What do MLLMs hear? Examining reasoning with text and sound components in Multimodal Large Language Models
作者: Enis Berk Çoban, Michael I. Mandel, Johanna Devaney
分类: eess.AS, cs.CL, cs.SD
发布日期: 2024-06-07
备注: 9 pages
💡 一句话要点
研究音频多模态大语言模型推理能力,揭示其文本推理在音频分类中的局限性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大语言模型 音频理解 文本推理 音频分类 音频标注
📋 核心要点
- 现有音频多模态大语言模型在音频分类任务中,无法有效利用其内置LLM的文本推理能力。
- 该论文通过实验分析,揭示了音频MLLM在生成音频标注时,文本推理能力受限的问题。
- 研究表明,MLLM可能对听觉和文本信息进行独立表示,阻碍了LLM到音频编码器的推理路径。
📝 摘要(中文)
大型语言模型(LLMs)在推理能力方面表现出色,尤其是在连接概念和遵循逻辑规则解决问题方面。这些模型已经发展到可以处理包括声音和图像在内的各种数据模态,被称为多模态LLMs(MLLMs),它们能够描述图像或录音。先前的工作表明,当MLLMs中的LLM组件被冻结时,音频或视觉编码器用于标注声音或图像输入,从而促进LLM组件进行基于文本的推理。本文旨在利用LLM的推理能力来促进分类。通过一个标注/分类实验,我们证明了音频MLLM在生成音频标注时无法充分利用其LLM的基于文本的推理能力。我们还考虑了这可能是由于MLLM分别表示听觉和文本信息,从而切断了从LLM到音频编码器的推理路径。
🔬 方法详解
问题定义:论文旨在研究音频多模态大语言模型(MLLM)在处理音频分类任务时,其内部LLM的文本推理能力是否能被有效利用。现有方法中,音频编码器生成的音频描述可能不足以充分激活LLM的推理能力,导致分类性能受限。因此,如何让LLM更好地理解音频内容并进行推理是关键问题。
