AICoderEval: Improving AI Domain Code Generation of Large Language Models
作者: Yinghui Xia, Yuyan Chen, Tianyu Shi, Jun Wang, Jinsong Yang
分类: cs.CL
发布日期: 2024-06-07
🔗 代码/项目: HUGGINGFACE
💡 一句话要点
AICoderEval:提升大语言模型在AI领域代码生成能力的数据集与框架
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 代码生成 大语言模型 AI领域 数据集 Agent框架
📋 核心要点
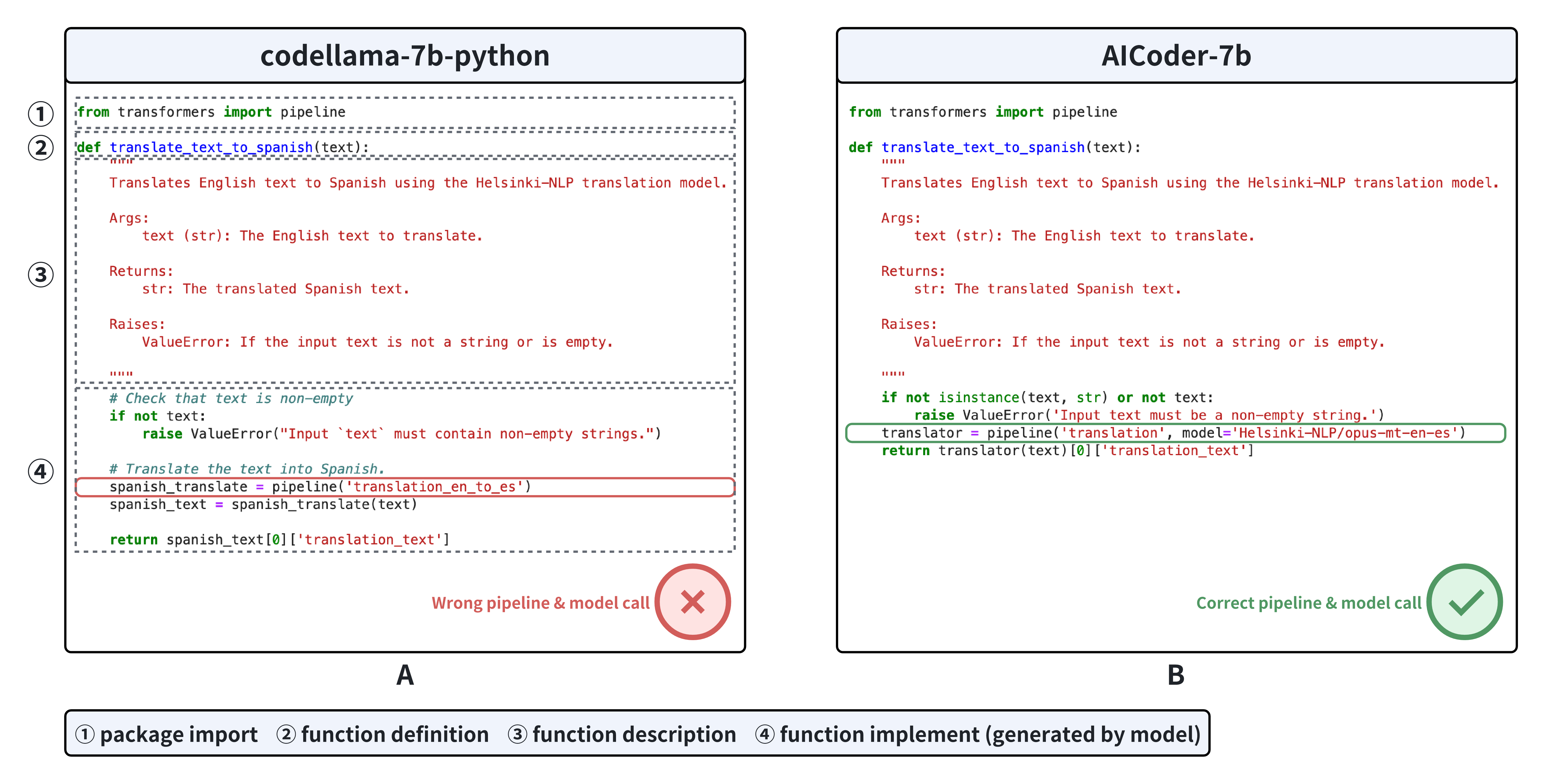
- 现有代码生成评估方法侧重底层代码,缺乏对真实场景下AI任务高级代码生成能力的有效评估。
- 提出AICoderEval数据集和CoderGen框架,并训练AICoder模型,提升LLMs在自然语言处理、计算机视觉和多模态学习等领域的代码生成能力。
- 实验表明CoderGen能显著提升LLMs的代码生成能力,AICoder模型性能优于现有模型,验证了AICoderEval基准的有效性。
📝 摘要(中文)
本文提出了一种名为AICoderEval的数据集,旨在评估和提升大语言模型(LLMs)在真实场景下的AI领域代码生成能力。与以往侧重于底层代码生成的方法不同,AICoderEval专注于生成面向实际任务的高级代码,涵盖图像到文本、文本分类等多种领域,并基于HuggingFace、PyTorch和TensorFlow构建。此外,论文还提出了一个基于Agent的框架CoderGen,以辅助LLMs在AICoderEval上生成代码。最后,通过在AICoderEval上微调Llama-3,训练了一个更强大的任务特定代码生成模型AICoder。实验结果表明,CoderGen能够有效提升LLMs的代码生成能力(原始模型pass@1提升12.00%,ReAct Agent提升9.50%),而AICoder的性能也优于现有的代码生成LLMs,验证了AICoderEval基准的质量。
