Extroversion or Introversion? Controlling The Personality of Your Large Language Models
作者: Yanquan Chen, Zhen Wu, Junjie Guo, Shujian Huang, Xinyu Dai
分类: cs.CL
发布日期: 2024-06-07
💡 一句话要点
提出PISF方法,实现对大型语言模型人格更有效和鲁棒的控制。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 人格控制 监督微调 提示工程 PISF 鲁棒性 人工智能
📋 核心要点
- 现有大型语言模型人格控制研究不足,缺乏对人格起源和演变的理解,以及有效控制方法的探索。
- 论文提出Prompt Induction post Supervised Fine-tuning (PISF)方法,结合SFT和Prompt的优势,实现更有效和鲁棒的人格控制。
- 实验结果表明,PISF方法在控制LLM人格方面表现出高效率、高成功率和高鲁棒性,即使在反向提示下也能保持稳定。
📝 摘要(中文)
大型语言模型(LLMs)在文本生成和理解方面表现出强大的能力,能够模仿人类行为并呈现出合成的人格。然而,一些LLMs表现出令人反感的性格,传播有害言论。现有文献忽略了LLM人格的起源和演变,以及有效的人格控制。为了填补这些空白,本研究对LLM人格控制进行了全面调查。我们研究了几种影响LLM的典型方法,包括三种训练方法:持续预训练、监督微调(SFT)和基于人类反馈的强化学习(RLHF),以及推理阶段的提示。我们的研究揭示了控制效果的层次结构:Prompt > SFT > RLHF > 持续预训练。值得注意的是,与提示诱导相比,SFT表现出更高的控制成功率。虽然提示被证明非常有效,但我们发现提示诱导的人格不如训练的人格稳健,这使得它们更容易在反向人格提示诱导下表现出冲突的人格。此外,利用SFT和提示的优势,我们提出了提示诱导后监督微调(PISF),它成为控制LLM人格的最有效和最稳健的策略,表现出高效率、高成功率和高鲁棒性。即使在反向人格提示诱导下,由PISF控制的LLM仍然表现出稳定和鲁棒的人格。
🔬 方法详解
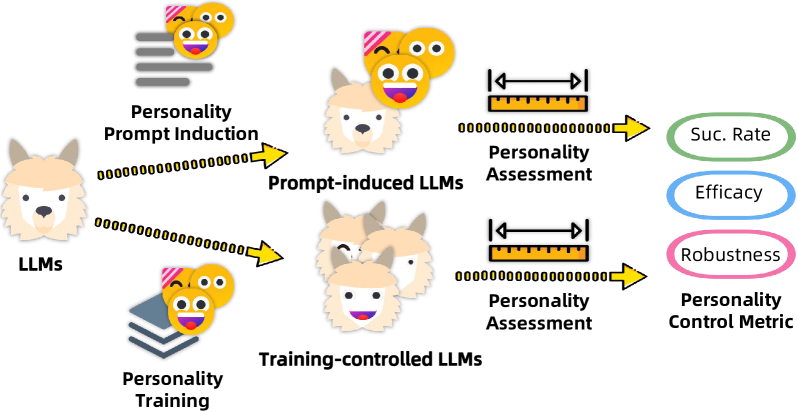
问题定义:论文旨在解决大型语言模型(LLMs)人格控制的问题。现有方法,如持续预训练、监督微调(SFT)、基于人类反馈的强化学习(RLHF)以及提示工程,在控制LLM人格方面存在局限性。例如,持续预训练和RLHF的控制效果较弱,而单纯的Prompt诱导虽然有效,但鲁棒性不足,容易受到反向提示的影响,导致人格不稳定。因此,需要一种更有效且鲁棒的方法来控制LLM的人格。
核心思路:论文的核心思路是结合监督微调(SFT)和提示工程(Prompt Induction)的优势,提出Prompt Induction post Supervised Fine-tuning (PISF)方法。SFT能够有效地塑造LLM的人格,而Prompt Induction则可以在SFT的基础上进一步微调和强化人格特征。通过先进行SFT,再进行Prompt Induction,可以获得更稳定和鲁棒的人格控制效果。
技术框架:PISF方法的技术框架主要包括两个阶段:首先,使用SFT对LLM进行微调,使其具备目标人格特征。具体来说,可以使用包含目标人格特征的文本数据对LLM进行训练,使其学习到与该人格相关的语言模式和行为方式。然后,在SFT的基础上,使用Prompt Induction进一步微调LLM的人格。Prompt Induction通过设计特定的提示语,引导LLM生成符合目标人格特征的文本。通过这两个阶段的结合,可以实现对LLM人格的有效控制。
关键创新:PISF方法的关键创新在于将SFT和Prompt Induction相结合,充分利用了两种方法的优势。与单独使用SFT或Prompt Induction相比,PISF方法能够获得更稳定和鲁棒的人格控制效果。此外,PISF方法还提出了一种新的训练范式,即先进行SFT,再进行Prompt Induction,这种范式可以为LLM的人格控制提供新的思路。
关键设计:在SFT阶段,需要选择合适的训练数据,以确保LLM能够学习到目标人格特征。可以使用包含目标人格特征的文本数据,例如,如果想要训练一个外向型LLM,可以使用包含外向型人格特征的对话数据。在Prompt Induction阶段,需要设计有效的提示语,以引导LLM生成符合目标人格特征的文本。提示语的设计需要考虑到目标人格的特点,例如,如果想要训练一个外向型LLM,可以使用鼓励性的提示语,例如“请你热情地介绍一下自己”。此外,还可以使用一些技术手段来提高Prompt Induction的效果,例如,可以使用强化学习来优化提示语的设计。