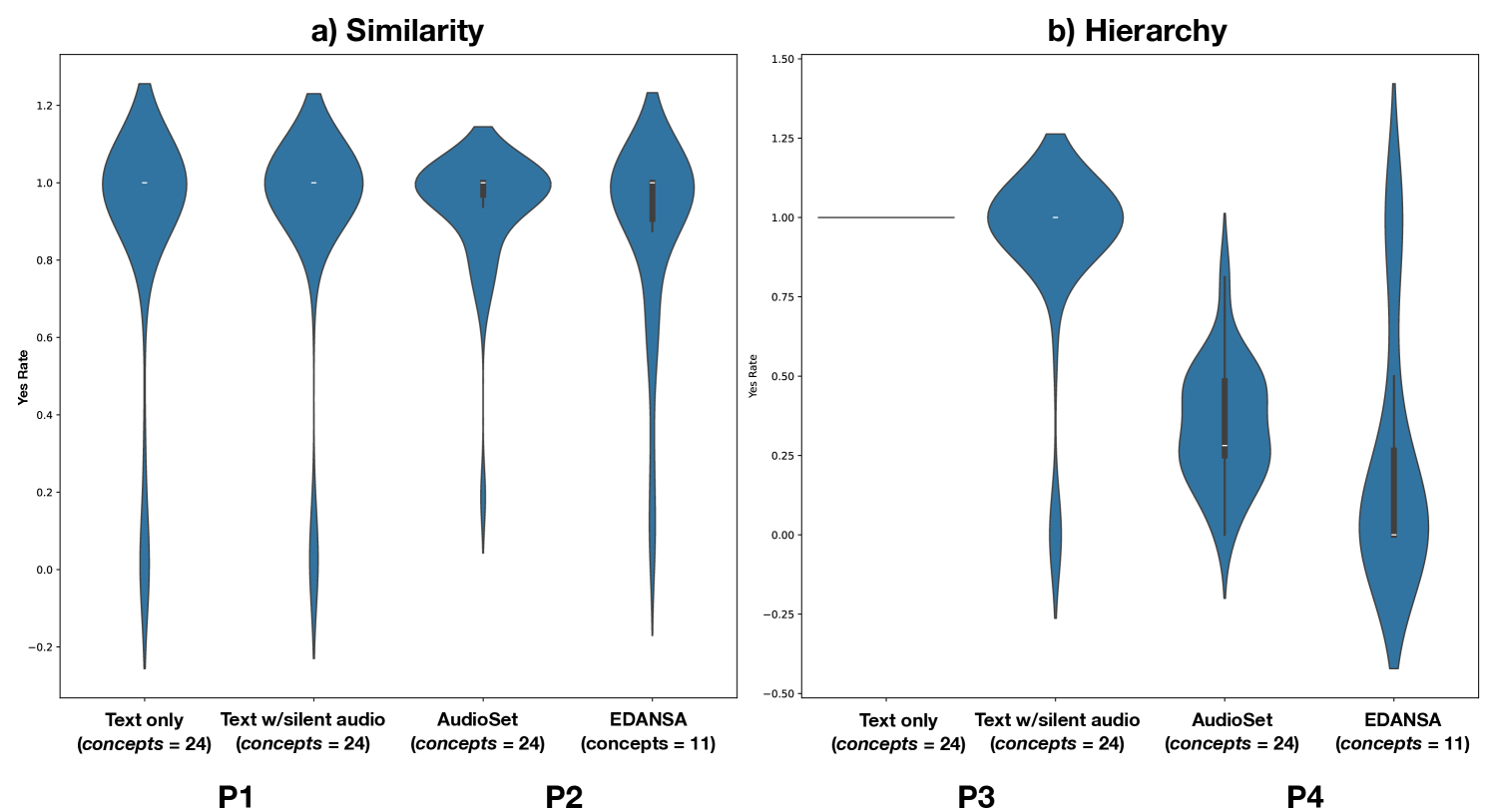
核心思路:论文的核心思路是通过一个标注/分类实验,分析音频MLLM在生成音频标注时,其LLM的文本推理能力的使用情况。通过对比不同标注质量下的分类结果,来判断LLM是否充分利用了其文本推理能力。如果标注质量提升未能显著提升分类性能,则表明LLM的文本推理能力未被有效利用。
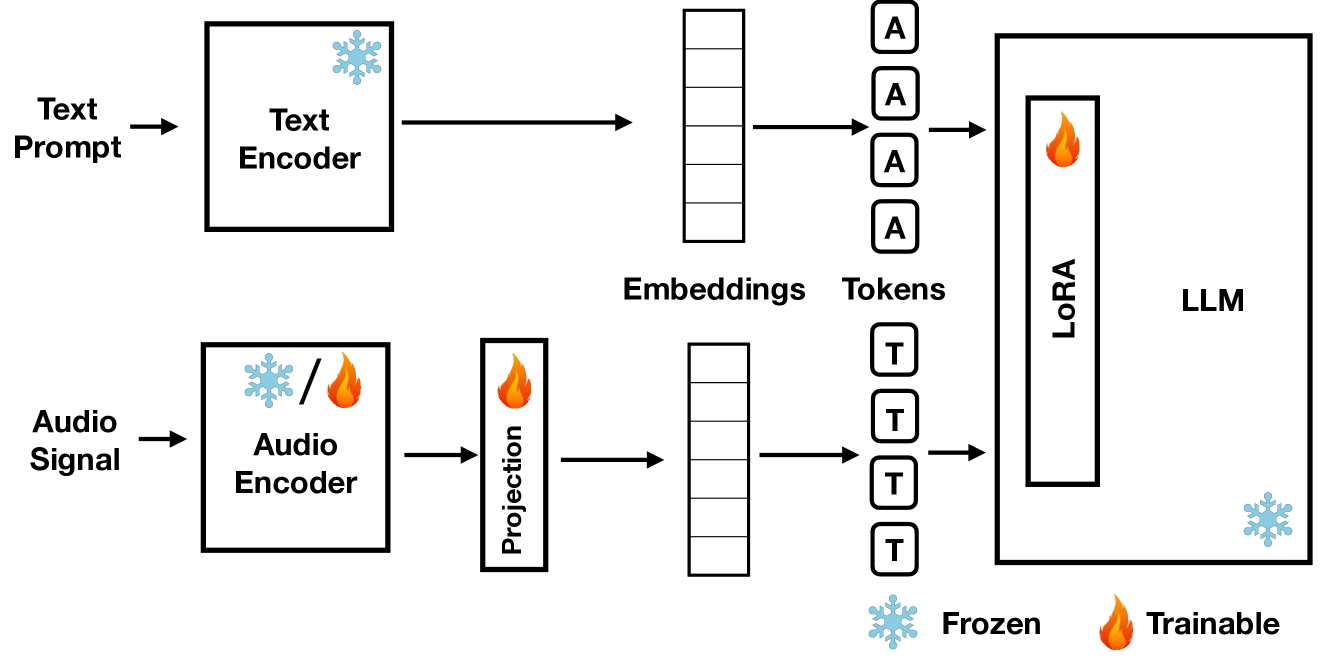
技术框架:该研究采用了一个包含音频编码器和LLM的MLLM框架。音频编码器负责将音频信号转换为文本描述(caption),然后将该描述输入到LLM中进行分类。实验流程包括:1) 使用音频编码器生成音频标注;2) 将音频标注输入到LLM中进行分类;3) 分析标注质量与分类性能之间的关系。
关键创新:该研究的创新点在于,它不是直接评估MLLM的分类性能,而是关注MLLM内部LLM的文本推理能力是否被有效利用。通过分析标注质量与分类性能之间的关系,揭示了音频MLLM在处理音频分类任务时,可能存在的推理瓶颈。
关键设计:实验的关键设计在于标注/分类实验。通过控制标注的质量(例如,使用人工标注或机器标注),并观察分类性能的变化,来推断LLM的文本推理能力是否被有效利用。具体的参数设置和网络结构信息在摘要中未提及,属于未知信息。
🖼️ 关键图片
📊 实验亮点
该研究通过实验证明,音频MLLM在生成音频标注时,无法充分利用其LLM的基于文本的推理能力。这表明,简单地将音频编码器和LLM拼接起来,并不能充分发挥MLLM的潜力。需要更深入地研究如何将音频信息有效地融入到LLM的推理过程中,以提升MLLM的性能。
🎯 应用场景
该研究成果有助于改进音频多模态大语言模型的设计,使其更好地理解音频内容并进行推理。潜在应用包括:更智能的语音助手、更精确的音频事件检测、以及更自然的音频内容生成。通过提升MLLM的音频理解能力,可以拓展其在智能家居、自动驾驶、医疗健康等领域的应用。
📄 摘要(原文)
Large Language Models (LLMs) have demonstrated remarkable reasoning capabilities, notably in connecting ideas and adhering to logical rules to solve problems. These models have evolved to accommodate various data modalities, including sound and images, known as multimodal LLMs (MLLMs), which are capable of describing images or sound recordings. Previous work has demonstrated that when the LLM component in MLLMs is frozen, the audio or visual encoder serves to caption the sound or image input facilitating text-based reasoning with the LLM component. We are interested in using the LLM's reasoning capabilities in order to facilitate classification. In this paper, we demonstrate through a captioning/classification experiment that an audio MLLM cannot fully leverage its LLM's text-based reasoning when generating audio captions. We also consider how this may be due to MLLMs separately representing auditory and textual information such that it severs the reasoning pathway from the LLM to the audio encoder.