Mistral-C2F: Coarse to Fine Actor for Analytical and Reasoning Enhancement in RLHF and Effective-Merged LLMs
作者: Chen Zheng, Ke Sun, Xun Zhou
分类: cs.CL
发布日期: 2024-06-12
💡 一句话要点
提出Mistral-C2F模型,通过粗到精Actor提升小规模LLM在RLHF中的分析推理能力。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 强化学习 大型语言模型 分析推理 知识蒸馏 对话生成
📋 核心要点
- 小规模LLM在深度对话和分析方面存在不足,难以生成连贯的、深入的回复。
- 提出粗到精Actor模型,通过连续最大化和知识残差合并,提升LLM的分析和推理能力。
- Mistral-C2F在多项任务中超越同规模甚至更大规模的模型,验证了方法的有效性。
📝 摘要(中文)
本文提出了一种新颖的两步粗到精(Coarse-to-Fine)Actor模型,旨在解决小规模LLM在对话和分析能力方面的固有局限性。该方法首先采用基于策略的粗Actor,并使用一种名为“连续最大化”的技术,建立一个增强的、知识丰富的池,擅长与人类偏好的分析和推理风格对齐。通过RLHF过程,它采用连续最大化策略,动态地、自适应地扩展输出长度限制,从而生成更详细和分析性的内容。随后,精Actor提炼这些分析内容,解决粗Actor生成过多冗余信息的问题。我们引入了一种“知识残差合并”方法,提炼粗Actor的内容,并将其与现有的指令模型合并,以提高质量、正确性并减少冗余。我们将该方法应用于流行的Mistral模型,创建了Mistral-C2F,该模型在11个通用语言任务和MT-Bench对话任务中表现出色,优于类似规模的模型,甚至优于具有13B和30B参数的更大模型。我们的模型显著提高了对话和分析推理能力。
🔬 方法详解
问题定义:现有的小规模LLM,如Llama和Mistral,在生成深入且连贯的对话方面存在困难。它们在分析和推理能力上有所欠缺,无法充分满足用户对高质量、分析性回复的需求。现有方法难以在保证生成质量的同时,有效利用小规模模型的计算资源。
核心思路:论文的核心思路是将复杂的生成过程分解为两个阶段:粗略生成和精细提炼。粗Actor负责生成知识丰富、符合人类偏好的分析性内容,而精Actor则负责消除冗余、提高质量和正确性。这种分阶段的方法允许模型在不同阶段专注于不同的任务,从而更有效地利用计算资源。
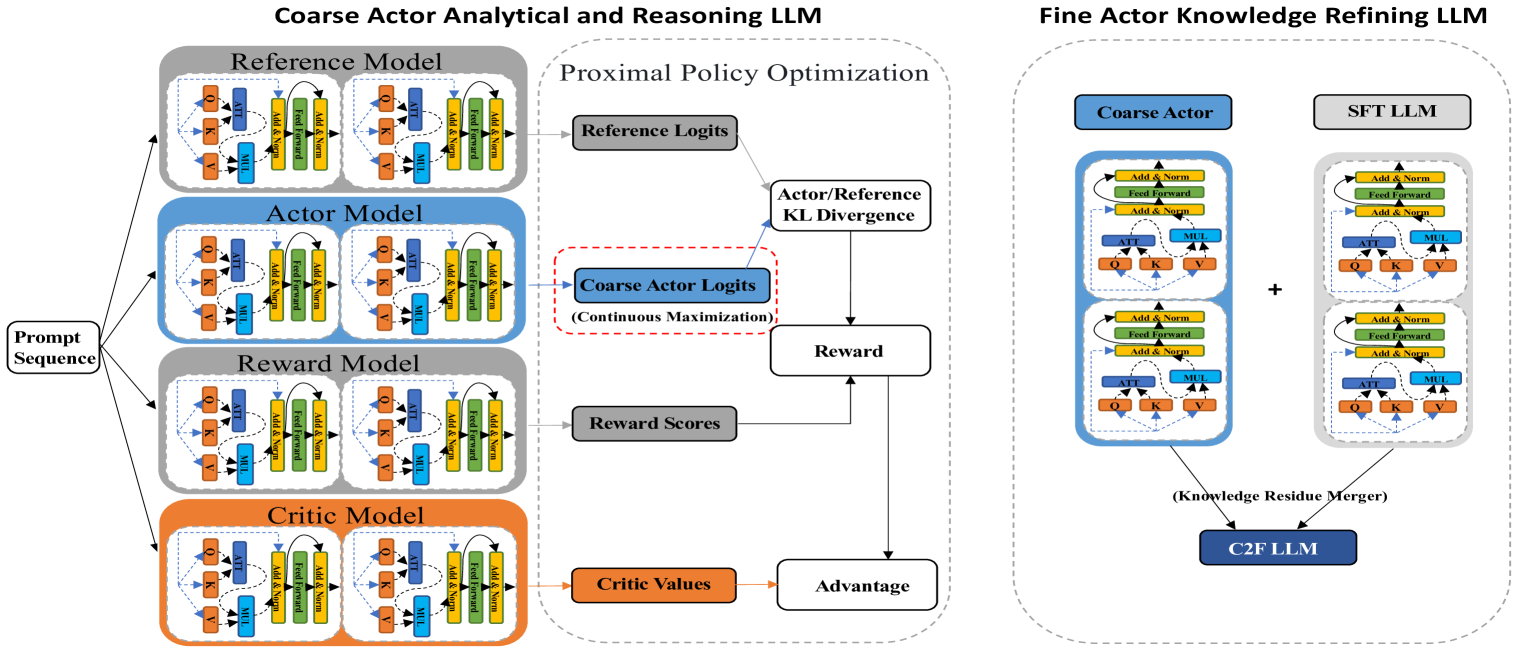
