zhouying20/ai-text-detector-evaluation.