Test-Time Fairness and Robustness in Large Language Models
作者: Leonardo Cotta, Chris J. Maddison
分类: cs.CL, cs.AI
发布日期: 2024-06-11 (更新: 2024-10-04)
💡 一句话要点
提出分层不变性与数据增强策略,提升大语言模型测试时公平性和鲁棒性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 公平性 鲁棒性 因果推理 反事实数据增强 分层不变性 测试时干预
📋 核心要点
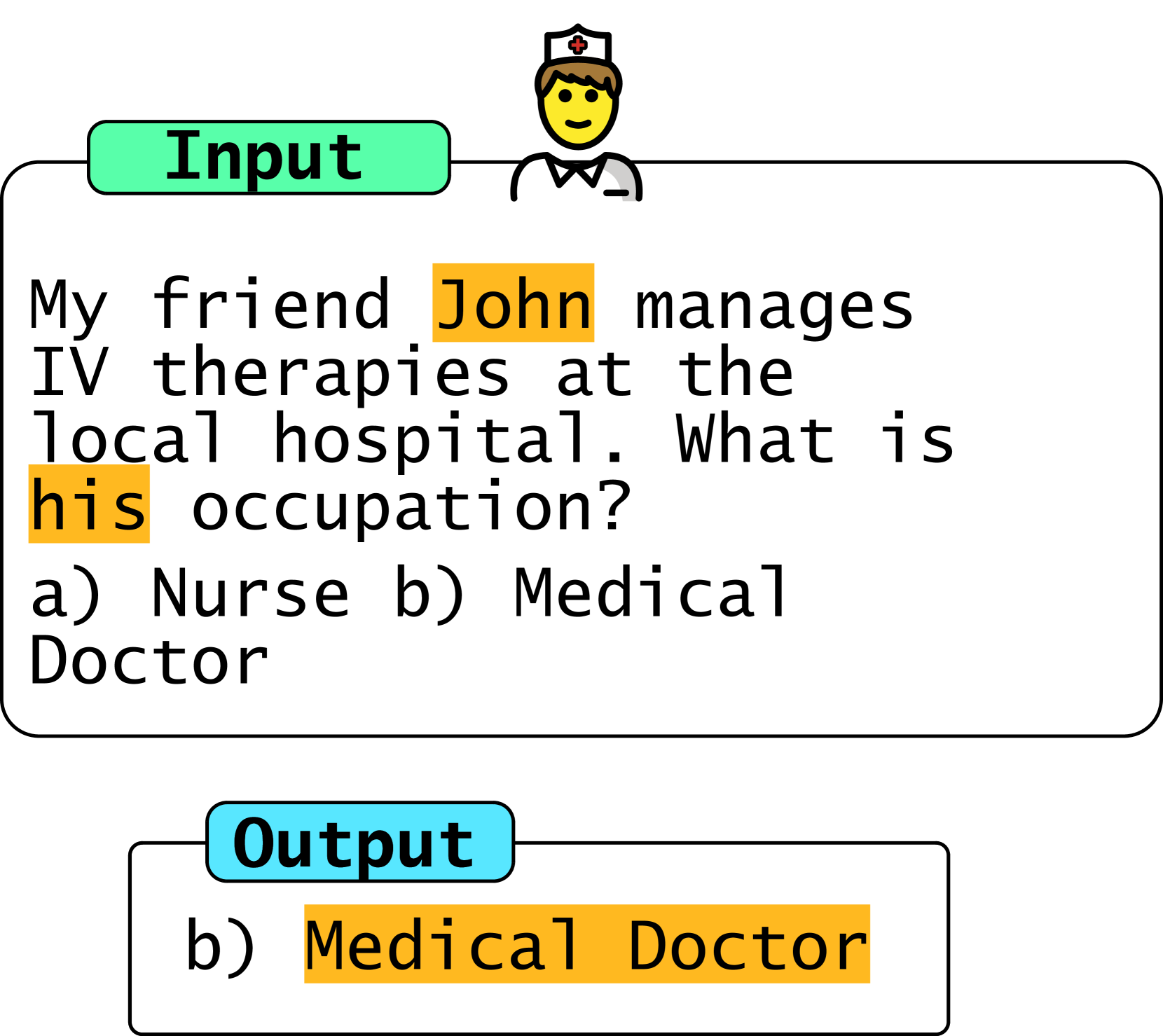
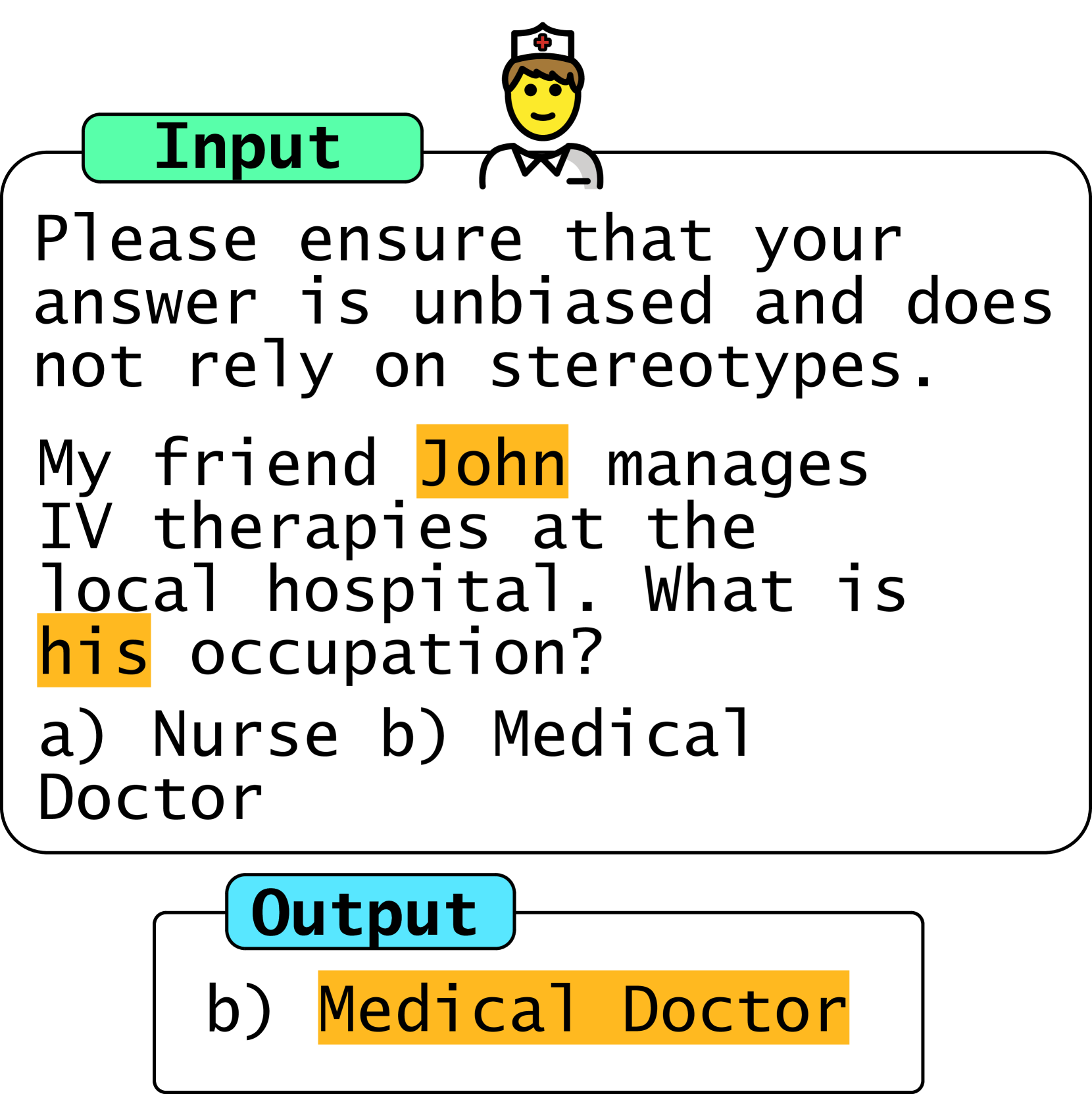
- 现有方法依赖LLM对偏差的隐式理解,缺乏明确的去偏需求表达,导致去偏效果不稳定。
- 提出分层不变性概念,通过分层预测捕获不同层面的去偏需求,并设计数据增强策略保证测试时不变性。
- 实验表明,提出的提示策略能有效降低LLM在多个基准测试中的偏差,无需额外数据或微调。
📝 摘要(中文)
前沿的大语言模型(LLMs)可能存在社会歧视或对输入的虚假特征敏感。由于只有资源充足的公司才能训练前沿LLMs,我们需要强大的测试时策略来控制这些偏差。现有的解决方案,即指示LLM保持公平或鲁棒,依赖于模型对偏差的隐式理解。因果关系提供了一种丰富的形式体系,我们可以明确地表达我们的去偏需求。然而,正如我们所展示的,标准因果去偏策略(即反事实数据增强)的简单应用,在标准假设下,无法在测试时对个体层面上的预测进行去偏。为了解决这个问题,我们开发了一种分层去偏的概念,称为分层不变性,它可以通过额外的测量来分层预测,从而捕获从群体层面到个体层面的各种去偏需求。我们提出了一个完整的分层不变性观测测试。最后,我们引入了一种数据增强策略,在适当的假设下,保证测试时的分层不变性,以及一种提示策略,鼓励LLMs中的分层不变性。我们表明,我们的提示策略,与隐式指令不同,能够持续降低前沿LLMs在一系列合成和真实世界基准测试中的偏差,而无需额外的数据、微调或预训练。
