MEFT: Memory-Efficient Fine-Tuning through Sparse Adapter
作者: Jitai Hao, WeiWei Sun, Xin Xin, Qi Meng, Zhumin Chen, Pengjie Ren, Zhaochun Ren
分类: cs.CL
发布日期: 2024-06-07
备注: ACL 24
🔗 代码/项目: GITHUB
💡 一句话要点
MEFT:通过稀疏Adapter实现内存高效的大语言模型微调
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 参数高效微调 大语言模型 Adapter CPU卸载 激活稀疏性 混合专家模型 内存优化
📋 核心要点
- 现有PEFT方法因可训练参数数量有限,在大模型知识密集型任务微调中存在性能瓶颈。
- MEFT利用LLM激活稀疏性,将大尺寸Adapter参数存储在CPU中,实现内存高效微调。
- 通过MoE架构减少CPU计算和GPU-CPU通信,在有限资源下达到与更大内存容量相当的微调效果。
📝 摘要(中文)
参数高效微调(PEFT)技术能够在有限的资源下对大型语言模型(LLM)进行微调。然而,由于附加可训练参数数量的限制,PEFT在复杂、知识密集型任务上的微调性能受到限制。为了克服这一限制,我们提出了一种新机制,该机制使用更大尺寸但内存高效的Adapter来微调LLM。这是通过利用LLM的前馈网络(FFN)中固有的激活稀疏性,并利用中央处理器(CPU)内存比图形处理器(GPU)更大的容量来实现的。我们将更大Adapter的参数存储在CPU上并进行更新。此外,我们采用类似于混合专家(MoE)的架构来减少不必要的CPU计算,并减少GPU和CPU之间的通信量。这对于PCI Express(PCIe)的有限带宽尤其有益。即使在资源受限的情况下,例如24GB内存的单GPU设置,我们的方法也能获得与更大内存容量相当的微调结果,同时训练效率的损失是可以接受的。我们的代码可在https://github.com/CURRENTF/MEFT 获取。
🔬 方法详解
问题定义:现有参数高效微调(PEFT)方法在资源受限的情况下对大型语言模型(LLM)进行微调,但由于可训练参数数量的限制,在复杂、知识密集型任务上的微调性能受到限制。现有方法无法充分利用LLM的全部潜力,尤其是在计算资源有限的情况下,难以实现高性能。
核心思路:MEFT的核心思路是利用LLM前馈网络(FFN)中固有的激活稀疏性,并结合CPU内存大于GPU内存的特点,将更大尺寸的Adapter参数存储在CPU上进行更新。通过这种方式,可以在不显著增加GPU内存占用的前提下,增加可训练参数的数量,从而提升微调性能。
技术框架:MEFT的技术框架主要包含以下几个部分:1) 稀疏Adapter:使用更大尺寸的Adapter来增加模型容量。2) CPU参数存储:将Adapter的参数存储在CPU内存中。3) MoE-like架构:采用类似于混合专家(MoE)的架构,减少不必要的CPU计算和GPU-CPU通信。4) GPU-CPU数据传输:在GPU和CPU之间进行必要的数据传输,以更新Adapter的参数。
关键创新:MEFT的关键创新在于:1) 提出了一种利用CPU内存来扩展LLM微调容量的方法,克服了GPU内存限制。2) 结合LLM的激活稀疏性,减少了CPU计算量和GPU-CPU通信量。3) 采用MoE-like架构,进一步优化了计算效率。与现有PEFT方法相比,MEFT能够在有限的GPU资源下,实现更大的模型容量和更好的微调性能。
关键设计:MEFT的关键设计包括:1) Adapter的尺寸:需要根据具体的任务和资源情况进行调整,以达到最佳的性能和效率平衡。2) MoE-like架构的专家数量和路由策略:需要仔细设计,以确保每个专家都能学习到不同的知识,并有效地减少计算量。3) GPU-CPU数据传输的优化:需要采用高效的数据传输方法,以减少延迟和带宽占用。
