Prototypical Reward Network for Data-Efficient RLHF
作者: Jinghan Zhang, Xiting Wang, Yiqiao Jin, Changyu Chen, Xinhao Zhang, Kunpeng Liu
分类: cs.CL, cs.AI
发布日期: 2024-06-06 (更新: 2024-07-07)
备注: Accepted by ACL 2024
💡 一句话要点
提出原型奖励网络以解决数据效率低下的问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 人类反馈 强化学习 奖励模型 原型网络 数据效率 语言模型 微调
📋 核心要点
- 现有的RLHF方法在收集人类反馈时资源消耗大,且在复杂任务中面临可扩展性挑战。
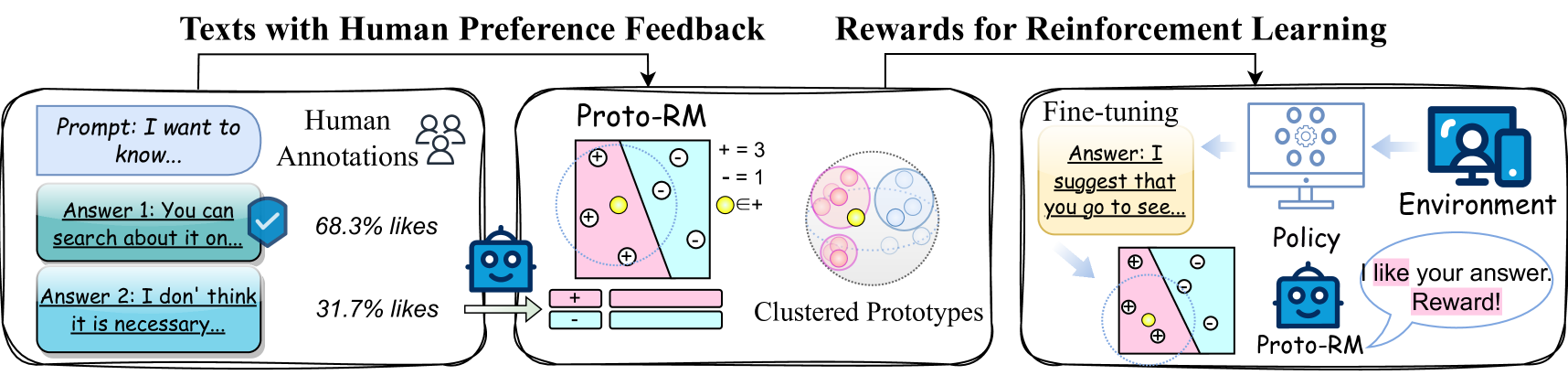
- 本文提出的Proto-RM框架通过原型网络增强奖励模型,能够在有限人类反馈下实现稳定的结构学习。
- 实验结果显示,Proto-RM在多种数据集上显著提升了奖励模型和LLMs的性能,通常优于传统方法,且数据需求显著降低。
📝 摘要(中文)
人类反馈强化学习(RLHF)的奖励模型在微调大型语言模型(LLMs)方面已被证明有效。然而,收集人类反馈的过程资源密集,且在复杂任务中存在可扩展性问题。本文提出的Proto-RM框架利用原型网络在有限的人类反馈下增强奖励模型。通过从较少样本中实现稳定可靠的结构学习,Proto-RM显著提高了LLMs在理解人类偏好方面的适应性和准确性。大量实验表明,Proto-RM在数据有限的场景中显著提升了奖励模型和LLMs在任务中的表现,通常优于传统方法,同时所需数据量显著减少。这项研究为在受限反馈条件下提升奖励模型的效率和优化语言模型的微调提供了有前景的方向。
🔬 方法详解
问题定义:本文旨在解决人类反馈强化学习(RLHF)中奖励模型的效率低下问题。现有方法在收集人类反馈时需要大量资源,且在复杂任务中难以扩展。
核心思路:论文提出的Proto-RM框架利用原型网络的优势,通过少量样本实现稳定的结构学习,从而提高奖励模型的适应性和准确性。
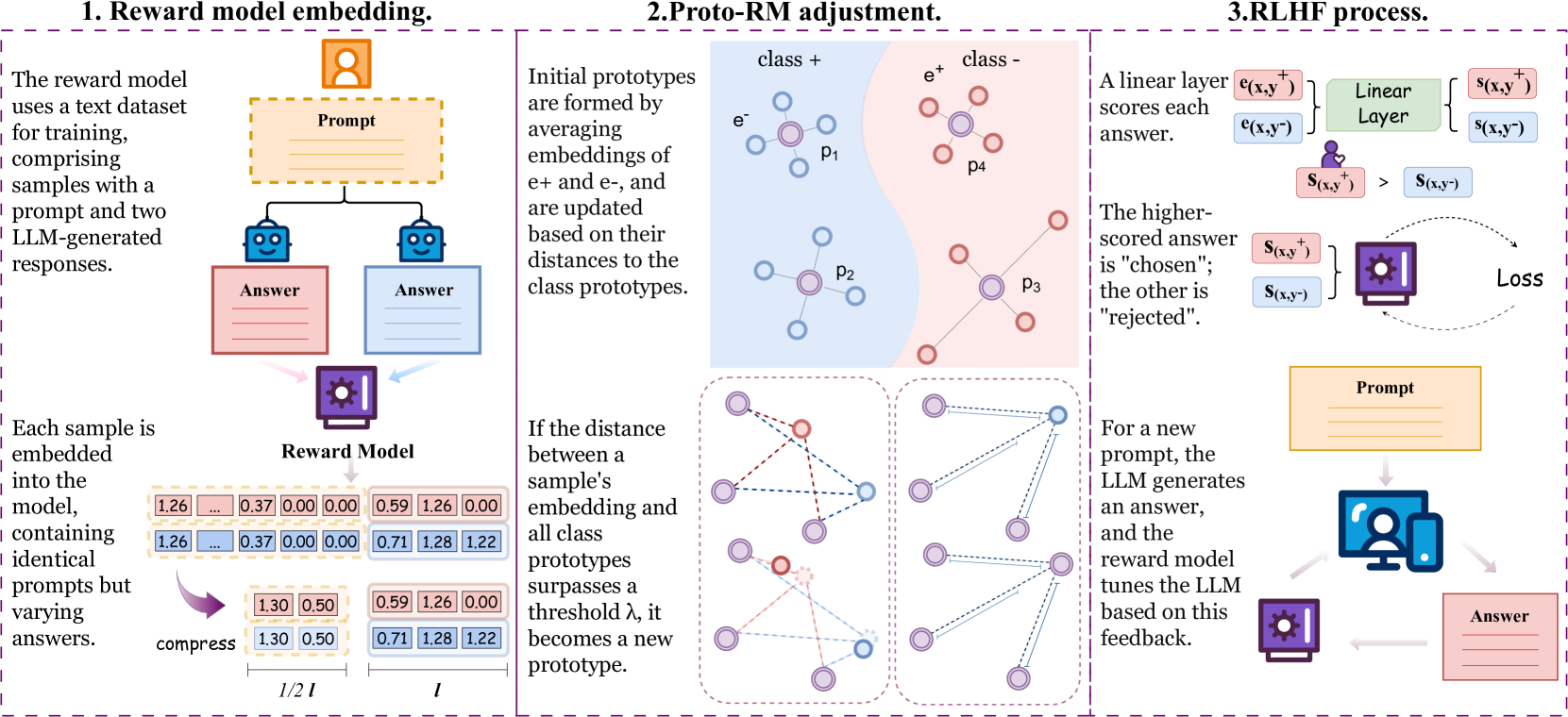
技术框架:Proto-RM的整体架构包括数据采集、原型网络构建、奖励模型训练和评估四个主要模块。首先,通过有限的人类反馈数据进行原型网络的构建,然后训练奖励模型,最后在多个任务上进行评估。
关键创新:Proto-RM的核心创新在于引入原型网络来增强奖励模型的学习能力,使其在数据有限的情况下仍能有效捕捉人类偏好。这一方法与传统的奖励模型训练方式有本质区别,后者通常依赖于大量的标注数据。
关键设计:在设计上,Proto-RM采用了特定的损失函数来优化原型网络的学习过程,同时在网络结构上进行了调整,以适应有限样本的学习需求。
