CS-Bench: A Comprehensive Benchmark for Large Language Models towards Computer Science Mastery
作者: Xiaoshuai Song, Muxi Diao, Guanting Dong, Zhengyang Wang, Yujia Fu, Runqi Qiao, Zhexu Wang, Dayuan Fu, Huangxuan Wu, Bin Liang, Weihao Zeng, Yejie Wang, Zhuoma GongQue, Jianing Yu, Qiuna Tan, Weiran Xu
分类: cs.CL, cs.AI, cs.LG
发布日期: 2024-06-12 (更新: 2025-02-28)
备注: Accepted at ICLR 2025
🔗 代码/项目: GITHUB
💡 一句话要点
CS-Bench:一个面向计算机科学领域的大语言模型综合评测基准
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 计算机科学 评测基准 多语言 知识推理 模型评估 人工智能
📋 核心要点
- 现有LLM评测基准过度关注数学和代码生成等特定技能,缺乏对LLM在计算机科学领域能力的全面评估。
- CS-Bench旨在提供一个多语言、多任务的综合性评测基准,用于评估LLM在计算机科学领域的知识和推理能力。
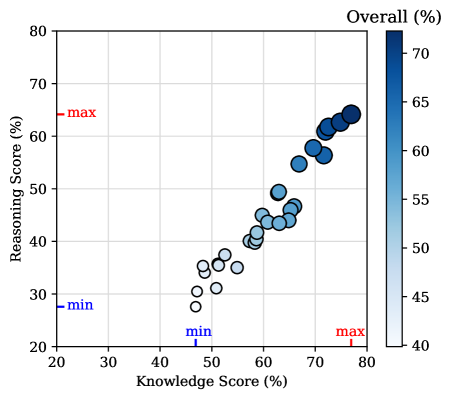
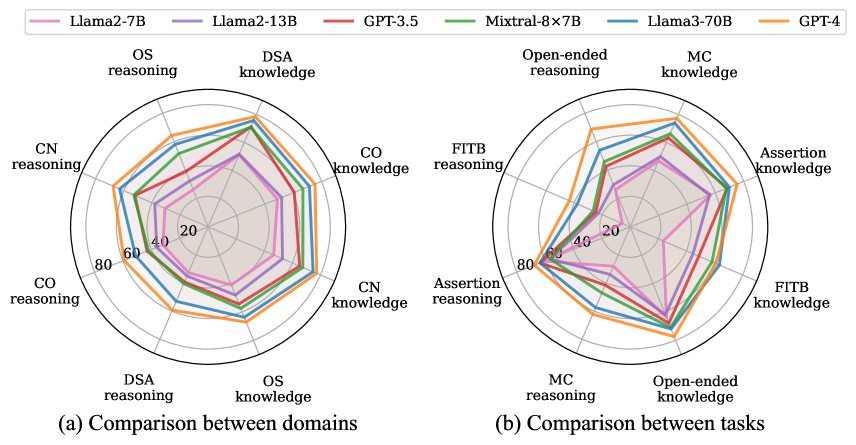
- 通过对30多个LLM的评估,CS-Bench揭示了模型规模与CS性能的关系,并指出了LLM在知识补充和CS特定推理方面的改进方向。
📝 摘要(中文)
大语言模型(LLMs)在推动各个领域的研究和社会进步方面展现出巨大的潜力。然而,当前LLM社区过度关注分析特定基础技能(例如数学和代码生成)的基准,而忽略了对计算机科学领域的全面评估。为了弥合这一差距,我们推出了CS-Bench,这是第一个致力于评估LLM在计算机科学领域性能的多语言(英语、中文、法语、德语)基准。CS-Bench包含大约1万个精心策划的测试样本,涵盖计算机科学的4个关键领域中的26个子领域,包括各种任务形式以及知识和推理的划分。利用CS-Bench,我们对30多个主流LLM进行了全面评估,揭示了CS性能与模型规模之间的关系。我们还定量分析了现有LLM失败的原因,并强调了改进的方向,包括知识补充和CS特定的推理。进一步的跨能力实验表明,LLM在计算机科学方面的能力与其在数学和编码方面的能力之间存在高度相关性。此外,专门从事数学和编码的专家LLM在几个CS子领域也表现出强大的性能。展望未来,我们设想CS-Bench将成为LLM在CS领域应用的基础,并为评估LLM多样化推理能力开辟新途径。CS-Bench数据和评估代码可在https://github.com/csbench/csbench获得。
