Analyzing Large Language Models for Classroom Discussion Assessment
作者: Nhat Tran, Benjamin Pierce, Diane Litman, Richard Correnti, Lindsay Clare Matsumura
分类: cs.CL
发布日期: 2024-06-12
备注: EDM 2024 Short Paper
💡 一句话要点
利用大型语言模型评估课堂讨论质量,并分析任务形式、上下文长度和少量样本的影响。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 课堂讨论评估 自然语言处理 教育应用 任务形式 上下文长度 少量样本学习
📋 核心要点
- 现有的课堂讨论质量评估方法效率较低,难以大规模应用,而大型语言模型为自动化评估提供了新的可能性。
- 该研究通过分析任务形式、上下文长度和少量样本等因素对LLM评估性能的影响,旨在优化LLM在课堂讨论评估中的应用。
- 实验结果表明,任务形式、上下文长度和少量样本会影响LLM的评估性能,且预测一致性与性能之间存在关联。
📝 摘要(中文)
本文探讨了如何利用大型语言模型(LLMs)自动评估课堂讨论质量。研究考察了两个LLM的评估性能与三个可能影响性能的因素之间的关系:任务形式、上下文长度和少量样本。此外,还探讨了这两个LLM的计算效率和预测一致性。结果表明,上述三个因素确实会影响所测试LLM的性能,并且一致性与性能之间存在关联。研究建议采用一种基于LLM的评估方法,该方法在预测性能、计算效率和一致性方面具有良好的平衡。
🔬 方法详解
问题定义:论文旨在解决课堂讨论质量的自动评估问题。现有方法通常依赖人工评估,耗时且成本高昂,难以实现大规模应用。此外,现有方法的主观性较强,评估标准难以统一。因此,如何利用自然语言处理技术,特别是大型语言模型,实现高效、客观的课堂讨论质量评估是本文要解决的核心问题。
核心思路:论文的核心思路是利用大型语言模型强大的文本理解和生成能力,直接对课堂讨论文本进行分析和评估。通过调整任务形式、上下文长度和少量样本等因素,探索LLM在评估任务中的最佳配置,从而提高评估的准确性和效率。同时,研究还关注LLM的计算效率和预测一致性,力求找到一个性能、效率和一致性之间的平衡点。
技术框架:该研究的技术框架主要包括以下几个步骤:1) 数据收集:收集课堂讨论文本数据,并进行预处理。2) 模型选择:选择两个具有代表性的大型语言模型进行实验。3) 任务构建:设计不同的任务形式,例如分类、回归等,以评估LLM的性能。4) 参数调整:调整上下文长度和少量样本数量等参数,探索其对LLM性能的影响。5) 性能评估:使用标准的评估指标,例如准确率、F1值等,评估LLM的性能。6) 一致性分析:分析LLM在不同条件下的预测一致性。
关键创新:该研究的关键创新在于系统性地分析了任务形式、上下文长度和少量样本等因素对LLM在课堂讨论评估任务中的影响。以往的研究较少关注这些因素对LLM性能的细致影响,而本文通过实验揭示了这些因素与LLM性能之间的关系,为LLM在教育领域的应用提供了重要的指导。
