GameBench: Evaluating Strategic Reasoning Abilities of LLM Agents
作者: Anthony Costarelli, Mat Allen, Roman Hauksson, Grace Sodunke, Suhas Hariharan, Carlson Cheng, Wenjie Li, Joshua Clymer, Arjun Yadav
分类: cs.CL, cs.AI
发布日期: 2024-06-07 (更新: 2024-07-22)
💡 一句话要点
GameBench:提出用于评估LLM智能体战略推理能力的跨领域基准测试
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 战略推理 游戏AI 基准测试 智能体评估
📋 核心要点
- 现有方法缺乏对LLM智能体在复杂战略游戏中推理能力的全面评估框架。
- GameBench通过构建跨领域游戏基准,评估LLM在不同战略维度上的推理能力。
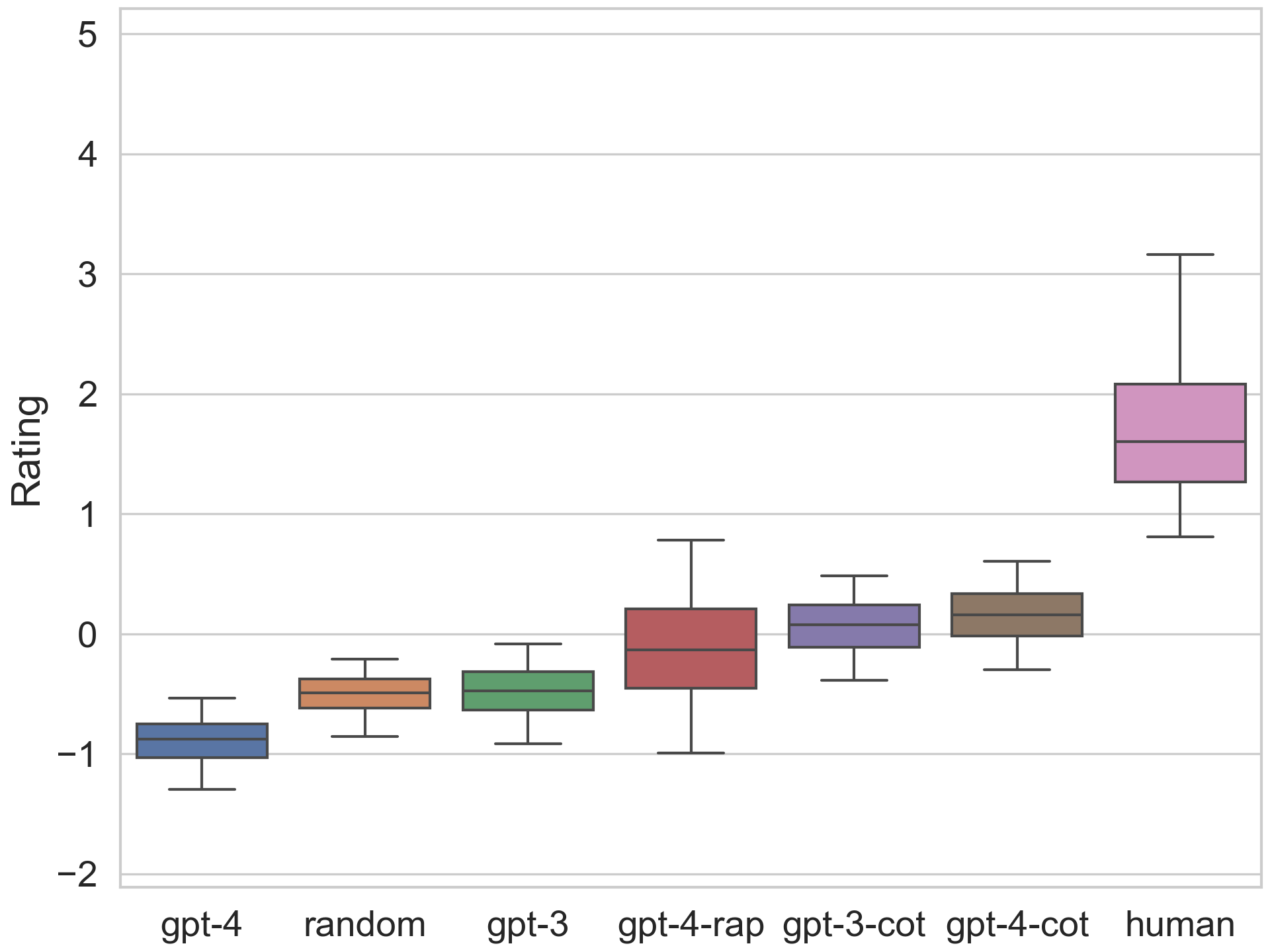
- 实验表明,即使使用CoT和RAP等增强方法,LLM的战略推理能力仍远低于人类水平。
📝 摘要(中文)
大型语言模型(LLM)在许多自然语言理解任务中表现出了卓越的少样本学习能力。尽管已有多个演示表明LLM可用于复杂的战略场景,但仍然缺乏一个全面的框架来评估智能体在游戏中各种推理类型中的表现。为了解决这一差距,我们推出了GameBench,这是一个跨领域基准测试,用于评估LLM智能体的战略推理能力。我们专注于9种不同的游戏环境,每种环境至少涵盖了战略游戏中关键推理技能的一个维度,并选择了策略解释不太可能构成模型预训练语料库重要组成部分的游戏。我们的评估使用了基础形式的GPT-3和GPT-4,以及两种旨在增强战略推理能力的支架框架:思维链(CoT)提示和通过规划进行推理(RAP)。我们的结果表明,没有一个经过测试的模型能达到人类的表现水平,最糟糕的情况下,GPT-4的表现甚至不如随机行动。CoT和RAP都提高了分数,但仍无法与人类水平相提并论。
🔬 方法详解
问题定义:论文旨在解决缺乏系统性方法评估大型语言模型(LLM)在复杂战略游戏中进行战略推理能力的问题。现有方法要么是针对特定游戏,要么缺乏对不同推理维度的覆盖,无法全面评估LLM的战略智能。此外,现有评估方法难以排除LLM通过预训练数据记忆游戏策略的可能性。
核心思路:论文的核心思路是构建一个跨领域的游戏基准测试集,该测试集包含多种不同类型的游戏,每种游戏侧重于不同的战略推理技能。通过在这些游戏上评估LLM的表现,可以更全面地了解LLM的战略推理能力。同时,选择策略解释不太可能出现在预训练语料库中的游戏,以减少模型记忆的影响。
技术框架:GameBench框架包含以下几个主要组成部分: 1. 游戏选择:选择9个不同的游戏环境,每个游戏侧重于不同的战略推理技能,例如资源管理、博弈论、空间推理等。 2. LLM智能体:使用GPT-3和GPT-4作为基础模型,并结合Chain-of-Thought (CoT) prompting和Reasoning Via Planning (RAP)两种策略增强框架。 3. 评估指标:使用游戏得分作为主要评估指标,并与人类玩家的表现进行对比。 4. 实验设计:设计不同的实验场景,例如零样本学习、少样本学习等,以评估LLM在不同条件下的表现。
关键创新:GameBench的关键创新在于其跨领域性和对战略推理技能的细粒度评估。与以往的研究相比,GameBench不仅涵盖了多种不同类型的游戏,而且还关注了游戏中不同的战略推理维度。此外,GameBench还使用了CoT和RAP等策略增强框架,以提高LLM的战略推理能力。