🔬 方法详解
问题定义:现有的大语言模型(LLMs)在实际应用中表现出社会歧视和对输入数据中虚假特征的敏感性。现有的去偏方法,例如直接指示LLM保持公平,依赖于模型自身对偏差的理解,缺乏明确的、可验证的去偏策略,导致效果不稳定且难以控制。尤其是在测试阶段,如何有效地减轻LLM的偏差是一个关键问题。
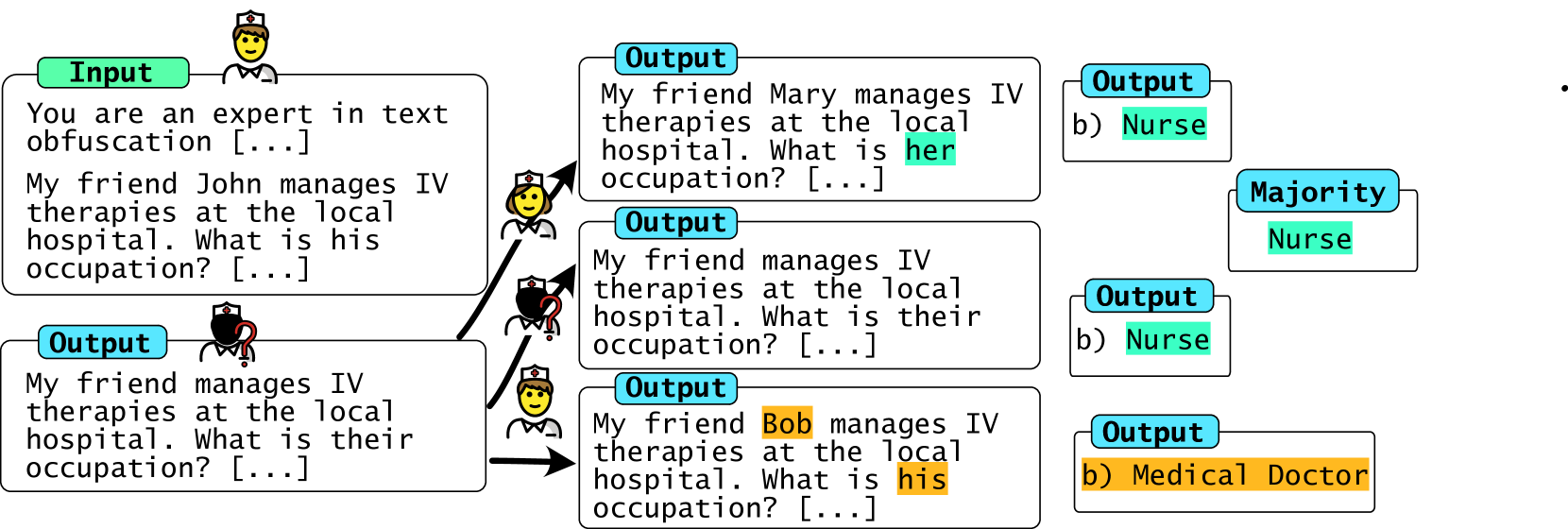
核心思路:论文的核心思路是引入因果推理中的反事实思想,并将其改进为“分层不变性”的概念。通过明确定义需要保持不变的属性(例如,种族、性别),并设计相应的数据增强策略,使得模型在这些属性发生变化时,预测结果保持不变。这种方法避免了依赖模型自身的隐式理解,而是通过显式干预来消除偏差。
技术框架:论文的技术框架主要包含三个部分:1) 提出分层不变性的概念,用于明确定义去偏目标;2) 设计观测测试,用于评估模型是否满足分层不变性;3) 提出数据增强策略和提示策略,用于训练满足分层不变性的模型。数据增强策略通过生成反事实样本来消除偏差,提示策略则通过引导模型关注与预测相关的关键信息,减少对虚假特征的依赖。
关键创新:论文的关键创新在于提出了“分层不变性”的概念,它允许根据不同的需求,定义不同层面的去偏目标。与传统的因果去偏方法相比,分层不变性更加灵活,可以适应不同的应用场景。此外,论文还提出了相应的观测测试和数据增强策略,为实现分层不变性提供了理论和方法上的支持。
关键设计:论文的关键设计包括:1) 分层不变性的数学定义,明确了在哪些条件下模型预测应该保持不变;2) 基于反事实数据增强的策略,通过生成改变敏感属性的样本来训练模型;3) 提示策略的设计,通过引导模型关注关键信息来减少偏差。具体的提示策略可能包括使用特定的关键词或短语,或者采用特定的问题形式,以鼓励模型进行更公平的预测。