关键设计:在任务形式方面,研究可能尝试了不同的分类或回归任务,例如将讨论质量分为几个等级,或者预测讨论的得分。在上下文长度方面,研究可能尝试了不同的窗口大小,以控制输入到LLM的文本长度。在少量样本方面,研究可能尝试了不同数量的示例,以帮助LLM更好地理解评估标准。具体的损失函数和网络结构取决于所选择的LLM,但研究重点在于调整任务形式、上下文长度和少量样本等外部因素。
🖼️ 关键图片


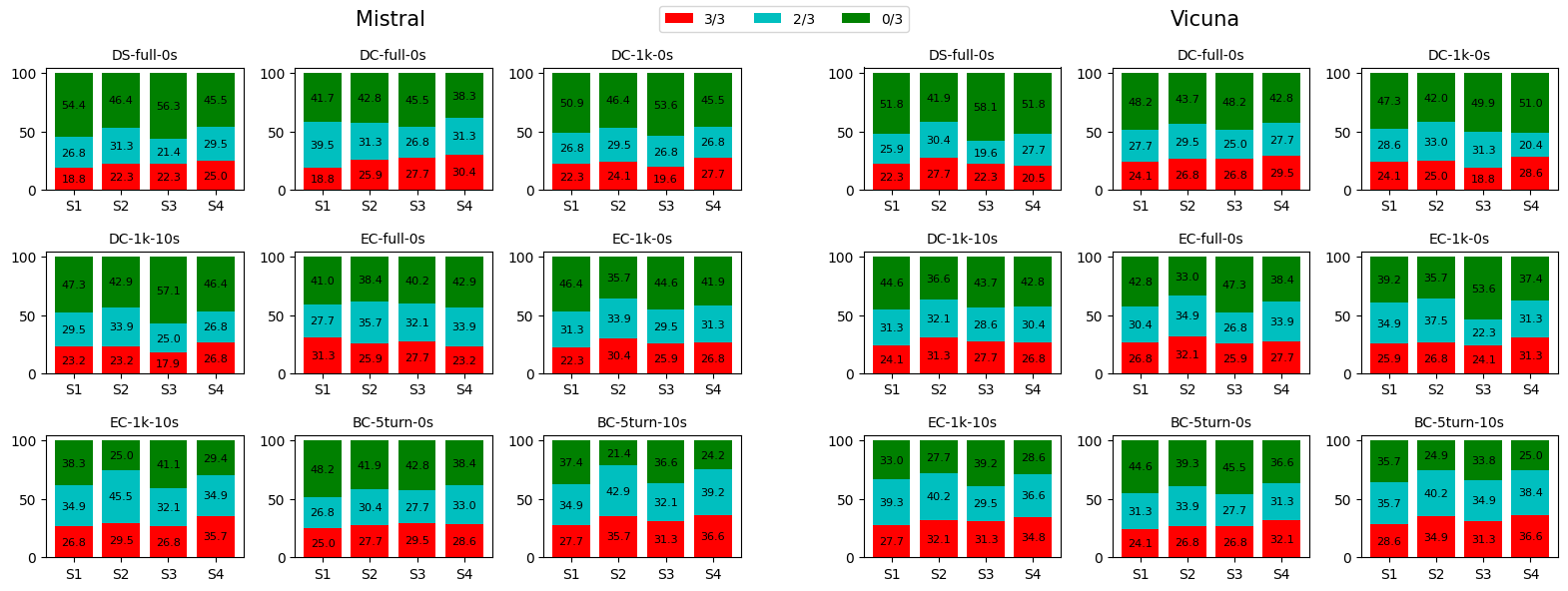
📊 实验亮点
研究结果表明,任务形式、上下文长度和少量样本等因素显著影响LLM的评估性能。具体性能数据未知,但研究强调了在预测性能、计算效率和一致性之间取得平衡的重要性。该研究为基于LLM的课堂讨论评估方法提供了有价值的指导,并为未来的研究方向提供了启示。
🎯 应用场景
该研究成果可应用于大规模在线教育平台,自动评估学生的课堂讨论质量,为教师提供反馈,并帮助学生提高参与度和学习效果。此外,该方法还可以推广到其他教育场景,例如论文评审、小组作业评估等,具有广泛的应用前景和实际价值。未来,可以进一步研究如何结合多模态信息,例如语音、视频等,提高评估的准确性和鲁棒性。
📄 摘要(原文)
Automatically assessing classroom discussion quality is becoming increasingly feasible with the help of new NLP advancements such as large language models (LLMs). In this work, we examine how the assessment performance of 2 LLMs interacts with 3 factors that may affect performance: task formulation, context length, and few-shot examples. We also explore the computational efficiency and predictive consistency of the 2 LLMs. Our results suggest that the 3 aforementioned factors do affect the performance of the tested LLMs and there is a relation between consistency and performance. We recommend a LLM-based assessment approach that has a good balance in terms of predictive performance, computational efficiency, and consistency.