🔬 方法详解
问题定义:现有的大语言模型评测基准在计算机科学领域的覆盖范围不足,缺乏一个全面、多语言的评测工具来评估模型在该领域的知识和推理能力。现有方法难以细粒度地分析模型在不同CS子领域的表现,也无法有效指导模型在CS领域的改进方向。
核心思路:CS-Bench的核心思路是构建一个包含多个CS子领域、多种任务形式的综合性评测基准,通过对LLM在该基准上的表现进行评估,从而全面了解模型在CS领域的知识掌握程度和推理能力。该基准的设计旨在覆盖CS领域的关键知识点和技能,并提供多语言支持,以适应不同地区的研究需求。
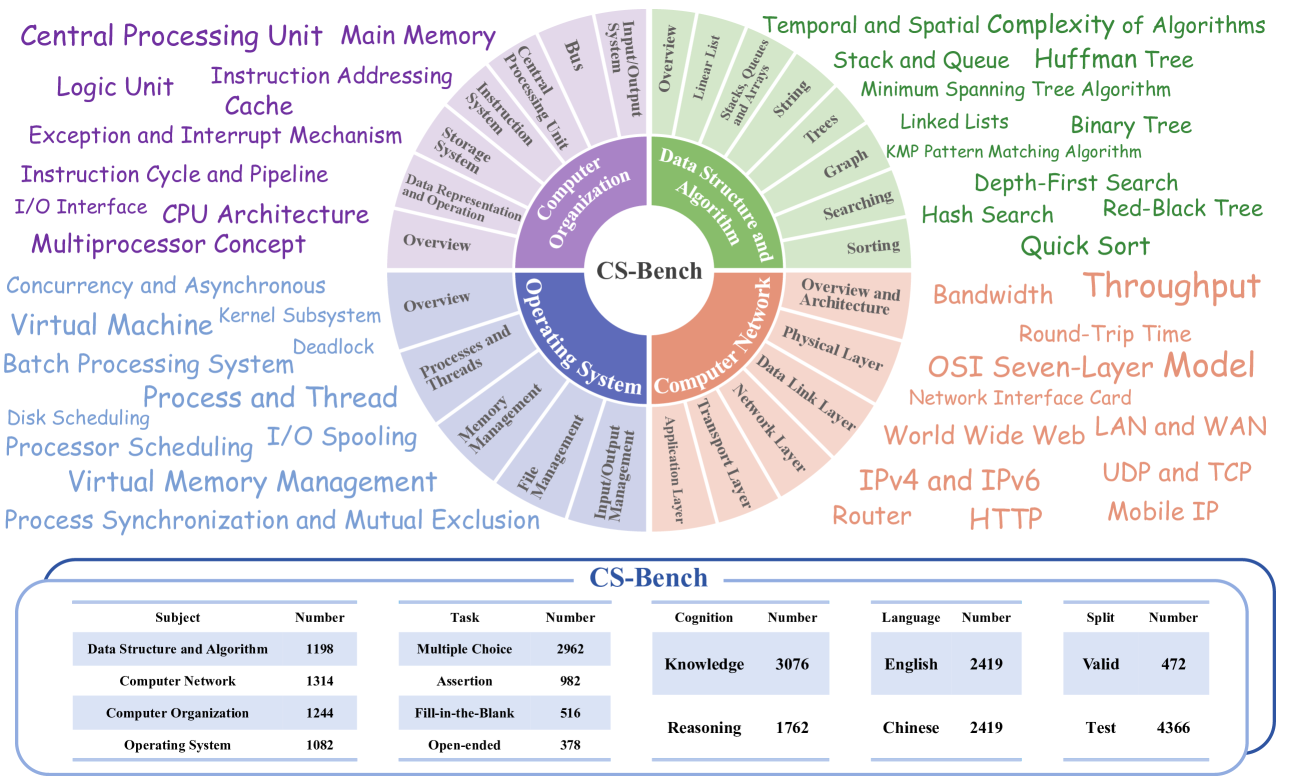
技术框架:CS-Bench包含四个关键领域(理论计算机科学、软件工程、计算机系统、人工智能)的26个子领域。每个子领域包含多个测试样本,涵盖不同的任务形式,例如选择题、代码生成、文本生成等。评估流程包括:1) 将测试样本输入到LLM中;2) 根据预定义的评估指标,对LLM的输出进行评分;3) 对评估结果进行分析,从而了解LLM在不同CS子领域的表现。
关键创新:CS-Bench的主要创新在于其全面性和多语言支持。它不仅覆盖了CS领域的多个关键子领域,还提供了英语、中文、法语、德语等多语言版本,从而可以更广泛地评估LLM在不同语言环境下的CS能力。此外,CS-Bench还提供了详细的评估指标和分析工具,方便研究人员深入了解LLM的优缺点。
关键设计:CS-Bench的数据集构建过程中,采用了专家标注和数据增强等技术,以保证数据集的质量和多样性。评估指标包括准确率、BLEU、ROUGE等,根据不同的任务形式选择合适的指标。在模型评估过程中,采用了零样本学习和少样本学习等方法,以评估LLM在不同条件下的表现。
🖼️ 关键图片
📊 实验亮点
CS-Bench对30多个主流LLM进行了评估,结果表明,模型规模与CS性能之间存在正相关关系。专门从事数学和编码的专家LLM在某些CS子领域表现出色。实验还揭示了现有LLM在知识补充和CS特定推理方面的不足,为未来的研究提供了方向。
🎯 应用场景
CS-Bench可用于评估和比较不同LLM在计算机科学领域的性能,指导LLM在CS领域的应用开发,例如智能编程助手、自动化代码生成、智能教育等。该基准还可以促进LLM在CS领域的知识迁移和推理能力提升,推动人工智能在计算机科学领域的更广泛应用。
📄 摘要(原文)
Large language models (LLMs) have demonstrated significant potential in advancing various fields of research and society. However, the current community of LLMs overly focuses on benchmarks for analyzing specific foundational skills (e.g. mathematics and code generation), neglecting an all-round evaluation of the computer science field. To bridge this gap, we introduce CS-Bench, the first multilingual (English, Chinese, French, German) benchmark dedicated to evaluating the performance of LLMs in computer science. CS-Bench comprises approximately 10K meticulously curated test samples, covering 26 subfields across 4 key areas of computer science, encompassing various task forms and divisions of knowledge and reasoning. Utilizing CS-Bench, we conduct a comprehensive evaluation of over 30 mainstream LLMs, revealing the relationship between CS performance and model scales. We also quantitatively analyze the reasons for failures in existing LLMs and highlight directions for improvements, including knowledge supplementation and CS-specific reasoning. Further cross-capability experiments show a high correlation between LLMs' capabilities in computer science and their abilities in mathematics and coding. Moreover, expert LLMs specialized in mathematics and coding also demonstrate strong performances in several CS subfields. Looking ahead, we envision CS-Bench serving as a cornerstone for LLM applications in the CS field and paving new avenues in assessing LLMs' diverse reasoning capabilities. The CS-Bench data and evaluation code are available at https://github.com/csbench/csbench.