FedLLM-Bench: Realistic Benchmarks for Federated Learning of Large Language Models
作者: Rui Ye, Rui Ge, Xinyu Zhu, Jingyi Chai, Yaxin Du, Yang Liu, Yanfeng Wang, Siheng Chen
分类: cs.CL, cs.AI, cs.DC, cs.LG, cs.MA
发布日期: 2024-06-07
备注: 22 pages
🔗 代码/项目: GITHUB
💡 一句话要点
提出FedLLM-Bench,为联邦学习大语言模型提供真实基准测试平台
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 联邦学习 大语言模型 基准测试 多语言 指令调优
📋 核心要点
- 现有FedLLM研究缺乏真实数据集和基准,依赖人工构建数据集,无法反映真实场景。
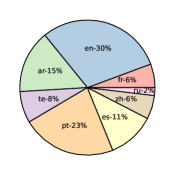
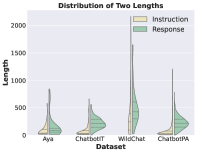
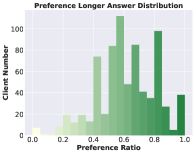
- FedLLM-Bench提供包含多样性特征的数据集,涵盖指令调优和偏好对齐任务,模拟真实联邦学习场景。
- 实验基于FedLLM-Bench评估现有联邦学习方法,为多语言协作等提供经验性指导。
📝 摘要(中文)
联邦学习使得多方能够在不直接共享数据的情况下协同训练大型语言模型(FedLLM)。围绕这种训练范式,社区在框架、性能和隐私等多个方面投入了大量精力。然而,目前缺乏用于FedLLM的真实数据集和基准,以往工作都依赖于人工构建的数据集,无法捕捉真实场景中的特性。为此,我们提出了FedLLM-Bench,它包含8种训练方法、4个训练数据集和6个评估指标,为FedLLM社区提供了一个全面的测试平台。FedLLM-Bench包含三个用于联邦指令调优的数据集(例如,用户标注的多语言数据集)和一个用于联邦偏好对齐的数据集(例如,用户标注的偏好数据集),其客户端数量范围从38到747。我们的数据集包含了多种代表性的多样性:语言、质量、数量、指令、长度、嵌入和偏好,捕捉了真实场景中的特性。基于FedLLM-Bench,我们对所有数据集进行了实验,以评估现有的FL方法,并提供经验性见解(例如,多语言协作)。我们相信FedLLM-Bench可以通过减少所需工作量、提供实用的测试平台和促进公平比较来使FedLLM社区受益。代码和数据集可在https://github.com/rui-ye/FedLLM-Bench获取。
🔬 方法详解
问题定义:现有联邦学习大语言模型(FedLLM)的研究缺乏真实可靠的基准测试数据集。以往的研究通常使用人工构建的数据集,这些数据集难以捕捉真实世界场景中数据的复杂性和多样性,例如不同客户端的数据质量、数量、语言以及用户偏好的差异。这导致在这些人工数据集上训练的模型在实际应用中可能表现不佳,并且难以公平地比较不同的FedLLM方法。
核心思路:FedLLM-Bench的核心思路是构建一个更贴近真实场景的FedLLM基准测试平台,通过收集和整理包含多样性特征的数据集,例如多语言、不同质量、不同数量、不同指令、不同长度、不同嵌入和不同偏好的数据,来模拟真实世界中联邦学习环境的复杂性。这样可以更准确地评估FedLLM方法的性能,并促进更公平的比较。
技术框架:FedLLM-Bench包含以下几个主要组成部分: 1. 数据集:提供四个数据集,包括三个用于联邦指令调优的数据集和一个用于联邦偏好对齐的数据集。这些数据集涵盖了多种语言和用户偏好。 2. 训练方法:提供八种不同的训练方法,包括不同的联邦学习算法和优化策略。 3. 评估指标:提供六种评估指标,用于评估模型在不同方面的性能,例如准确率、效率和隐私保护。 4. 基准测试:使用这些数据集、训练方法和评估指标,对现有的FedLLM方法进行基准测试,并提供实验结果和分析。
关键创新:FedLLM-Bench的关键创新在于其数据集的真实性和多样性。与以往的人工构建数据集不同,FedLLM-Bench的数据集来源于真实用户数据,并包含了多种代表性的多样性特征,例如语言、质量、数量、指令、长度、嵌入和偏好。这种真实性和多样性使得FedLLM-Bench能够更准确地评估FedLLM方法的性能,并促进更公平的比较。
关键设计:FedLLM-Bench的关键设计包括: 1. 数据集构建:精心挑选和处理真实用户数据,以确保数据集的多样性和代表性。 2. 客户端划分:根据用户属性或数据特征,将数据集划分到不同的客户端,以模拟真实世界中的联邦学习环境。 3. 评估指标选择:选择合适的评估指标,以全面评估模型在不同方面的性能,例如准确率、效率和隐私保护。
🖼️ 关键图片
📊 实验亮点
FedLLM-Bench通过实验验证了多语言协作在联邦学习中的有效性,并揭示了不同联邦学习方法在不同数据集上的性能差异。例如,实验结果表明,在某些数据集上,特定的联邦学习算法能够显著提高模型的准确率和效率,为实际应用中选择合适的联邦学习方法提供了有价值的参考。
🎯 应用场景
FedLLM-Bench可应用于评估和改进联邦学习大语言模型在各种实际场景中的性能,例如跨语言智能助手、个性化推荐系统和医疗健康领域。通过提供更真实的基准测试,该平台有助于推动联邦学习技术在保护用户隐私的同时,实现更高效和可靠的模型训练,最终促进人工智能在各个领域的广泛应用。
📄 摘要(原文)
Federated learning has enabled multiple parties to collaboratively train large language models without directly sharing their data (FedLLM). Following this training paradigm, the community has put massive efforts from diverse aspects including framework, performance, and privacy. However, an unpleasant fact is that there are currently no realistic datasets and benchmarks for FedLLM and previous works all rely on artificially constructed datasets, failing to capture properties in real-world scenarios. Addressing this, we propose FedLLM-Bench, which involves 8 training methods, 4 training datasets, and 6 evaluation metrics, to offer a comprehensive testbed for the FedLLM community. FedLLM-Bench encompasses three datasets (e.g., user-annotated multilingual dataset) for federated instruction tuning and one dataset (e.g., user-annotated preference dataset) for federated preference alignment, whose scale of client number ranges from 38 to 747. Our datasets incorporate several representative diversities: language, quality, quantity, instruction, length, embedding, and preference, capturing properties in real-world scenarios. Based on FedLLM-Bench, we conduct experiments on all datasets to benchmark existing FL methods and provide empirical insights (e.g., multilingual collaboration). We believe that our FedLLM-Bench can benefit the FedLLM community by reducing required efforts, providing a practical testbed, and promoting fair comparisons. Code and datasets are available at https://github.com/rui-ye/FedLLM-Bench.