REAL Sampling: Boosting Factuality and Diversity of Open-Ended Generation via Asymptotic Entropy
作者: Haw-Shiuan Chang, Nanyun Peng, Mohit Bansal, Anil Ramakrishna, Tagyoung Chung
分类: cs.CL, cs.LG
发布日期: 2024-06-11
💡 一句话要点
提出REAL采样以解决开放式生成中的事实性与多样性问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 开放式生成 事实性 多样性 渐近熵 幻觉预测 自然语言处理 语言模型 采样方法
📋 核心要点
- 现有的解码方法在确保生成文本的事实性与多样性之间存在显著的权衡,难以同时满足两者的需求。
- 本文提出的REAL采样方法通过动态调整p阈值,依据LLM的幻觉概率来优化生成文本的事实性和多样性。
- 实验结果表明,REAL采样在FactualityPrompts基准测试中显著提升了生成文本的事实性和多样性,超越了多种现有采样方法。
📝 摘要(中文)
大型语言模型(LLMs)的解码方法通常面临确保事实性与保持多样性之间的权衡。本文提出REAL(来自渐近熵的残差)采样,通过预测自适应的p阈值,改善了事实性和多样性。具体而言,REAL采样预测LLM的幻觉发生概率,并在可能幻觉时降低p阈值,反之则提高p阈值以增强多样性。为无监督地预测逐步幻觉概率,构建了Token级幻觉预测模型(THF),通过外推不同规模LLM的下一个token熵来预测渐近熵。在FactualityPrompts基准测试中,基于70M THF模型的REAL采样显著提升了7B LLM的事实性和多样性,且在对比解码结合下,REAL采样超越了9种采样方法,生成的文本比贪婪采样更具事实性,比p=0.5的核采样更具多样性。
🔬 方法详解
问题定义:本文旨在解决大型语言模型在开放式生成任务中,事实性与多样性之间的权衡问题。现有的核采样方法在提高多样性时,往往会导致生成文本的事实性下降,反之亦然。
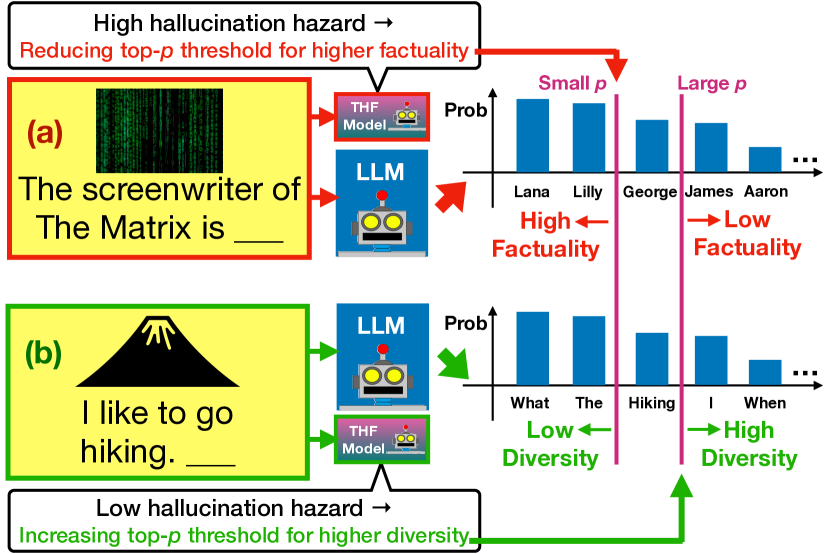
核心思路:REAL采样的核心思想是通过预测LLM的幻觉发生概率,动态调整p阈值。当模型可能产生幻觉时,降低p阈值以确保事实性;而在模型较为确定时,提高p阈值以增强生成文本的多样性。
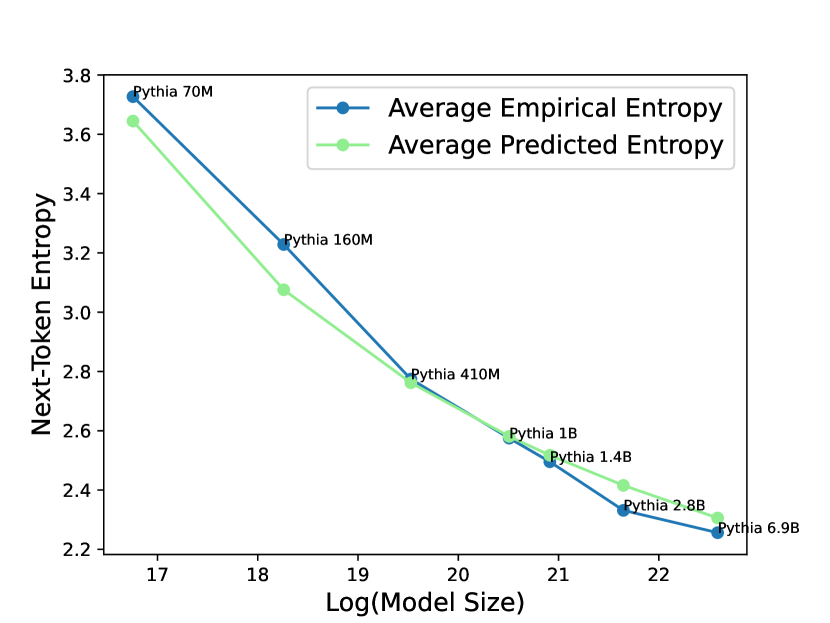
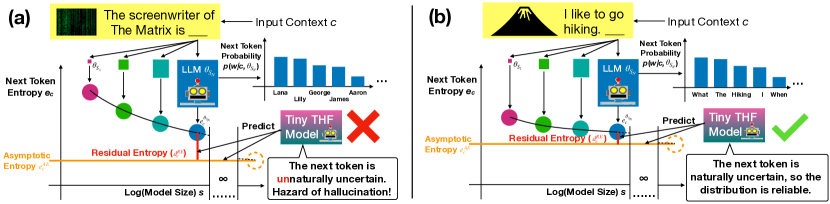
技术框架:REAL采样的整体架构包括两个主要模块:Token级幻觉预测模型(THF)和自适应p阈值调整机制。THF模型负责预测下一个token的渐近熵,进而判断模型的幻觉风险。
关键创新:REAL采样的创新之处在于引入了渐近熵的概念,通过无监督学习的方式,利用不同规模的LLM的熵信息来预测幻觉概率,从而实现动态的p阈值调整。这一方法与传统的固定p阈值采样方法本质上有所不同。
关键设计:在设计中,THF模型通过外推不同规模LLM的下一个token熵来计算渐近熵,并根据熵值的高低来调整p阈值。此外,结合对比解码的策略进一步提升了生成文本的质量。
🖼️ 关键图片
📊 实验亮点
实验结果显示,基于70M THF模型的REAL采样在FactualityPrompts基准测试中显著提升了7B LLM的事实性和多样性,超越了9种对比采样方法。具体而言,REAL采样生成的文本在事实性上优于贪婪采样,在多样性上优于p=0.5的核采样,展现出良好的综合性能。
🎯 应用场景
该研究的潜在应用领域包括对话系统、内容生成和自动摘要等自然语言处理任务。通过提升生成文本的事实性和多样性,REAL采样能够在实际应用中提供更高质量的文本输出,满足用户对信息准确性和多样性的需求。未来,该方法有望在更广泛的生成任务中得到应用,推动自然语言生成技术的发展。
📄 摘要(原文)