关键设计: * 游戏选择:选择了9个游戏,确保覆盖不同的战略推理技能,并且策略解释不太可能出现在模型的预训练数据中。 * 提示工程:使用了CoT和RAP两种提示策略来引导LLM进行战略推理。CoT提示通过逐步推理来提高LLM的推理能力,而RAP则通过规划来实现更长远的战略目标。 * 评估指标:使用游戏得分作为主要评估指标,并与人类玩家的表现进行对比,以评估LLM的战略推理能力。
🖼️ 关键图片


📊 实验亮点
实验结果表明,即使使用CoT和RAP等增强方法,GPT-3和GPT-4在GameBench上的表现仍然远低于人类水平,甚至在某些情况下不如随机行动。CoT和RAP能够提高LLM的得分,但提升幅度有限。这表明LLM在战略推理方面仍然存在很大的提升空间,需要进一步的研究和开发。
🎯 应用场景
GameBench的研究成果可应用于开发更智能的AI游戏智能体,提升游戏体验。此外,该基准测试也可用于评估和改进LLM在其他需要战略推理能力的领域的应用,例如商业决策、军事战略和机器人导航等。未来,GameBench可以扩展到更多游戏和领域,并开发更复杂的评估指标。
📄 摘要(原文)
Large language models have demonstrated remarkable few-shot performance on many natural language understanding tasks. Despite several demonstrations of using large language models in complex, strategic scenarios, there lacks a comprehensive framework for evaluating agents' performance across various types of reasoning found in games. To address this gap, we introduce GameBench, a cross-domain benchmark for evaluating strategic reasoning abilities of LLM agents. We focus on 9 different game environments, where each covers at least one axis of key reasoning skill identified in strategy games, and select games for which strategy explanations are unlikely to form a significant portion of models' pretraining corpuses. Our evaluations use GPT-3 and GPT-4 in their base form along with two scaffolding frameworks designed to enhance strategic reasoning ability: Chain-of-Thought (CoT) prompting and Reasoning Via Planning (RAP). Our results show that none of the tested models match human performance, and at worst GPT-4 performs worse than random action. CoT and RAP both improve scores but not comparable to human levels.