🔬 方法详解
问题定义:现有的大语言模型在代码生成方面取得了显著进展,但评估其在真实AI任务中的代码生成能力仍然是一个挑战。以往的评估方法更多地关注模型加载等底层代码的生成,而忽略了图像到文本转换、文本分类等更高级、更贴近实际应用场景的代码生成能力。因此,需要一个更全面、更贴近实际的评估基准来衡量和提升LLMs在AI领域的代码生成能力。
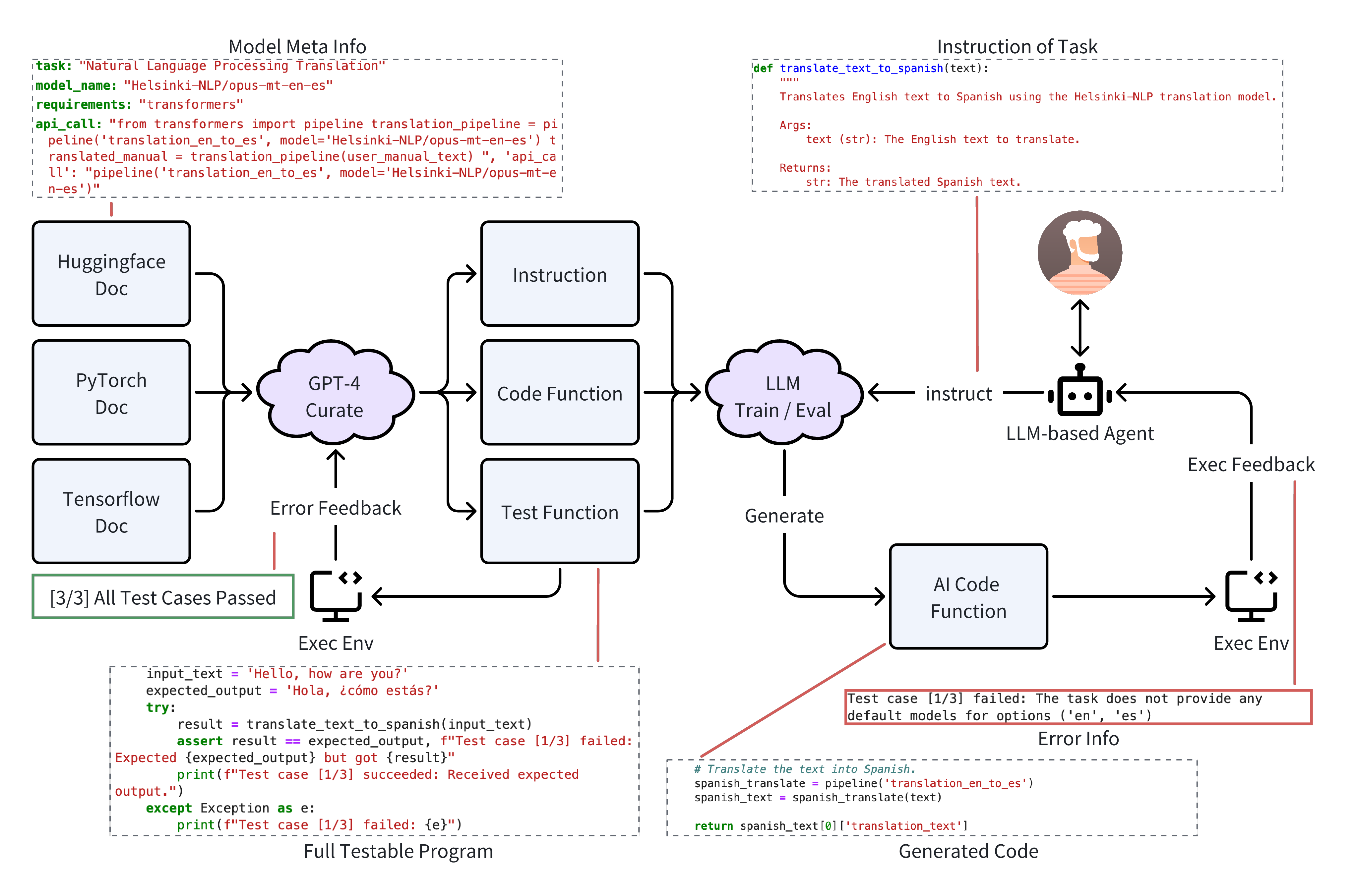
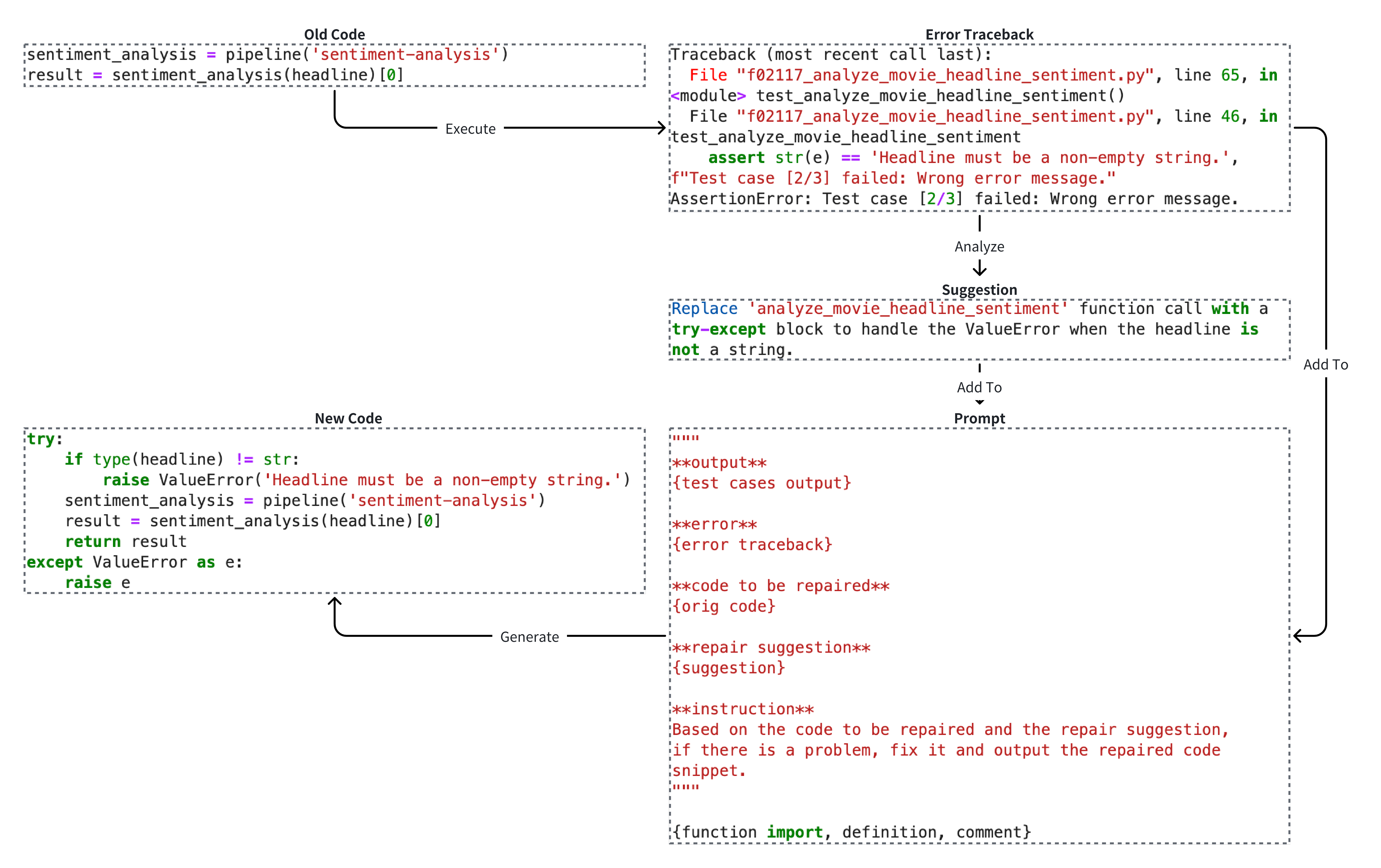
核心思路:本文的核心思路是构建一个高质量的、面向真实AI任务的代码生成数据集AICoderEval,并基于此数据集开发相应的评估指标和训练框架。通过这个数据集,可以更准确地评估LLMs在实际应用中的代码生成能力,并指导模型的训练和优化。同时,提出了一个基于Agent的框架CoderGen,辅助LLMs生成代码,提升代码生成的质量和效率。
技术框架:整体框架包含三个主要部分:1) AICoderEval数据集的构建,该数据集包含各种AI任务的测试用例和完整程序;2) CoderGen框架的设计,该框架利用Agent技术来指导LLMs生成代码;3) AICoder模型的训练,该模型基于Llama-3,并在AICoderEval数据集上进行微调。CoderGen框架的具体流程未知。
关键创新:主要的创新点在于:1) 构建了AICoderEval数据集,该数据集专注于真实AI任务的代码生成,弥补了现有评估基准的不足;2) 提出了CoderGen框架,利用Agent技术来提升LLMs的代码生成能力;3) 训练了AICoder模型,该模型在AICoderEval数据集上取得了优异的性能。
关键设计:关于AICoderEval数据集,其构建细节(例如,任务选择、数据收集、标注方法等)未知。CoderGen框架中Agent的具体设计(例如,Agent的类型、目标函数、训练方法等)未知。AICoder模型的训练细节(例如,学习率、优化器、损失函数等)未知。
🖼️ 关键图片
📊 实验亮点
