Effective Context Selection in LLM-based Leaderboard Generation: An Empirical Study
作者: Salomon Kabongo, Jennifer D'Souza, Sören Auer
分类: cs.CL
发布日期: 2024-06-06
备注: arXiv admin note: substantial text overlap with arXiv:2406.04383
💡 一句话要点
提出基于LLM的上下文选择方法,高效生成AI研究排行榜,提升准确率并减少幻觉。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 信息提取 排行榜生成 上下文选择 指令微调
📋 核心要点
- 现有AI研究排行榜生成方法依赖预定义分类,难以适应快速发展的新研究和数据集。
- 论文提出基于LLM的文本生成方法,通过指令微调FLAN-T5模型,直接从学术论文中提取排行榜信息。
- 实验表明,有效的上下文选择能显著提高LLM生成排行榜的准确率,并减少模型产生幻觉。
📝 摘要(中文)
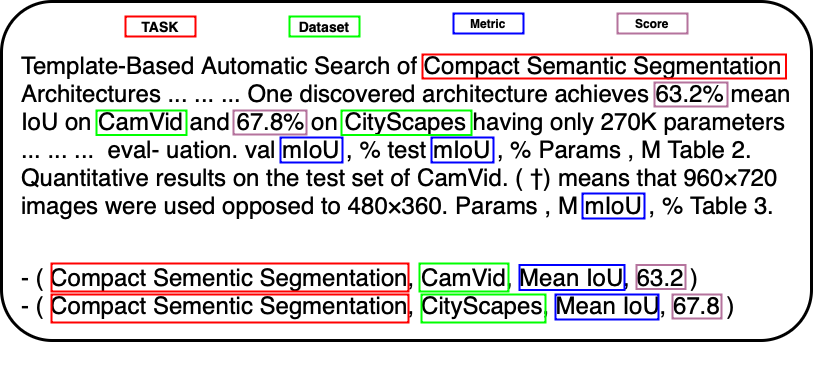
本文探讨了上下文选择对大型语言模型(LLM)在生成人工智能(AI)研究排行榜效率的影响。该任务定义为从学术文章中提取(任务、数据集、指标、分数)四元组。通过将此挑战构建为文本生成目标,并采用FLAN-T5集合进行指令微调,我们引入了一种新方法,该方法在适应新发展方面超越了传统的自然语言推理(NLI)方法,且无需预定义的分类。通过对三种不同选择性和长度的上下文类型进行实验,我们的研究证明了有效的上下文选择在提高LLM准确性和减少幻觉方面的重要性,为可靠高效地生成AI排行榜提供了一条新途径。这项贡献不仅提升了排行榜生成的最新水平,而且阐明了减轻基于LLM的信息提取中常见挑战的策略。
🔬 方法详解
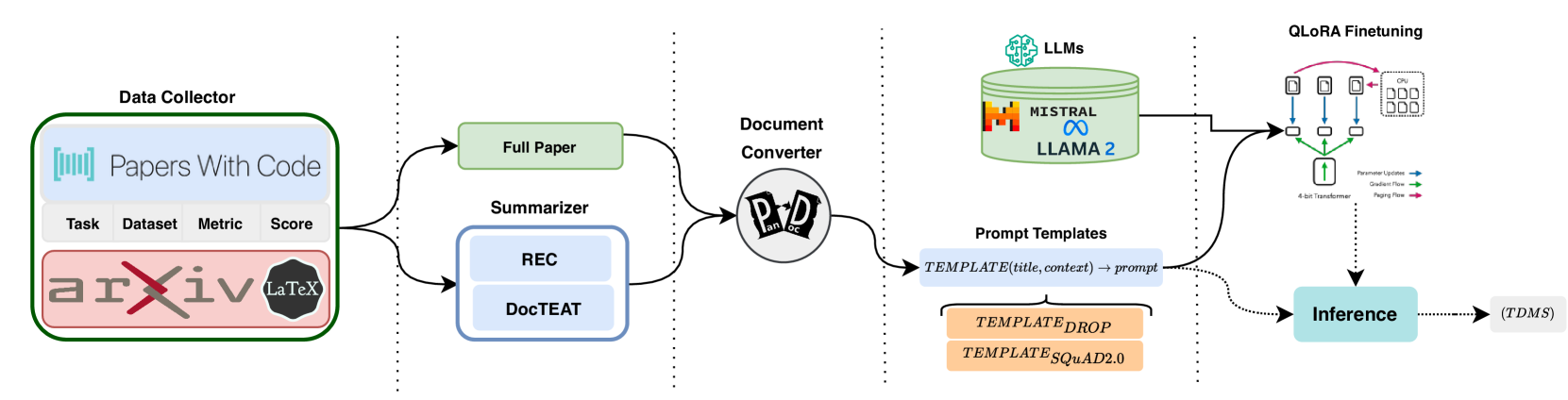
问题定义:现有AI研究排行榜的构建通常依赖于预定义的分类体系,这使得它们难以快速适应AI领域的最新进展和新兴数据集。此外,传统方法可能需要大量的人工干预,成本较高。因此,如何高效、准确地从海量学术文献中提取关键信息,自动生成并维护AI研究排行榜,是一个亟待解决的问题。
核心思路:论文的核心思路是将AI研究排行榜的生成任务转化为一个文本生成问题。通过利用大型语言模型(LLM)强大的文本理解和生成能力,直接从学术论文中提取(任务、数据集、指标、分数)四元组,从而自动构建排行榜。这种方法避免了对预定义分类体系的依赖,能够更好地适应AI领域的快速发展。
技术框架:该方法主要包含以下几个阶段:1) 数据准备:收集包含AI研究成果的学术论文;2) 上下文选择:根据不同的策略选择与排行榜生成相关的上下文信息;3) 模型微调:使用FLAN-T5模型,并采用指令微调的方式,使其能够根据给定的上下文生成(任务、数据集、指标、分数)四元组;4) 排行榜生成:利用微调后的LLM,从新的学术论文中提取信息,并生成AI研究排行榜。
关键创新:该方法最重要的技术创新点在于将排行榜生成任务转化为文本生成问题,并利用LLM的强大能力直接从学术论文中提取信息。与传统的基于自然语言推理(NLI)的方法相比,该方法无需预定义的分类体系,能够更好地适应AI领域的快速发展,并且能够减少人工干预。
