mOSCAR: A Large-scale Multilingual and Multimodal Document-level Corpus
作者: Matthieu Futeral, Armel Zebaze, Pedro Ortiz Suarez, Julien Abadji, Rémi Lacroix, Cordelia Schmid, Rachel Bawden, Benoît Sagot
分类: cs.CL, cs.CV
发布日期: 2024-06-13 (更新: 2025-05-29)
备注: ACL 2025 (Findings)
🔗 代码/项目: HUGGINGFACE
💡 一句话要点
提出mOSCAR:一个大规模多语言多模态文档级语料库,提升多语言图像-文本任务的少样本学习能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多语言 多模态 文档级语料库 少样本学习 图像-文本任务
📋 核心要点
- 现有的多语言多模态数据集规模有限或为私有,阻碍了多语言环境下多模态大型语言模型的研究。
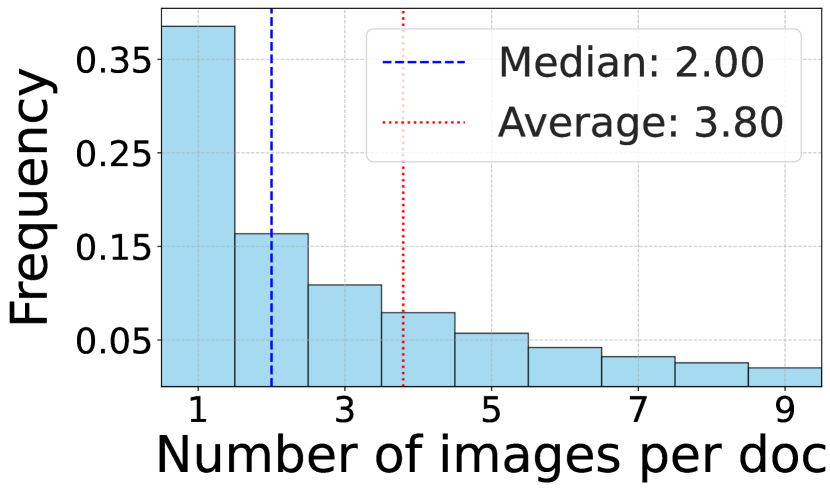
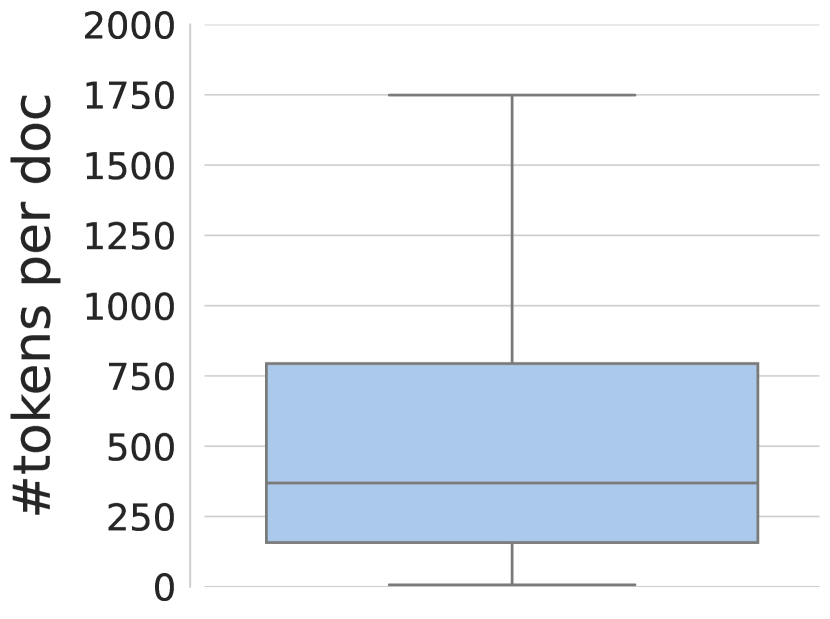
- 论文提出了mOSCAR,一个大规模多语言多模态文档级语料库,包含163种语言的文档和图像数据。
- 实验表明,在mOSCAR上训练的模型在多语言图像-文本任务中表现出显著的少样本学习性能提升。
📝 摘要(中文)
多模态大型语言模型(mLLM)的训练依赖于大量的文本-图像数据。虽然大多数mLLM仅在类似标题的数据上训练,但Alayrac等人(2022)表明,额外地在文本和图像的交错序列上训练它们可以导致上下文学习能力的出现。然而,他们使用的数据集M3W不是公开的,并且仅为英语。已经有一些尝试重现他们的结果,但发布的数据集仅为英语。相比之下,当前的多语言和多模态数据集要么仅由类似标题的数据组成,要么是中等规模或完全私有的数据。这限制了全球7000种其他语言的mLLM研究。因此,我们引入了mOSCAR,据我们所知,这是第一个从网络上抓取的大规模多语言和多模态文档语料库。它涵盖163种语言,3.03亿份文档,2000亿个token和11.5亿张图像。我们仔细地进行了一系列过滤和评估步骤,以确保mOSCAR足够安全、多样化和高质量。我们还训练了两种类型的多语言模型来证明mOSCAR的优势:(1)在mOSCAR子集和字幕数据上训练的模型,以及(2)仅在字幕数据上训练的模型。在mOSCAR上额外训练的模型在各种多语言图像-文本任务和基准测试中显示出强大的少样本学习性能提升,证实了之前对仅英语mLLM的发现。该数据集以Creative Commons CC BY 4.0许可发布,可在此处访问:https://huggingface.co/datasets/oscar-corpus/mOSCAR
🔬 方法详解
问题定义:现有的多模态大型语言模型(mLLM)训练数据集,尤其是支持上下文学习的数据集,在多语言方面存在不足。已有的多语言多模态数据集要么规模较小,要么是私有的,限制了对7000多种语言的mLLM研究。因此,需要一个大规模、公开、高质量的多语言多模态文档级语料库。
核心思路:通过大规模网络爬取,构建一个包含多种语言的文档和图像数据的数据集。通过一系列过滤和评估步骤,保证数据集的安全性、多样性和质量。利用该数据集训练多语言模型,验证其在多语言图像-文本任务中的少样本学习能力。
技术框架:mOSCAR的构建主要包含以下几个阶段:1) 网络爬取:从网络上抓取包含文本和图像的文档。2) 语言识别:自动识别文档的语言。3) 数据清洗和过滤:进行一系列过滤步骤,包括删除低质量、不安全或重复的内容。4) 数据评估:评估数据集的质量、多样性和安全性。5) 模型训练:使用mOSCAR训练多语言模型,并评估其性能。
关键创新:mOSCAR是第一个大规模、公开的多语言多模态文档级语料库。它覆盖了163种语言,包含3.03亿份文档,2000亿个token和11.5亿张图像。该数据集的发布将促进多语言多模态大型语言模型的研究。
关键设计:数据过滤阶段采用了多种策略,包括基于规则的过滤(例如,删除包含特定关键词的文档)、基于模型的过滤(例如,使用语言模型评估文档的质量)和人工评估。模型训练方面,论文训练了两种类型的多语言模型:一种是在mOSCAR子集和字幕数据上训练的模型,另一种是仅在字幕数据上训练的模型。通过比较这两种模型的性能,可以评估mOSCAR的有效性。
