Large Language Model-guided Document Selection
作者: Xiang Kong, Tom Gunter, Ruoming Pang
分类: cs.CL
发布日期: 2024-06-07
备注: 9 pages
💡 一句话要点
提出基于大语言模型指导的文档选择方法,提升预训练效率。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 文档选择 预训练 零样本学习 数据过滤
📋 核心要点
- 大规模语言模型预训练需要巨大的计算资源,而有效的文档选择能够以更少的计算量达到相当的模型质量。
- 该论文利用指令微调的LLM作为零样本数据标注器,指导文档选择,从而提升预训练效率。
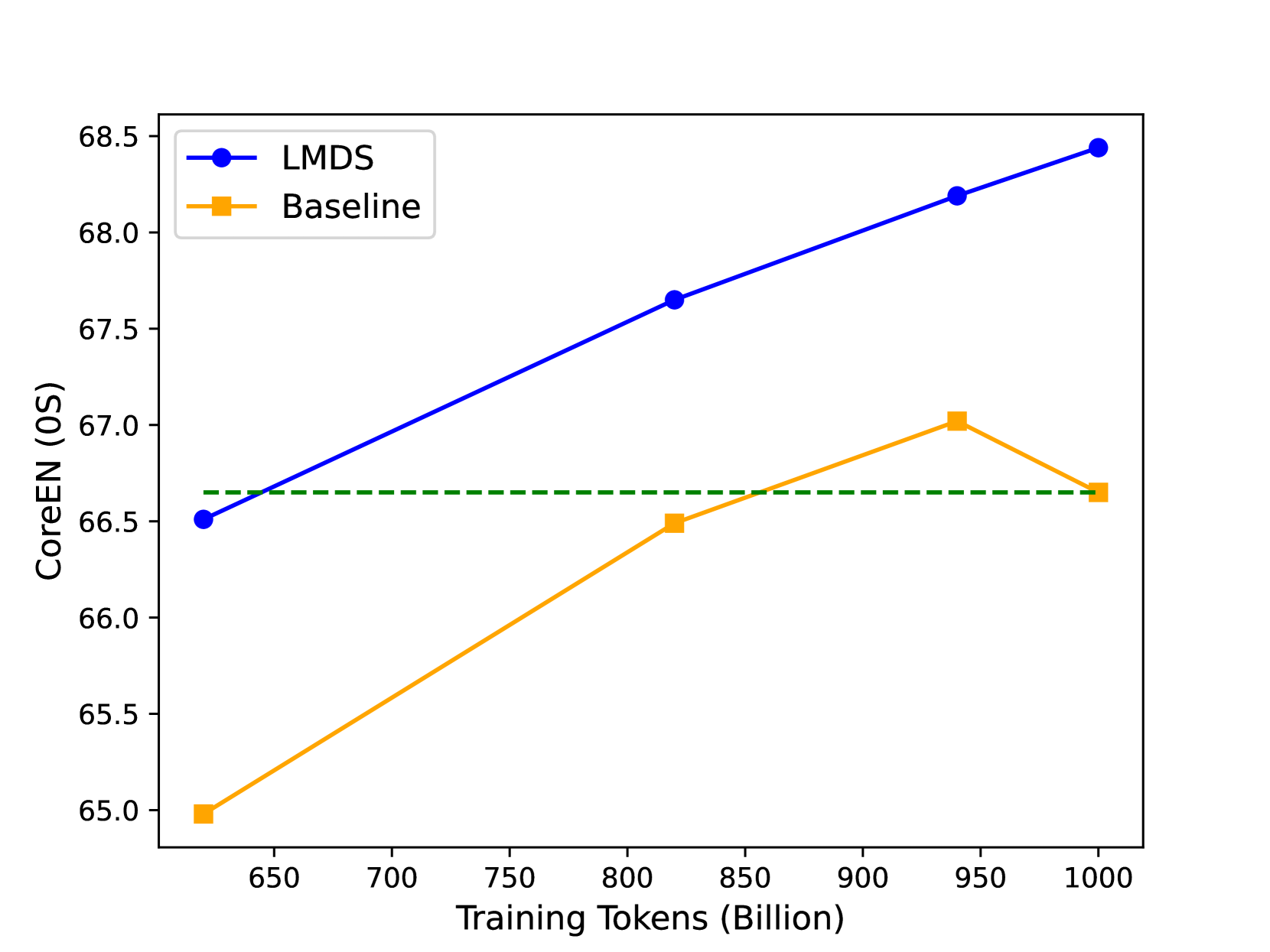
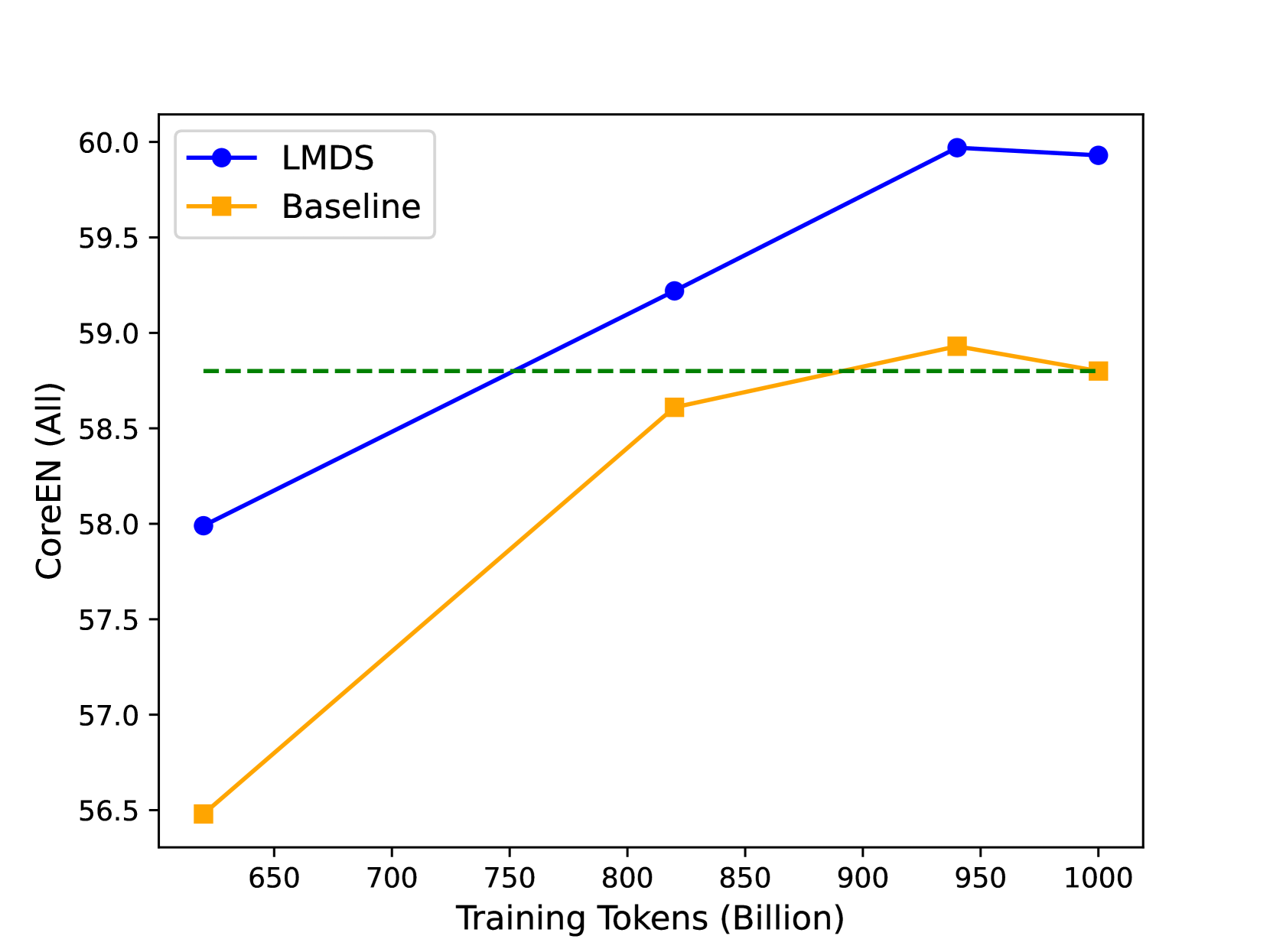
- 实验表明,使用该方法过滤后的数据集训练的模型,在多个基准测试中,能以更少的计算量匹配甚至超过在完整数据集上训练的模型。
📝 摘要(中文)
本文提出了一种可扩展的通用领域文档选择方法,该方法利用提示的大语言模型(LLM)作为文档评分器,将质量标签提炼到分类器模型中,并大规模应用于大型网络爬取语料库。通过该分类器的指导,丢弃75%的语料库,并在剩余数据上训练LLM。实验结果表明:1. 在多个基准测试中,通过过滤,模型在最多70%的FLOPs下可以达到在完整语料库上训练的模型的质量;2. 更强大的LLM标注器和分类器模型可以带来更好的结果,并且对标注器的提示不敏感;3. 上下文学习有助于提高能力较弱的标注模型的性能。所有实验均使用开源数据集、模型、配方和评估框架,以便社区可以复现结果。
🔬 方法详解
问题定义:大规模语言模型(LLM)的预训练需要消耗大量的计算资源。尽管可以通过文档过滤来减少计算量,但如何有效地选择高质量的训练文档仍然是一个挑战。现有的文档选择方法可能不够高效或无法很好地泛化到不同的领域。
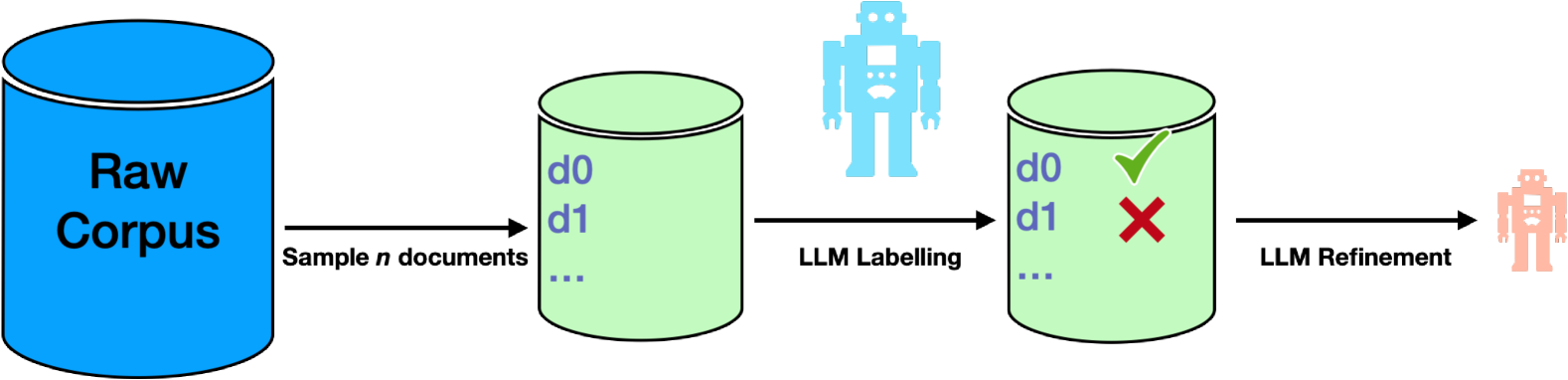
核心思路:利用大型语言模型(LLM)强大的零样本标注能力,将LLM作为一个文档质量的评分器,对大规模语料库中的文档进行质量评估。然后,将这些质量标签提炼到一个更小的分类器模型中,以便能够高效地对整个语料库进行筛选。通过这种方式,可以保留高质量的文档,并丢弃低质量的文档,从而减少预训练所需的计算资源。