🖼️ 关键图片


📊 实验亮点
实验结果表明,PISF方法在控制LLM人格方面表现出显著的优势。与单独使用SFT或Prompt Induction相比,PISF方法能够获得更高的控制成功率和鲁棒性。即使在反向人格提示诱导下,由PISF控制的LLM仍然能够保持稳定的人格特征。具体而言,PISF方法在人格控制的成功率方面比SFT提高了约10%,在鲁棒性方面也表现出明显的优势。
🎯 应用场景
该研究成果可应用于各种需要控制LLM人格的场景,例如,可以用于开发具有特定人格特征的聊天机器人、虚拟助手等。此外,该研究还可以用于防止LLM产生有害言论,提高LLM的安全性。未来,该研究可以进一步扩展到多模态LLM的人格控制,例如,可以控制LLM在生成图像或视频时所表现出的人格特征。
📄 摘要(原文)
Large language models (LLMs) exhibit robust capabilities in text generation and comprehension, mimicking human behavior and exhibiting synthetic personalities. However, some LLMs have displayed offensive personality, propagating toxic discourse. Existing literature neglects the origin and evolution of LLM personalities, as well as the effective personality control. To fill these gaps, our study embarked on a comprehensive investigation into LLM personality control. We investigated several typical methods to influence LLMs, including three training methods: Continual Pre-training, Supervised Fine-Tuning (SFT), and Reinforcement Learning from Human Feedback (RLHF), along with inference phase considerations (prompts). Our investigation revealed a hierarchy of effectiveness in control: Prompt > SFT > RLHF > Continual Pre-train. Notably, SFT exhibits a higher control success rate compared to prompt induction. While prompts prove highly effective, we found that prompt-induced personalities are less robust than those trained, making them more prone to showing conflicting personalities under reverse personality prompt induction. Besides, harnessing the strengths of both SFT and prompt, we proposed $\underline{\text{P}}$rompt $\underline{\text{I}}$nduction post $\underline{\text{S}}$upervised $\underline{\text{F}}$ine-tuning (PISF), which emerges as the most effective and robust strategy for controlling LLMs' personality, displaying high efficacy, high success rates, and high robustness. Even under reverse personality prompt induction, LLMs controlled by PISF still exhibit stable and robust personalities.