MobileAIBench: Benchmarking LLMs and LMMs for On-Device Use Cases
作者: Rithesh Murthy, Liangwei Yang, Juntao Tan, Tulika Manoj Awalgaonkar, Yilun Zhou, Shelby Heinecke, Sachin Desai, Jason Wu, Ran Xu, Sarah Tan, Jianguo Zhang, Zhiwei Liu, Shirley Kokane, Zuxin Liu, Ming Zhu, Huan Wang, Caiming Xiong, Silvio Savarese
分类: cs.CL, cs.AI, cs.LG
发布日期: 2024-06-12
💡 一句话要点
MobileAIBench:移动端LLM/LMM基准测试框架,评估量化影响与设备性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 移动AI 基准测试 大型语言模型 多模态模型 量化 设备端推理 性能评估
📋 核心要点
- 现有方法缺乏对移动设备上量化LLM/LMM性能的系统评估,尤其是在信任和安全方面。
- MobileAIBench提供了一个全面的基准测试框架,用于评估移动优化的LLM和LMM在不同量化级别和任务上的性能。
- 该框架包含桌面评估库和iOS应用,用于测量真实设备上的延迟和硬件资源消耗,加速移动AI研究。
📝 摘要(中文)
由于增强的隐私性、稳定性和个性化等优势,在移动设备上部署大型语言模型(LLM)和大型多模态模型(LMM)受到了广泛关注。然而,移动设备的硬件限制需要使用参数较少的模型和诸如量化之类的模型压缩技术。目前,对于量化对各种任务性能(包括LLM任务、LMM任务,以及至关重要的信任和安全)的影响的理解有限。同时,也缺乏充分的工具来系统地测试移动设备上的这些模型。为了解决这些差距,我们推出了MobileAIBench,这是一个全面的基准测试框架,用于评估移动优化的LLM和LMM。MobileAIBench跨不同大小、量化级别和任务评估模型,测量真实设备上的延迟和资源消耗。我们的两部分开源框架包括一个用于在桌面上运行评估的库和一个用于设备上延迟和硬件利用率测量的iOS应用程序。我们全面的分析旨在通过深入了解在移动平台上部署LLM和LMM的性能和可行性,从而加速移动AI研究和部署。
🔬 方法详解
问题定义:论文旨在解决在移动设备上部署LLM和LMM时,由于硬件资源限制,模型需要进行量化等压缩,但目前缺乏系统性的评估工具来衡量量化对模型性能,特别是对信任和安全方面的影响。现有方法无法充分评估量化对模型在移动设备上的延迟、资源消耗以及各种任务性能的影响。