Decoding methods for large language models (LLMs) usually struggle with the tradeoff between ensuring factuality and maintaining diversity. For example, a higher p threshold in the nucleus (top-p) sampling increases the diversity but decreases the factuality, and vice versa. In this paper, we propose REAL (Residual Entropy from Asymptotic Line) sampling, a decoding method that achieves improved factuality and diversity over nucleus sampling by predicting an adaptive threshold of $p$. Specifically, REAL sampling predicts the step-wise likelihood of an LLM to hallucinate, and lowers the p threshold when an LLM is likely to hallucinate. Otherwise, REAL sampling increases the p threshold to boost the diversity. To predict the step-wise hallucination likelihood without supervision, we construct a Token-level Hallucination Forecasting (THF) model to predict the asymptotic entropy (i.e., inherent uncertainty) of the next token by extrapolating the next-token entropies from a series of LLMs with different sizes. If a LLM's entropy is higher than the asymptotic entropy (i.e., the LLM is more uncertain than it should be), the THF model predicts a high hallucination hazard, which leads to a lower p threshold in REAL sampling. In the FactualityPrompts benchmark, we demonstrate that REAL sampling based on a 70M THF model can substantially improve the factuality and diversity of 7B LLMs simultaneously, judged by both retrieval-based metrics and human evaluation. After combined with contrastive decoding, REAL sampling outperforms 9 sampling methods, and generates texts that are more factual than the greedy sampling and more diverse than the nucleus sampling with $p=0.5$. Furthermore, the predicted asymptotic entropy is also a useful unsupervised signal for hallucination detection tasks.