技术框架:该方法主要包含以下几个阶段: 1. LLM标注阶段:使用prompt工程,将LLM作为文档质量评分器,对部分文档进行标注,生成质量标签。 2. 分类器训练阶段:使用LLM生成的质量标签训练一个分类器模型,该模型用于预测大规模语料库中每个文档的质量。 3. 文档过滤阶段:使用训练好的分类器模型对整个语料库进行评分,并根据设定的阈值过滤掉低质量的文档。 4. LLM预训练阶段:在过滤后的高质量文档上进行LLM的预训练。
关键创新:该方法的核心创新在于利用LLM的零样本标注能力来指导文档选择。与传统的基于规则或统计的文档选择方法相比,该方法能够更好地捕捉文档的语义信息和质量,从而选择出更适合LLM预训练的文档。此外,通过将LLM的知识提炼到分类器模型中,可以实现高效的文档过滤。
关键设计: * Prompt设计:设计合适的prompt,引导LLM对文档进行准确的质量评估。 * 分类器选择:选择合适的分类器模型,例如基于Transformer的模型,以便能够有效地学习LLM生成的质量标签。 * 过滤阈值:设置合适的过滤阈值,以平衡数据集的大小和质量。
🖼️ 关键图片
📊 实验亮点
实验结果表明,使用该方法过滤后的数据集训练的模型,在多个基准测试中,能以最多70%的FLOPs达到在完整数据集上训练的模型的质量。更强大的LLM标注器和分类器模型可以带来更好的结果,并且对标注器的提示不敏感。上下文学习有助于提高能力较弱的标注模型的性能。
🎯 应用场景
该研究成果可应用于大规模语言模型的预训练,降低训练成本,提高训练效率。同时,该方法也可推广到其他机器学习任务中,用于数据清洗和数据选择,提升模型性能。该方法具有广泛的应用前景,能够促进人工智能技术的发展。
📄 摘要(原文)
Large Language Model (LLM) pre-training exhausts an ever growing compute budget, yet recent research has demonstrated that careful document selection enables comparable model quality with only a fraction of the FLOPs. Inspired by efforts suggesting that domain-specific training document selection is in fact an interpretable process [Gunasekar et al., 2023], as well as research showing that instruction-finetuned LLMs are adept zero-shot data labelers [Gilardi et al.,2023], we explore a promising direction for scalable general-domain document selection; employing a prompted LLM as a document grader, we distill quality labels into a classifier model, which is applied at scale to a large, and already heavily-filtered, web-crawl-derived corpus autonomously. Following the guidance of this classifier, we drop 75% of the corpus and train LLMs on the remaining data. Results across multiple benchmarks show that: 1. Filtering allows us to quality-match a model trained on the full corpus across diverse benchmarks with at most 70% of the FLOPs, 2. More capable LLM labelers and classifier models lead to better results that are less sensitive to the labeler's prompt, 3. In-context learning helps to boost the performance of less-capable labeling models. In all cases we use open-source datasets, models, recipes, and evaluation frameworks, so that results can be reproduced by the community.