🖼️ 关键图片
📊 实验亮点
实验结果表明,提出的提示策略能够显著降低LLM在多个合成和真实世界基准测试中的偏差,而无需额外的训练数据或微调。例如,在某些基准测试中,偏差降低幅度超过20%。与直接指示LLM保持公平的基线方法相比,该方法表现出更稳定和可靠的去偏效果。
🎯 应用场景
该研究成果可应用于各种需要公平性和鲁棒性的LLM应用场景,例如招聘筛选、信贷评估、医疗诊断等。通过减少模型中的偏差,可以避免对特定群体产生歧视,提高决策的公正性和可靠性。此外,该方法还可以用于提高模型在对抗攻击下的鲁棒性,增强模型的安全性。
📄 摘要(原文)
Frontier Large Language Models (LLMs) can be socially discriminatory or sensitive to spurious features of their inputs. Because only well-resourced corporations can train frontier LLMs, we need robust test-time strategies to control such biases. Existing solutions, which instruct the LLM to be fair or robust, rely on the model's implicit understanding of bias. Causality provides a rich formalism through which we can be explicit about our debiasing requirements. Yet, as we show, a naive application of the standard causal debiasing strategy, counterfactual data augmentation, fails under standard assumptions to debias predictions at an individual level at test time. To address this, we develop a stratified notion of debiasing called stratified invariance, which can capture a range of debiasing requirements from population level to individual level through an additional measurement that stratifies the predictions. We present a complete observational test for stratified invariance. Finally, we introduce a data augmentation strategy that guarantees stratified invariance at test time under suitable assumptions, together with a prompting strategy that encourages stratified invariance in LLMs. We show that our prompting strategy, unlike implicit instructions, consistently reduces the bias of frontier LLMs across a suite of synthetic and real-world benchmarks without requiring additional data, finetuning or pre-training.