技术框架:Mistral-C2F模型包含两个主要模块:Policy-based Coarse Actor和Fine Actor。Coarse Actor使用“连续最大化”技术,在RLHF过程中动态调整输出长度,生成更详细的分析内容。Fine Actor使用“知识残差合并”方法,将Coarse Actor的输出与现有指令模型合并,以提高质量并减少冗余。整体流程是先由Coarse Actor生成初步内容,再由Fine Actor进行优化。
关键创新:论文的关键创新在于“连续最大化”和“知识残差合并”两种技术。“连续最大化”允许模型自适应地扩展输出长度,从而生成更深入的分析。“知识残差合并”则通过融合现有指令模型的知识,提高了生成内容的质量和正确性,同时减少了冗余。与现有方法相比,该方法更有效地利用了小规模模型的计算资源,并显著提升了分析推理能力。
关键设计:连续最大化:动态调整输出长度限制,鼓励生成更详细的分析内容。知识残差合并:将Coarse Actor的输出与现有指令模型合并,具体合并方式未知。RLHF过程:使用人类反馈进行强化学习,优化Coarse Actor和Fine Actor的策略。具体损失函数和网络结构细节未知。
🖼️ 关键图片

📊 实验亮点
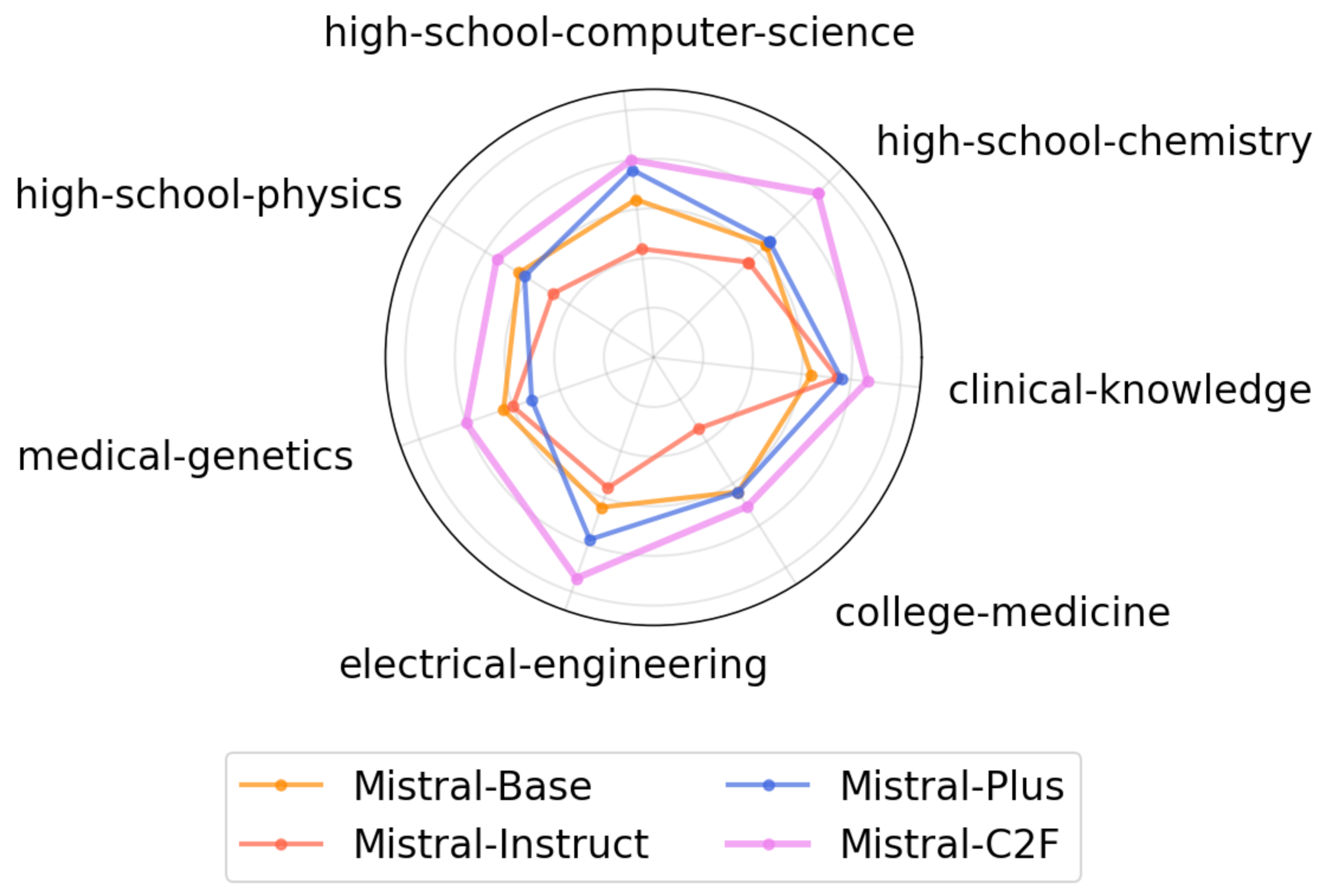
Mistral-C2F在11个通用语言任务和MT-Bench对话任务中表现出色,超越了同等规模的模型,甚至优于参数量为13B和30B的模型。这表明该方法能够有效提升小规模LLM的性能,使其在复杂任务中具有竞争力。具体的性能提升幅度未知。
🎯 应用场景
该研究成果可应用于智能客服、教育辅导、内容创作等领域。通过提升小规模LLM的分析推理能力,可以为用户提供更深入、更专业的服务。未来,该方法有望推广到更多小规模LLM上,使其在资源受限的环境中也能发挥重要作用,例如移动设备或边缘计算场景。
📄 摘要(原文)
Despite the advances in Large Language Models (LLMs), exemplified by models like GPT-4 and Claude, smaller-scale LLMs such as Llama and Mistral often struggle with generating in-depth and coherent dialogues. This paper presents a novel two-step Coarse-to-Fine Actor model to address the inherent limitations in conversational and analytical capabilities of small-sized LLMs. Our approach begins with the Policy-based Coarse Actor, employing a technique we term "Continuous Maximization". The Coarse Actor establishes an enhanced, knowledge-rich pool adept at aligning with human preference styles in analysis and reasoning. Through the RLHF process, it employs Continuous Maximization, a strategy that dynamically and adaptively extends the output length limit, enabling the generation of more detailed and analytical content. Subsequently, the Fine Actor refines this analytical content, addressing the generation of excessively redundant information from the Coarse Actor. We introduce a "Knowledge Residue Merger" approach, refining the content from the Coarse Actor and merging it with an existing Instruction model to improve quality, correctness, and reduce redundancies. We applied our methodology to the popular Mistral model, creating Mistral-C2F, which has demonstrated exceptional performance across 11 general language tasks and the MT-Bench Dialogue task, outperforming similar-scale models and even larger models with 13B and 30B parameters. Our model has significantly improved conversational and analytical reasoning abilities.