TasTe: Teaching Large Language Models to Translate through Self-Reflection
作者: Yutong Wang, Jiali Zeng, Xuebo Liu, Fandong Meng, Jie Zhou, Min Zhang
分类: cs.CL, cs.AI
发布日期: 2024-06-12
备注: This paper has been accepted to the ACL 2024 main conference
🔗 代码/项目: GITHUB
💡 一句话要点
TasTe:通过自反思教学大型语言模型进行翻译
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 机器翻译 自反思 指令调优 神经机器翻译
📋 核心要点
- 现有基于LLM的机器翻译方法,简单提示难以充分利用LLM的指令遵循能力,导致翻译质量不如监督NMT系统。
- TasTe框架通过自反思过程,让LLM先生成初步翻译并自我评估,再根据评估结果改进翻译,从而提升翻译质量。
- 在WMT22基准测试中,TasTe框架在四个语言方向上均表现出优于现有方法的性能,证明了其有效性。
📝 摘要(中文)
大型语言模型(LLMs)在各种自然语言处理任务中表现出卓越的性能。指令调优等技术有效地提高了LLMs在机器翻译下游任务中的熟练程度。然而,现有方法未能产生与监督神经机器翻译(NMT)系统质量相匹配的令人满意的翻译输出。造成这种差异的一个可能解释是,这些方法中采用的简单提示无法充分利用所获得的指令遵循能力。为此,我们提出了TasTe框架,它代表通过自反思进行翻译。自反思过程包括两个阶段的推理。在第一阶段,指示LLMs生成初步翻译并同时对这些翻译进行自我评估。在第二阶段,任务是LLMs根据评估结果改进这些初步翻译。在WMT22基准测试中,四种语言方向的评估结果揭示了我们的方法相对于现有方法的有效性。我们的工作提出了一种有前景的方法来释放LLMs的潜力并增强其在机器翻译中的能力。代码和数据集已在https://github.com/YutongWang1216/ReflectionLLMMT上开源。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLMs)在机器翻译任务中,由于简单提示无法充分利用其指令遵循能力,导致翻译质量无法与监督神经机器翻译(NMT)系统相媲美的问题。现有方法的痛点在于,它们未能有效地引导LLMs进行高质量的翻译。
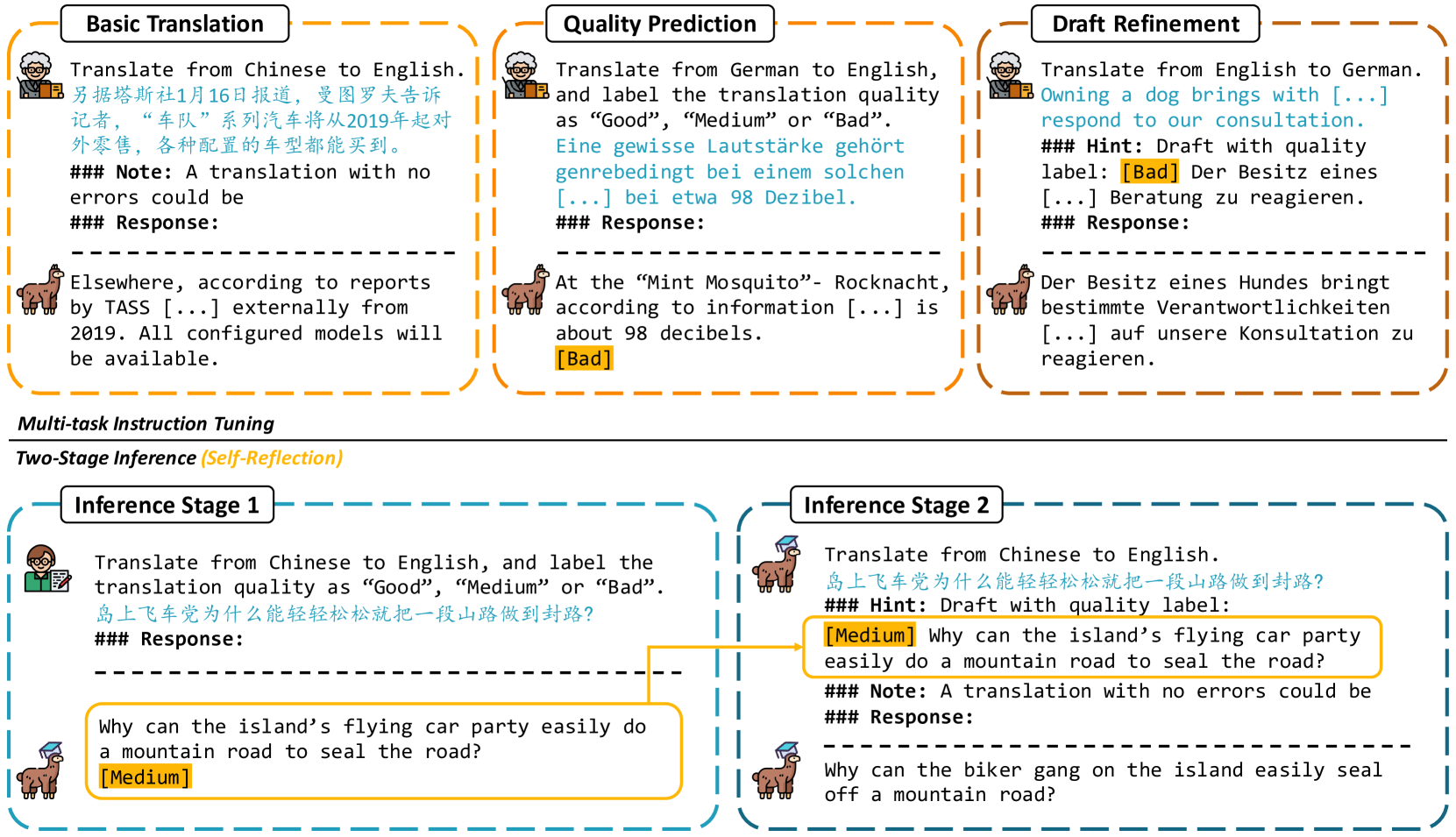
核心思路:论文的核心思路是引入“自反思”机制,让LLM在翻译过程中进行自我评估和改进。通过让LLM首先生成初步翻译,然后对其进行自我评估,最后根据评估结果进行改进,从而提高翻译质量。这种方法模拟了人类翻译员的自我检查和修正过程。
技术框架:TasTe框架包含两个主要阶段:初步翻译与自我评估阶段和翻译改进阶段。在第一阶段,LLM接收翻译指令,生成初步翻译,并同时对该翻译进行自我评估(例如,流畅性、准确性等)。在第二阶段,LLM接收初步翻译和自我评估结果,并根据评估结果对初步翻译进行改进,生成最终翻译。
关键创新:TasTe框架的关键创新在于引入了自反思机制,将LLM的翻译过程分解为生成、评估和改进三个步骤。这种方法不同于以往直接使用简单提示进行翻译的方法,它能够更有效地利用LLM的指令遵循能力,从而提高翻译质量。此外,自我评估过程可以帮助LLM更好地理解翻译任务的要求,并针对性地进行改进。
关键设计:论文中,自我评估的具体指标(如流畅性、准确性)以及评估结果的表示形式(例如,评分或文本描述)是关键设计。此外,如何将自我评估结果有效地融入到翻译改进阶段,例如,通过调整LLM的注意力机制或使用特定的提示语,也是重要的技术细节。具体的参数设置、损失函数和网络结构等细节在论文中可能没有详细描述,属于未知内容。