实验结果表明,CoderGen框架能够显著提升LLMs的代码生成能力,原始模型在pass@1指标上提升了12.00%,ReAct Agent在pass@1指标上提升了9.50%。此外,通过在AICoderEval数据集上微调Llama-3,训练得到的AICoder模型也优于现有的代码生成LLMs,验证了AICoderEval基准的有效性。
🎯 应用场景
该研究成果可应用于自动化机器学习、AI辅助编程、智能教育等领域。通过AICoderEval数据集和CoderGen框架,可以更有效地评估和提升LLMs在AI领域的代码生成能力,从而降低AI开发的门槛,加速AI技术的普及和应用。未来,可以进一步扩展AICoderEval数据集的规模和覆盖范围,并探索更先进的代码生成技术。
📄 摘要(原文)
Automated code generation is a pivotal capability of large language models (LLMs). However, assessing this capability in real-world scenarios remains challenging. Previous methods focus more on low-level code generation, such as model loading, instead of generating high-level codes catering for real-world tasks, such as image-to-text, text classification, in various domains. Therefore, we construct AICoderEval, a dataset focused on real-world tasks in various domains based on HuggingFace, PyTorch, and TensorFlow, along with comprehensive metrics for evaluation and enhancing LLMs' task-specific code generation capability. AICoderEval contains test cases and complete programs for automated evaluation of these tasks, covering domains such as natural language processing, computer vision, and multimodal learning. To facilitate research in this area, we open-source the AICoderEval dataset at \url{https://huggingface.co/datasets/vixuowis/AICoderEval}. After that, we propose CoderGen, an agent-based framework, to help LLMs generate codes related to real-world tasks on the constructed AICoderEval. Moreover, we train a more powerful task-specific code generation model, named AICoder, which is refined on llama-3 based on AICoderEval. Our experiments demonstrate the effectiveness of CoderGen in improving LLMs' task-specific code generation capability (by 12.00\% on pass@1 for original model and 9.50\% on pass@1 for ReAct Agent). AICoder also outperforms current code generation LLMs, indicating the great quality of the AICoderEval benchmark.