🖼️ 关键图片

📊 实验亮点
实验结果表明,在mOSCAR上额外训练的模型在各种多语言图像-文本任务和基准测试中显示出强大的少样本学习性能提升。与仅在字幕数据上训练的模型相比,在mOSCAR上训练的模型在多个任务上取得了显著的性能提升,证实了mOSCAR的有效性。
🎯 应用场景
mOSCAR的潜在应用领域包括多语言图像搜索、多语言文档理解、多语言多模态对话系统等。该数据集的发布将促进多语言人工智能技术的发展,并为全球用户提供更好的多语言服务。未来,可以利用mOSCAR进一步研究跨语言知识迁移、多语言少样本学习等问题。
📄 摘要(原文)
Multimodal Large Language Models (mLLMs) are trained on a large amount of text-image data. While most mLLMs are trained on caption-like data only, Alayrac et al. (2022) showed that additionally training them on interleaved sequences of text and images can lead to the emergence of in-context learning capabilities. However, the dataset they used, M3W, is not public and is only in English. There have been attempts to reproduce their results but the released datasets are English-only. In contrast, current multilingual and multimodal datasets are either composed of caption-like only or medium-scale or fully private data. This limits mLLM research for the 7,000 other languages spoken in the world. We therefore introduce mOSCAR, to the best of our knowledge the first large-scale multilingual and multimodal document corpus crawled from the web. It covers 163 languages, 303M documents, 200B tokens and 1.15B images. We carefully conduct a set of filtering and evaluation steps to make sure mOSCAR is sufficiently safe, diverse and of good quality. We additionally train two types of multilingual model to prove the benefits of mOSCAR: (1) a model trained on a subset of mOSCAR and captioning data and (2) a model trained on captioning data only. The model additionally trained on mOSCAR shows a strong boost in few-shot learning performance across various multilingual image-text tasks and benchmarks, confirming previous findings for English-only mLLMs. The dataset is released under the Creative Commons CC BY 4.0 license and can be accessed here: https://huggingface.co/datasets/oscar-corpus/mOSCAR