Time Sensitive Knowledge Editing through Efficient Finetuning
作者: Xiou Ge, Ali Mousavi, Edouard Grave, Armand Joulin, Kun Qian, Benjamin Han, Mostafa Arefiyan, Yunyao Li
分类: cs.CL, cs.AI, cs.LG
发布日期: 2024-06-06 (更新: 2024-07-23)
备注: ACL 2024 main
💡 一句话要点
提出基于高效微调的时间敏感知识编辑方法,提升LLM知识更新能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 知识编辑 参数高效微调 大型语言模型 时间敏感知识 多跳推理
📋 核心要点
- 现有知识编辑方法在处理复杂多跳推理查询时表现不佳,且编辑效率低,难以应用于大规模知识更新。
- 该论文探索使用参数高效微调(PEFT)技术作为知识编辑的替代方案,旨在提升知识更新效率和模型推理能力。
- 实验结果表明,PEFT方法在时间敏感的知识编辑任务中优于传统的定位和编辑技术,验证了其有效性。
📝 摘要(中文)
大型语言模型(LLM)在各种任务中展现了令人印象深刻的能力,并为许多领域带来了变革性变化。然而,一旦预训练完成,保持LLM中的知识最新仍然是一个挑战。因此,设计有效的方法来更新过时的知识并将新知识引入LLM至关重要。现有的定位和编辑知识编辑(KE)方法存在两个局限性。首先,通过这些方法进行编辑后的LLM在回答需要多跳推理的复杂查询时,通常能力较差。其次,这种定位和编辑方法执行知识编辑的运行时间过长,使得在实践中进行大规模KE变得不可行。在本文中,我们探索参数高效微调(PEFT)技术作为KE的替代方案。我们整理了一个更全面的时间KE数据集,其中包含知识更新和知识注入示例,用于KE性能基准测试。我们进一步探讨了微调对LLM中一系列层在多跳QA任务上的影响。我们发现,对于时间敏感的知识编辑,PEFT比定位和编辑技术表现更好。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)知识更新的问题,即如何高效地更新LLM中过时的知识,并注入新的知识。现有方法,如locate-and-edit,存在两个主要痛点:一是编辑后的LLM在处理需要多跳推理的复杂问题时性能下降;二是编辑过程耗时过长,难以应用于大规模知识编辑。
核心思路:论文的核心思路是利用参数高效微调(PEFT)技术来替代传统的locate-and-edit方法进行知识编辑。PEFT通过只微调少量参数,避免了对整个模型进行大规模修改,从而提高了编辑效率,并尽可能保留了模型原有的推理能力。
技术框架:论文主要包含以下几个阶段:1) 构建一个更全面的时间敏感知识编辑数据集,包含知识更新和知识注入的例子;2) 探索PEFT技术在知识编辑中的应用,并与locate-and-edit方法进行比较;3) 研究微调不同层对多跳QA任务的影响,找到最佳的微调策略。
关键创新:论文的关键创新在于将参数高效微调(PEFT)技术应用于知识编辑任务,并证明了其在效率和性能上的优越性。与传统的locate-and-edit方法相比,PEFT能够更快地完成知识编辑,并且在处理复杂推理问题时表现更好。
关键设计:论文的关键设计包括:1) 精心设计的知识编辑数据集,包含知识更新和知识注入两种类型;2) 针对不同层进行微调的实验,以确定最佳的微调层数和参数;3) 使用多跳QA任务来评估编辑后LLM的推理能力。
