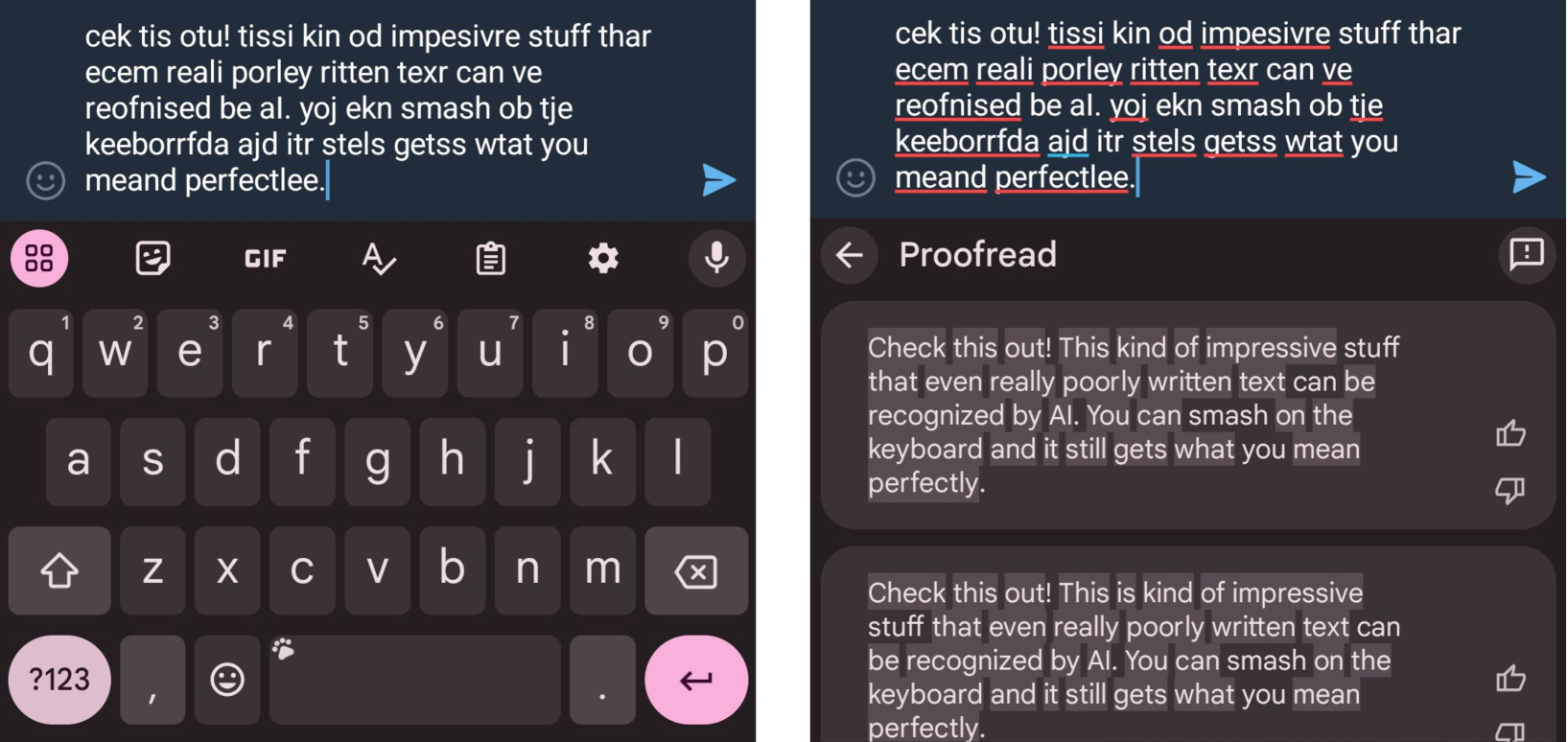
Proofread: Fixes All Errors with One Tap
作者: Renjie Liu, Yanxiang Zhang, Yun Zhu, Haicheng Sun, Yuanbo Zhang, Michael Xuelin Huang, Shanqing Cai, Lei Meng, Shumin Zhai
分类: cs.CL, cs.LG
发布日期: 2024-06-06
备注: 8 pages, 3 figures, 2 tables
💡 一句话要点
Proofread:利用大语言模型,一键修复Gboard中的句子和段落错误
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 纠错 Gboard 监督微调 强化学习 在线部署 文本校对
📋 核心要点
- 现有键盘输入法在纠错方面存在不足,用户需要手动修改,效率较低且体验不佳。
- Proofread利用大语言模型强大的文本理解和生成能力,实现一键式句子和段落级别的自动纠错。
- 实验表明,经过调优的PaLM2-XS模型在纠错任务上取得了显著的性能提升,良好率达到85.56%。
📝 摘要(中文)
本文介绍了Proofread,这是Gboard中一项由服务器端大语言模型驱动的新功能,它能够通过单次点击实现句子级别和段落级别的无缝纠错。文章详细描述了整个系统,包括数据生成、指标设计、模型调优和部署。为了获得高质量的模型,我们实施了一个针对在线使用场景的精心设计的数据合成流程,设计了多方面的评估指标,并采用了一个两阶段的调优方法来获得该功能的专用LLM:首先是用于基础质量的监督微调(SFT),然后是用于目标优化的强化学习(RL)调优方法。具体来说,我们发现在SFT阶段对Rewrite和proofread任务进行顺序调优可以产生最佳质量,并在RL调优阶段提出了全局和直接奖励以寻求进一步的改进。在人工标注的黄金数据集上进行的大量实验表明,我们调优的PaLM2-XS模型达到了85.56%的良好率。我们通过在Google Cloud中的TPU v5上提供模型服务,将该功能发布到Pixel 8设备,拥有数千名日活跃用户。量化、分桶推理、文本分割和推测解码显著降低了服务延迟。
🔬 方法详解
问题定义:论文旨在解决移动端键盘输入法中用户手动纠错效率低下的问题。现有方法通常依赖于简单的拼写检查或基于规则的纠错,无法处理复杂的语法错误和语义错误,导致用户体验不佳。
核心思路:论文的核心思路是利用大规模语言模型(LLM)强大的文本理解和生成能力,将纠错任务视为一个序列到序列的转换问题。通过训练LLM学习从错误文本到正确文本的映射关系,实现自动纠错。
技术框架:Proofread系统的整体框架包括数据生成、模型训练和在线部署三个主要阶段。数据生成阶段,构建专门针对在线使用场景的合成数据。模型训练阶段,采用两阶段调优策略,首先进行监督微调(SFT),然后进行强化学习(RL)调优。在线部署阶段,通过量化、分桶推理、文本分割和推测解码等技术优化模型推理速度。
关键创新:该论文的关键创新在于针对在线纠错场景,设计了一套完整的数据生成、模型训练和部署流程。特别是在模型训练方面,采用了两阶段调优策略,并提出了全局和直接奖励的强化学习方法,有效提升了模型的纠错性能。
关键设计:在数据生成方面,论文针对在线场景的特点,设计了特定的数据增强策略。在模型训练方面,SFT阶段采用Rewrite和proofread任务的顺序调优,RL阶段设计了全局和直接奖励函数。在模型部署方面,采用了量化、分桶推理、文本分割和推测解码等技术来降低延迟。
🖼️ 关键图片


📊 实验亮点