🖼️ 关键图片


📊 实验亮点
论文在WMT22基准测试的四个语言方向上验证了TasTe框架的有效性。实验结果表明,TasTe框架能够显著提高LLM的翻译质量,优于现有的基于LLM的翻译方法。具体的性能提升数据需要在论文中查找,这里无法给出确切的数值。
🎯 应用场景
TasTe框架具有广泛的应用前景,可应用于机器翻译、文本摘要、对话生成等自然语言处理任务。该方法可以提高LLM在这些任务中的性能,并降低对人工标注数据的依赖。此外,自反思机制还可以应用于其他领域,例如,代码生成、图像生成等,以提高生成内容的质量和可靠性。
📄 摘要(原文)
Large language models (LLMs) have exhibited remarkable performance in various natural language processing tasks. Techniques like instruction tuning have effectively enhanced the proficiency of LLMs in the downstream task of machine translation. However, the existing approaches fail to yield satisfactory translation outputs that match the quality of supervised neural machine translation (NMT) systems. One plausible explanation for this discrepancy is that the straightforward prompts employed in these methodologies are unable to fully exploit the acquired instruction-following capabilities. To this end, we propose the TasTe framework, which stands for translating through self-reflection. The self-reflection process includes two stages of inference. In the first stage, LLMs are instructed to generate preliminary translations and conduct self-assessments on these translations simultaneously. In the second stage, LLMs are tasked to refine these preliminary translations according to the evaluation results. The evaluation results in four language directions on the WMT22 benchmark reveal the effectiveness of our approach compared to existing methods. Our work presents a promising approach to unleash the potential of LLMs and enhance their capabilities in MT. The codes and datasets are open-sourced at https://github.com/YutongWang1216/ReflectionLLMMT.