关键设计:论文中关键的设计包括:1) 上下文选择策略:实验中使用了三种不同的上下文类型,以研究上下文选择对LLM性能的影响;2) 指令微调:使用FLAN-T5模型,并采用指令微调的方式,使其能够更好地理解和执行排行榜生成任务;3) 评估指标:使用准确率等指标来评估LLM生成排行榜的性能。
🖼️ 关键图片
📊 实验亮点
实验结果表明,该方法在AI研究排行榜生成任务上取得了显著的性能提升。通过有效的上下文选择,LLM能够更准确地提取关键信息,并减少产生幻觉。与传统的NLI方法相比,该方法在适应新发展方面表现更出色,无需预定义的分类体系。具体的性能数据和提升幅度在论文中有详细描述。
🎯 应用场景
该研究成果可应用于自动构建和维护AI研究排行榜,帮助研究人员快速了解领域最新进展,发现潜在的研究方向。此外,该方法也可推广到其他信息提取任务,例如自动生成技术报告、专利分析等,具有广泛的应用前景和实际价值。未来,可以进一步探索如何利用LLM生成更全面、更深入的AI研究分析报告。
📄 摘要(原文)
This paper explores the impact of context selection on the efficiency of Large Language Models (LLMs) in generating Artificial Intelligence (AI) research leaderboards, a task defined as the extraction of (Task, Dataset, Metric, Score) quadruples from scholarly articles. By framing this challenge as a text generation objective and employing instruction finetuning with the FLAN-T5 collection, we introduce a novel method that surpasses traditional Natural Language Inference (NLI) approaches in adapting to new developments without a predefined taxonomy. Through experimentation with three distinct context types of varying selectivity and length, our study demonstrates the importance of effective context selection in enhancing LLM accuracy and reducing hallucinations, providing a new pathway for the reliable and efficient generation of AI leaderboards. This contribution not only advances the state of the art in leaderboard generation but also sheds light on strategies to mitigate common challenges in LLM-based information extraction.