实验结果表明,经过两阶段调优的PaLM2-XS模型在人工标注的黄金数据集上达到了85.56%的良好率,显著优于其他基线模型。此外,通过量化、分桶推理、文本分割和推测解码等优化技术,该模型在TPU v5上的推理延迟得到了显著降低,满足了在线服务的实时性要求。
🎯 应用场景
Proofread技术可广泛应用于各种文本输入场景,例如移动端键盘输入法、在线文档编辑、语音输入校对等。该技术能够显著提高用户的输入效率和文本质量,提升用户体验。未来,该技术还可以扩展到其他语言和领域,例如机器翻译、文本摘要等。
📄 摘要(原文)
The impressive capabilities in Large Language Models (LLMs) provide a powerful approach to reimagine users' typing experience. This paper demonstrates Proofread, a novel Gboard feature powered by a server-side LLM in Gboard, enabling seamless sentence-level and paragraph-level corrections with a single tap. We describe the complete system in this paper, from data generation, metrics design to model tuning and deployment. To obtain models with sufficient quality, we implement a careful data synthetic pipeline tailored to online use cases, design multifaceted metrics, employ a two-stage tuning approach to acquire the dedicated LLM for the feature: the Supervised Fine Tuning (SFT) for foundational quality, followed by the Reinforcement Learning (RL) tuning approach for targeted refinement. Specifically, we find sequential tuning on Rewrite and proofread tasks yields the best quality in SFT stage, and propose global and direct rewards in the RL tuning stage to seek further improvement. Extensive experiments on a human-labeled golden set showed our tuned PaLM2-XS model achieved 85.56\% good ratio. We launched the feature to Pixel 8 devices by serving the model on TPU v5 in Google Cloud, with thousands of daily active users. Serving latency was significantly reduced by quantization, bucket inference, text segmentation, and speculative decoding. Our demo could be seen in \href{https://youtu.be/4ZdcuiwFU7I}{Youtube}.