🖼️ 关键图片
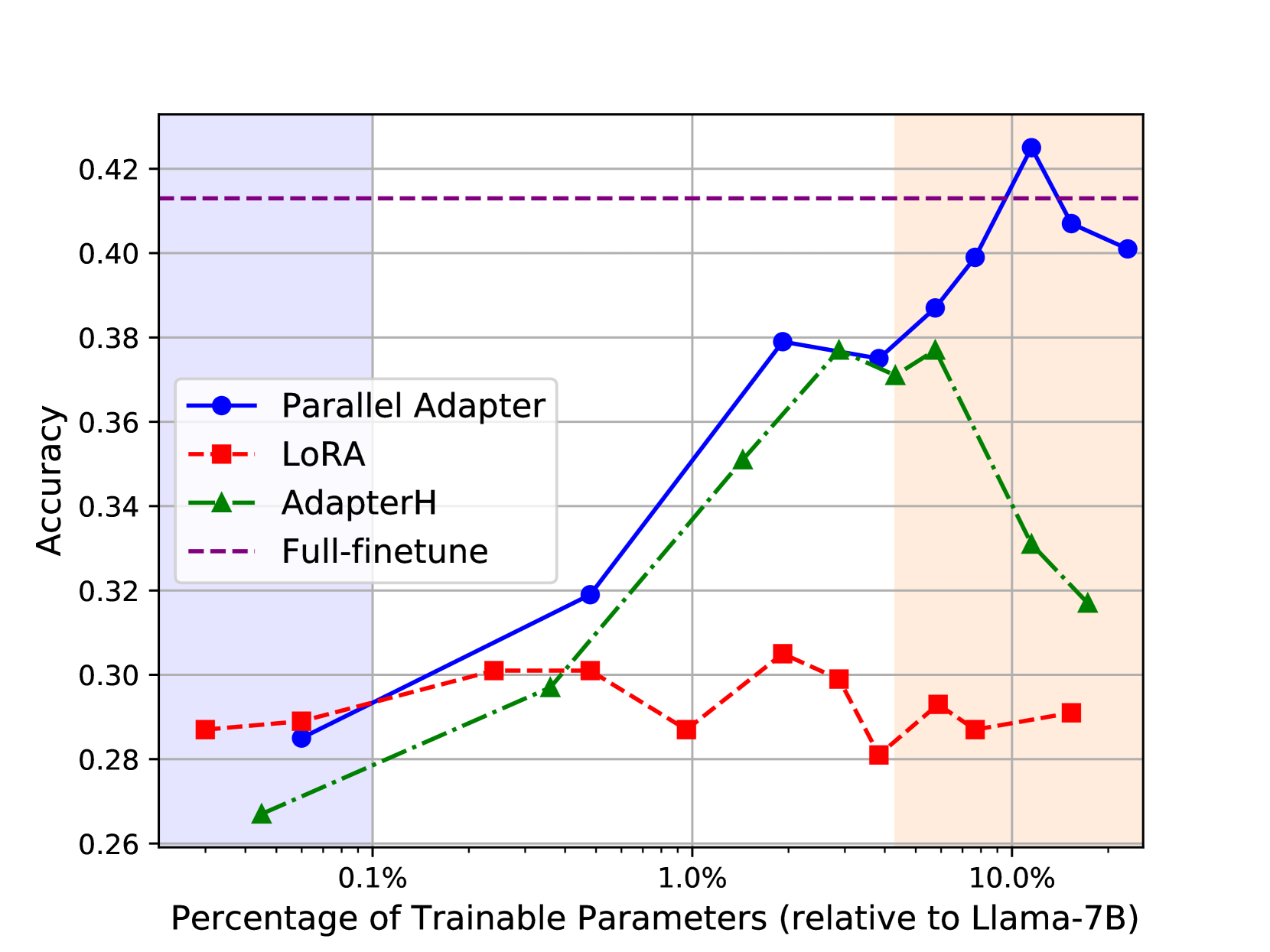


📊 实验亮点
MEFT在资源受限的24GB内存单GPU设置下,实现了与更大内存容量相当的微调结果,同时训练效率的损失是可以接受的。具体实验数据(论文中提供)表明,MEFT在多个知识密集型任务上,显著优于现有的PEFT方法,证明了其在内存效率和性能方面的优势。
🎯 应用场景
MEFT适用于各种需要对大型语言模型进行微调的场景,尤其是在计算资源有限的情况下。例如,在移动设备或边缘设备上部署LLM,或者在预算有限的实验室中进行研究。该方法可以帮助研究人员和开发人员在有限的资源下,充分利用LLM的潜力,解决各种实际问题,例如自然语言处理、机器翻译、文本生成等。
📄 摘要(原文)
Parameter-Efficient Fine-tuning (PEFT) facilitates the fine-tuning of Large Language Models (LLMs) under limited resources. However, the fine-tuning performance with PEFT on complex, knowledge-intensive tasks is limited due to the constrained model capacity, which originates from the limited number of additional trainable parameters. To overcome this limitation, we introduce a novel mechanism that fine-tunes LLMs with adapters of larger size yet memory-efficient. This is achieved by leveraging the inherent activation sparsity in the Feed-Forward Networks (FFNs) of LLMs and utilizing the larger capacity of Central Processing Unit (CPU) memory compared to Graphics Processing Unit (GPU). We store and update the parameters of larger adapters on the CPU. Moreover, we employ a Mixture of Experts (MoE)-like architecture to mitigate unnecessary CPU computations and reduce the communication volume between the GPU and CPU. This is particularly beneficial over the limited bandwidth of PCI Express (PCIe). Our method can achieve fine-tuning results comparable to those obtained with larger memory capacities, even when operating under more limited resources such as a 24GB memory single GPU setup, with acceptable loss in training efficiency. Our codes are available at https://github.com/CURRENTF/MEFT.