🖼️ 关键图片

📊 实验亮点
实验结果表明,Proto-RM在多个数据集上显著提升了奖励模型的性能,相较于传统方法,通常在数据需求上减少了50%以上,同时在任务表现上达到了可比甚至更优的效果。
🎯 应用场景
该研究在多个领域具有潜在应用价值,尤其是在需要人类反馈的任务中,如对话系统、推荐系统和自动内容生成等。通过提高奖励模型的效率,Proto-RM能够在数据稀缺的情况下优化模型的微调过程,推动相关技术的进步。
📄 摘要(原文)
The reward model for Reinforcement Learning from Human Feedback (RLHF) has proven effective in fine-tuning Large Language Models (LLMs). Notably, collecting human feedback for RLHF can be resource-intensive and lead to scalability issues for LLMs and complex tasks. Our proposed framework Proto-RM leverages prototypical networks to enhance reward models under limited human feedback. By enabling stable and reliable structural learning from fewer samples, Proto-RM significantly enhances LLMs' adaptability and accuracy in interpreting human preferences. Extensive experiments on various datasets demonstrate that Proto-RM significantly improves the performance of reward models and LLMs in human feedback tasks, achieving comparable and usually better results than traditional methods, while requiring significantly less data. in data-limited scenarios. This research offers a promising direction for enhancing the efficiency of reward models and optimizing the fine-tuning of language models under restricted feedback conditions.