Multi-Head RAG: Solving Multi-Aspect Problems with LLMs
作者: Maciej Besta, Ales Kubicek, Robert Gerstenberger, Marcin Chrapek, Roman Niggli, Patrik Okanovic, Yi Zhu, Patrick Iff, Michal Podstawski, Lucas Weitzendorf, Mingyuan Chi, Joanna Gajda, Piotr Nyczyk, Jürgen Müller, Hubert Niewiadomski, Torsten Hoefler
分类: cs.CL, cs.AI, cs.IR
发布日期: 2024-06-07 (更新: 2025-09-29)
💡 一句话要点
提出Multi-Head RAG,利用多头注意力解决LLM在多方面问题上的检索增强生成。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 检索增强生成 多头注意力 大型语言模型 信息检索 Transformer模型
📋 核心要点
- 现有RAG方法在处理需要检索多个内容差异大文档的复杂查询时存在不足,难以有效检索相关信息。
- Multi-Head RAG利用Transformer多头注意力机制,将不同注意力头的激活作为键,捕捉数据和查询的不同方面。
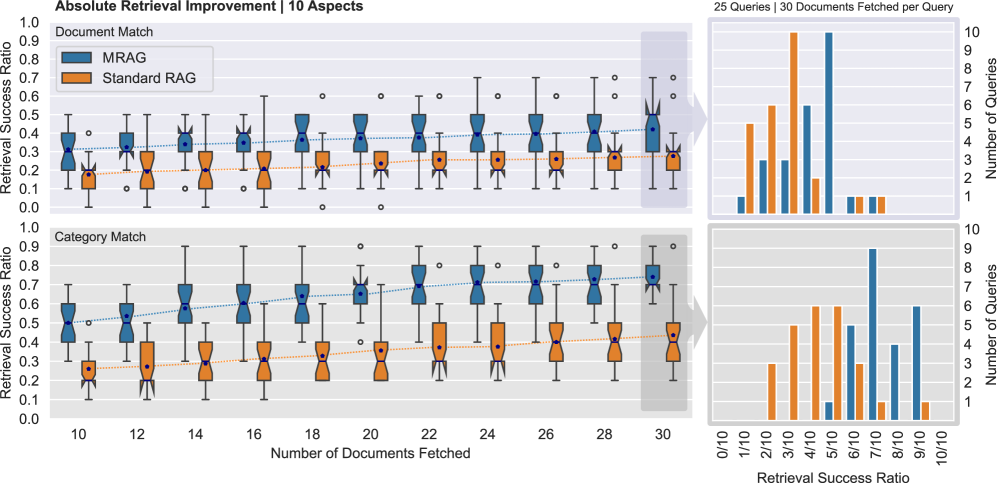
- 实验表明,MRAG在检索成功率上优于18个RAG基线,提升高达20%,并能改善下游LLM生成效果。
📝 摘要(中文)
检索增强生成(RAG)通过将文档检索到LLM上下文中,提高了大型语言模型(LLM)的能力,从而提供更准确和相关的响应。现有的RAG解决方案没有关注可能需要获取具有显著不同内容的多个文档的查询。这种查询经常出现,但具有挑战性,因为这些文档的嵌入在嵌入空间中可能相距甚远,使得难以检索到所有文档。本文介绍了一种新的方案Multi-Head RAG(MRAG),旨在通过一个简单而强大的想法来解决这一差距:利用Transformer多头注意力层的激活,而不是解码器层,作为获取多方面文档的键。驱动观察是不同的注意力头学习捕获不同的数据方面。利用相应的激活会产生代表数据项和查询的各个方面的嵌入,从而提高复杂查询的检索准确性。我们提供了一种评估方法和指标、多方面数据集和实际用例来证明MRAG的有效性。我们展示了MRAG相对于18个RAG基线的设计优势,检索成功率提高了高达20%,并为下游LLM生成带来了好处。MRAG可以与现有的RAG框架和基准无缝集成。
🔬 方法详解
问题定义:现有RAG方法在处理需要从多个不同角度检索信息的复杂查询时表现不佳。原因是这些不同角度的信息对应的文档在嵌入空间中可能距离较远,导致难以同时检索到所有相关文档。现有的RAG方法通常使用单一的嵌入向量来表示文档和查询,无法捕捉到它们的多方面特征。
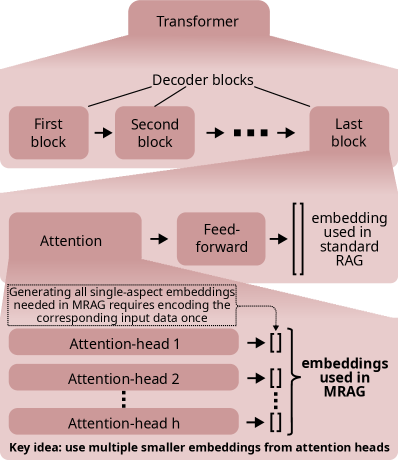
核心思路:Multi-Head RAG的核心思路是利用Transformer模型中多头注意力机制的特性,即不同的注意力头能够学习到不同的数据方面。通过将不同注意力头的激活值作为检索的键,可以捕捉到文档和查询的不同侧面,从而提高复杂查询的检索准确率。
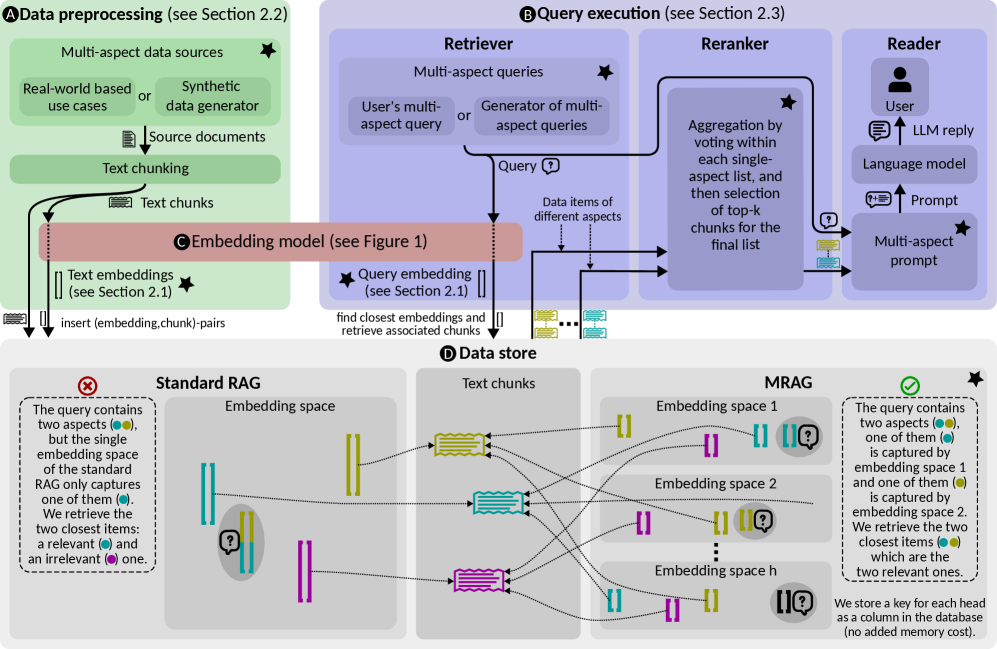
技术框架:MRAG的整体框架与标准的RAG流程类似,主要包括以下几个阶段:1) 文档编码:使用Transformer模型对文档进行编码,提取每个注意力头的激活值。2) 查询编码:使用相同的Transformer模型对查询进行编码,同样提取每个注意力头的激活值。3) 检索:使用查询的每个注意力头的激活值作为键,在文档库中检索相似的文档。4) 生成:将检索到的文档和原始查询一起输入到LLM中,生成最终的答案。
关键创新:MRAG最重要的创新点在于使用Transformer多头注意力层的激活值作为检索的键。与传统的RAG方法使用单一的嵌入向量相比,MRAG能够捕捉到文档和查询的多方面特征,从而提高复杂查询的检索准确率。这种方法充分利用了Transformer模型内部的表示能力,无需额外的训练或复杂的模型结构。