🖼️ 关键图片

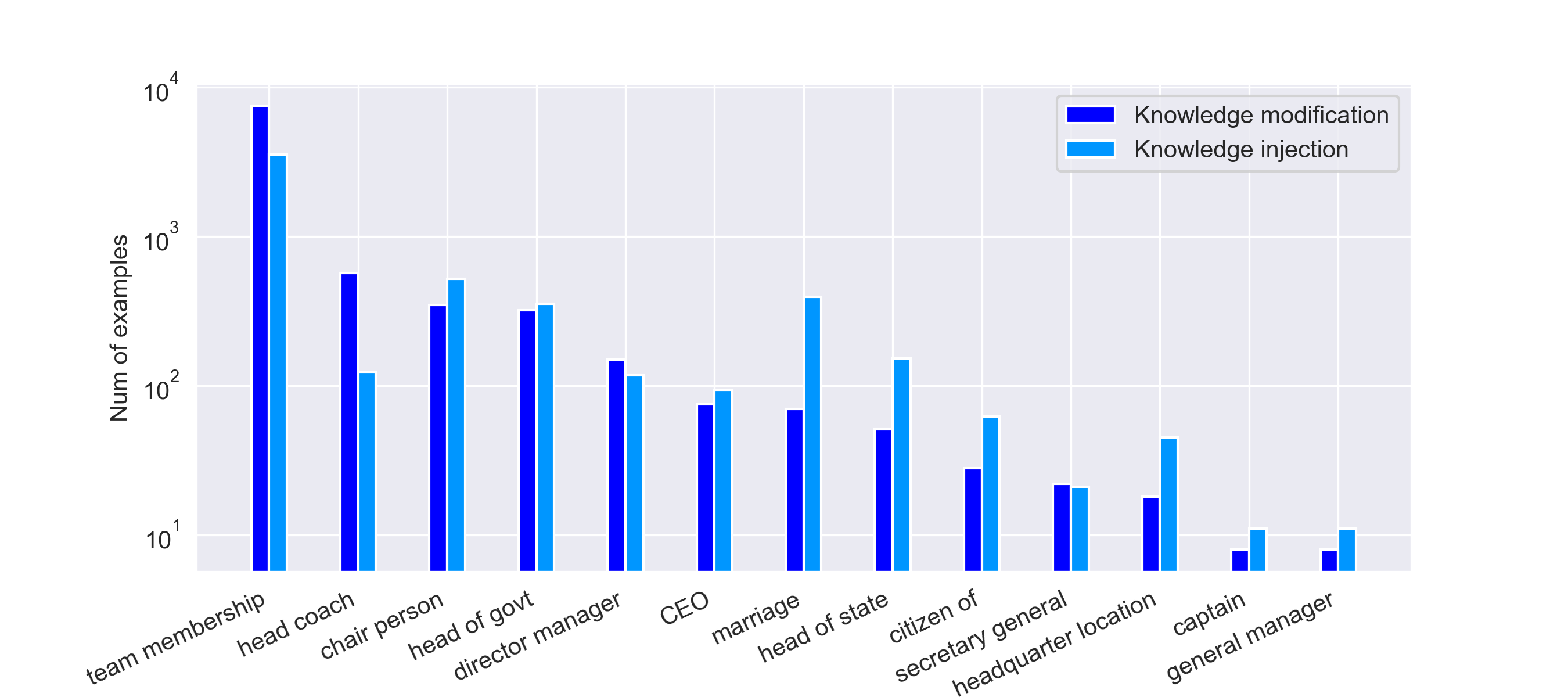

📊 实验亮点
实验结果表明,PEFT方法在时间敏感的知识编辑任务中优于传统的locate-and-edit技术。具体来说,PEFT在知识更新和知识注入方面都取得了显著的性能提升,并且在处理多跳QA任务时,能够更好地保持模型的推理能力。此外,PEFT的编辑效率也远高于locate-and-edit方法,使其更适用于大规模知识编辑。
🎯 应用场景
该研究成果可应用于需要频繁更新知识的领域,例如智能客服、搜索引擎、知识图谱等。通过高效的知识编辑,可以使LLM始终保持最新的信息,从而提供更准确、更可靠的服务。此外,该方法还可以用于个性化知识定制,根据用户的需求注入特定的知识。
📄 摘要(原文)
Large Language Models (LLMs) have demonstrated impressive capability in different tasks and are bringing transformative changes to many domains. However, keeping the knowledge in LLMs up-to-date remains a challenge once pretraining is complete. It is thus essential to design effective methods to both update obsolete knowledge and induce new knowledge into LLMs. Existing locate-and-edit knowledge editing (KE) method suffers from two limitations. First, the post-edit LLMs by such methods generally have poor capability in answering complex queries that require multi-hop reasoning. Second, the long run-time of such locate-and-edit methods to perform knowledge edits make it infeasible for large scale KE in practice. In this paper, we explore Parameter-Efficient Fine-Tuning (PEFT) techniques as an alternative for KE. We curate a more comprehensive temporal KE dataset with both knowledge update and knowledge injection examples for KE performance benchmarking. We further probe the effect of fine-tuning on a range of layers in an LLM for the multi-hop QA task. We find that PEFT performs better than locate-and-edit techniques for time-sensitive knowledge edits.