核心思路:论文的核心思路是构建一个全面的基准测试框架MobileAIBench,该框架能够系统地评估不同大小和量化级别的LLM和LMM在移动设备上的性能。通过在真实设备上测量延迟和资源消耗,为移动AI研究和部署提供有价值的见解。
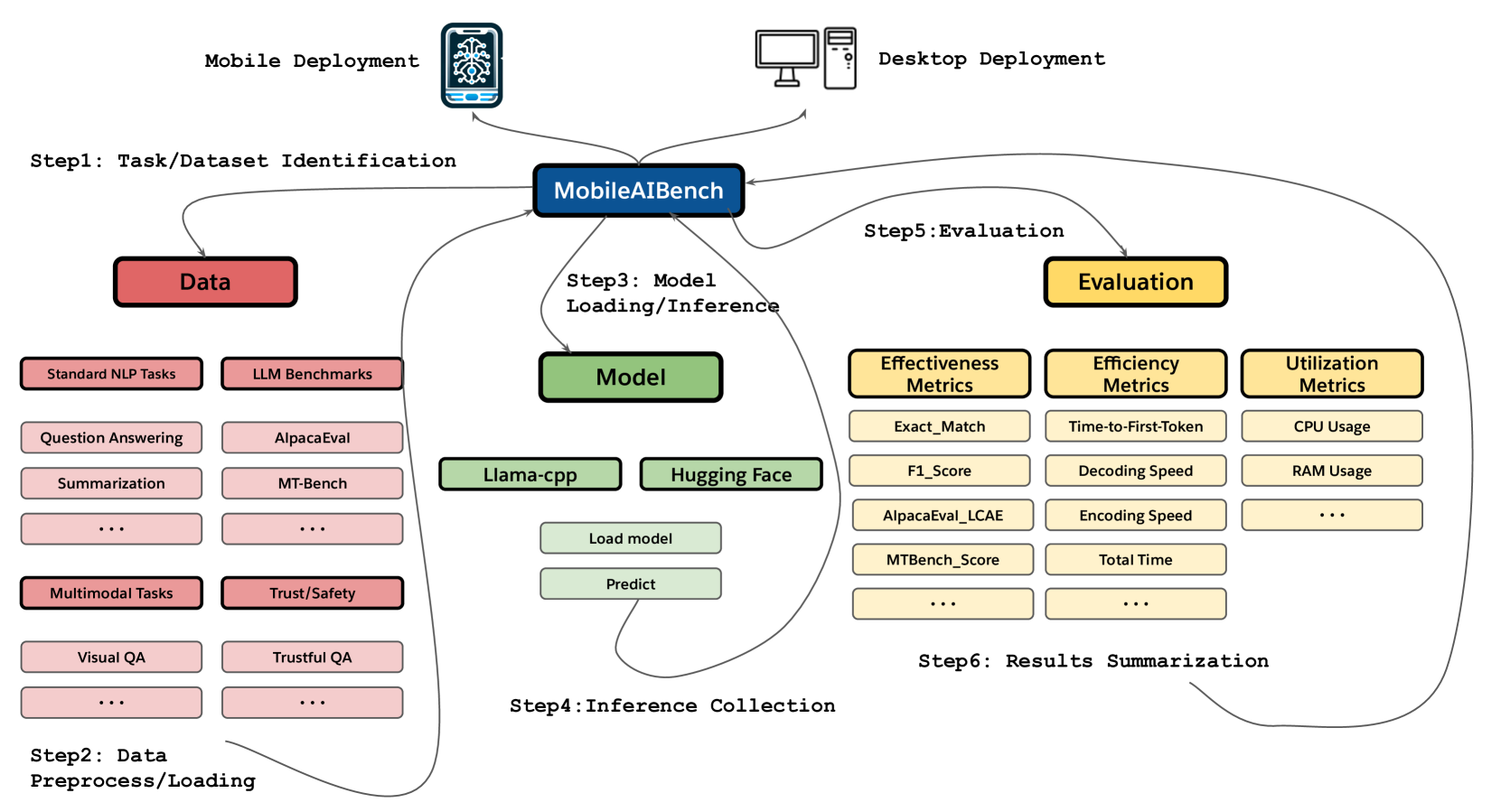
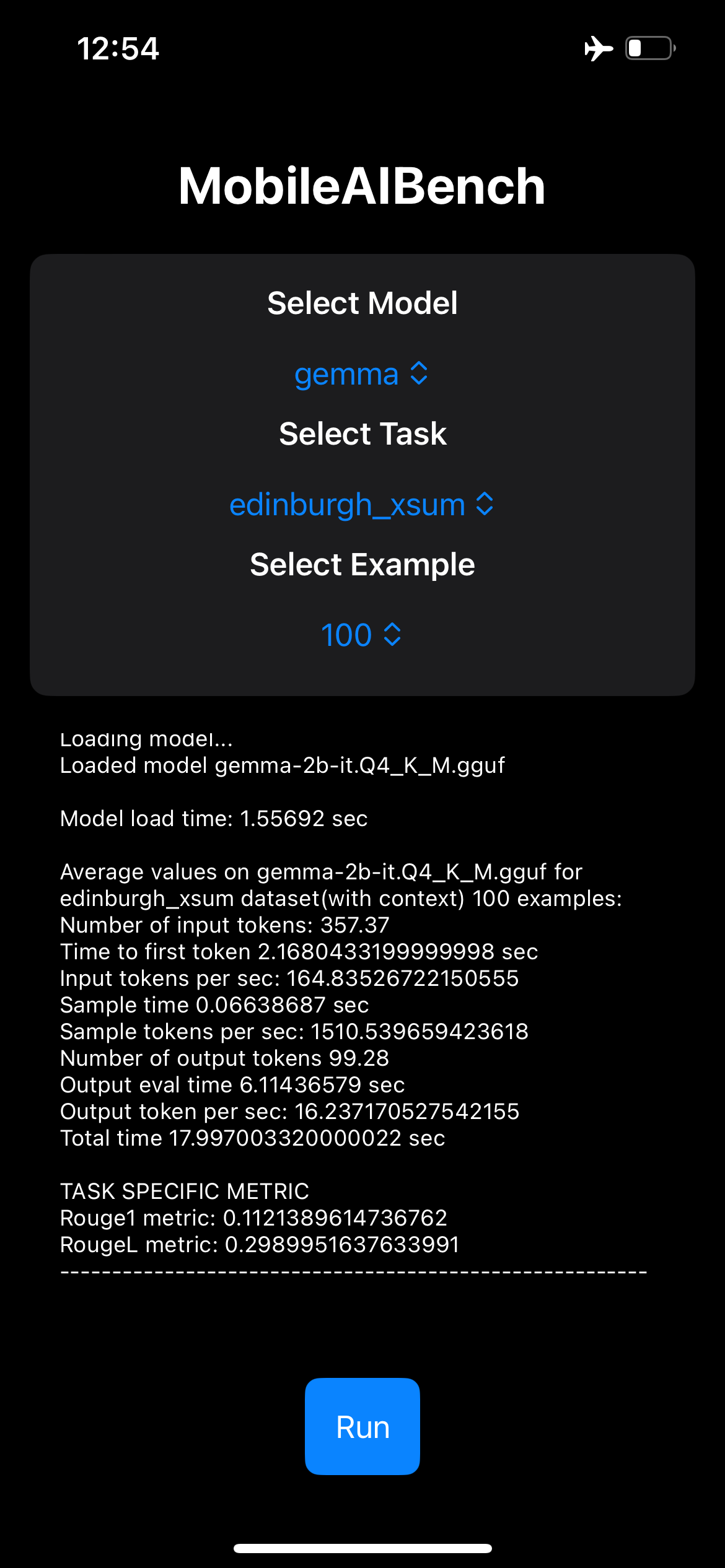
技术框架:MobileAIBench框架包含两个主要部分:1) 一个用于在桌面环境中运行评估的库,该库允许研究人员方便地测试和比较不同模型的性能。2) 一个iOS应用程序,用于在真实的移动设备上测量模型的延迟和硬件利用率。该应用能够提供更准确的性能评估,因为它可以反映实际设备上的资源限制和硬件特性。
关键创新:MobileAIBench的关键创新在于其综合性和实用性。它不仅提供了一个评估LLM和LMM的平台,还考虑了移动设备的特殊限制,并提供了在真实设备上进行测量的工具。此外,该框架还关注了量化对模型信任和安全的影响,这在之前的研究中往往被忽视。
关键设计:MobileAIBench的设计重点在于易用性和可扩展性。桌面评估库提供了一组标准的测试任务和评估指标,方便研究人员进行比较。iOS应用程序则提供了详细的硬件利用率数据,帮助研究人员了解模型在移动设备上的资源消耗情况。具体的参数设置、损失函数和网络结构取决于被评估的模型,MobileAIBench框架本身并不限定这些细节,而是提供了一个灵活的评估平台。
🖼️ 关键图片

📊 实验亮点
MobileAIBench通过在真实移动设备上进行测试,提供了关于不同量化级别对LLM和LMM性能影响的详细数据。该框架能够测量模型在不同任务上的延迟和资源消耗,并评估其在信任和安全方面的表现。这些实验结果为移动AI研究人员和开发者提供了宝贵的参考,帮助他们更好地理解和优化模型在移动设备上的部署。
🎯 应用场景
MobileAIBench可应用于移动设备上的各种AI应用,如智能助手、图像识别、自然语言处理等。该框架能够帮助开发者选择合适的模型和量化策略,以在性能、资源消耗和安全性之间取得平衡。通过优化模型在移动设备上的部署,可以提升用户体验,并促进移动AI技术的普及。
📄 摘要(原文)
The deployment of Large Language Models (LLMs) and Large Multimodal Models (LMMs) on mobile devices has gained significant attention due to the benefits of enhanced privacy, stability, and personalization. However, the hardware constraints of mobile devices necessitate the use of models with fewer parameters and model compression techniques like quantization. Currently, there is limited understanding of quantization's impact on various task performances, including LLM tasks, LMM tasks, and, critically, trust and safety. There is a lack of adequate tools for systematically testing these models on mobile devices. To address these gaps, we introduce MobileAIBench, a comprehensive benchmarking framework for evaluating mobile-optimized LLMs and LMMs. MobileAIBench assesses models across different sizes, quantization levels, and tasks, measuring latency and resource consumption on real devices. Our two-part open-source framework includes a library for running evaluations on desktops and an iOS app for on-device latency and hardware utilization measurements. Our thorough analysis aims to accelerate mobile AI research and deployment by providing insights into the performance and feasibility of deploying LLMs and LMMs on mobile platforms.