关键设计:MRAG的关键设计包括:1) 使用预训练的Transformer模型(如BERT、RoBERTa)作为编码器。2) 选择合适的注意力层和注意力头进行激活值提取。3) 使用余弦相似度等度量方法来计算查询和文档之间的相似度。4) 可以灵活地与现有的RAG框架和LLM集成。
🖼️ 关键图片
📊 实验亮点
实验结果表明,MRAG在多方面问题上的检索性能显著优于传统的RAG方法。在多个数据集上,MRAG的检索成功率提升高达20%。此外,MRAG还能够改善下游LLM的生成效果,提高生成答案的准确性和相关性。实验结果验证了MRAG在解决多方面问题上的有效性。
🎯 应用场景
Multi-Head RAG可应用于需要多方面信息检索的场景,如问答系统、智能客服、报告生成等。例如,在金融领域,分析师可能需要从多个角度(公司财务、行业趋势、宏观经济)检索信息以评估投资风险。MRAG能够更准确地检索到相关信息,辅助决策,提升效率。
📄 摘要(原文)
Retrieval Augmented Generation (RAG) enhances the abilities of Large Language Models (LLMs) by enabling the retrieval of documents into the LLM context to provide more accurate and relevant responses. Existing RAG solutions do not focus on queries that may require fetching multiple documents with substantially different contents. Such queries occur frequently, but are challenging because the embeddings of these documents may be distant in the embedding space, making it hard to retrieve them all. This paper introduces Multi-Head RAG (MRAG), a novel scheme designed to address this gap with a simple yet powerful idea: leveraging activations of Transformer's multi-head attention layer, instead of the decoder layer, as keys for fetching multi-aspect documents. The driving observation is that different attention heads learn to capture different data aspects. Harnessing the corresponding activations results in embeddings that represent various facets of data items and queries, improving the retrieval accuracy for complex queries. We provide an evaluation methodology and metrics, multi-aspect datasets, and real-world use cases to demonstrate MRAG's effectiveness. We show MRAG's design advantages over 18 RAG baselines, empirical improvements of up to 20% in retrieval success ratios, and benefits for downstream LLM generation. MRAG can be seamlessly integrated with existing RAG frameworks and benchmarks.