Exploring the Latest LLMs for Leaderboard Extraction
作者: Salomon Kabongo, Jennifer D'Souza, Sören Auer
分类: cs.CL, cs.AI
发布日期: 2024-06-06 (更新: 2024-07-08)
💡 一句话要点
探索大型语言模型在AI研究论文排行榜信息抽取中的应用
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 信息抽取 排行榜提取 AI研究 自然语言处理
📋 核心要点
- 人工智能研究中,从论文中自动提取排行榜信息是一项复杂任务,现有方法效率较低。
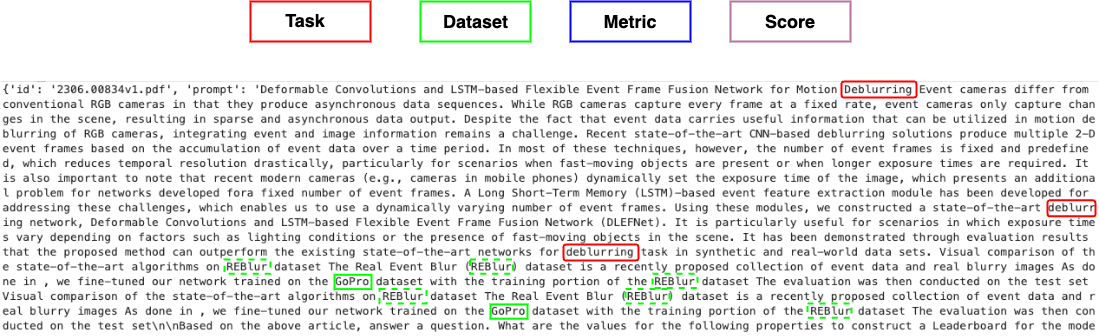
- 本文探索利用大型语言模型(LLMs)直接从论文中提取(任务、数据集、指标、分数)四元组。
- 实验评估了Mistral 7B、Llama-2、GPT-4-Turbo和GPT-4等模型在不同上下文输入下的性能,揭示了各自的优缺点。
📝 摘要(中文)
本文研究了不同的大型语言模型(LLMs)——Mistral 7B、Llama-2、GPT-4-Turbo和GPT-4在从AI研究文章中提取排行榜信息方面的有效性。我们探索了三种类型的上下文输入模型:DocTAET(文档标题、摘要、实验设置和表格信息)、DocREC(结果、实验和结论)和DocFULL(完整文档)。我们的综合研究评估了这些模型在从研究论文中生成(任务、数据集、指标、分数)四元组方面的性能。研究结果揭示了每种模型和上下文类型的优势和局限性,为未来的AI研究自动化工作提供了有价值的指导。
🔬 方法详解
问题定义:论文旨在解决从AI研究论文中自动提取排行榜信息的任务。现有方法通常需要人工干预或依赖于复杂的规则,效率低下且容易出错。此外,不同论文的格式和表达方式各异,使得自动化提取更具挑战性。
核心思路:论文的核心思路是利用大型语言模型(LLMs)的强大自然语言理解和生成能力,将排行榜信息提取任务转化为一个文本生成问题。通过向LLM提供不同类型的上下文信息,引导其生成包含(任务、数据集、指标、分数)四元组的结构化数据。
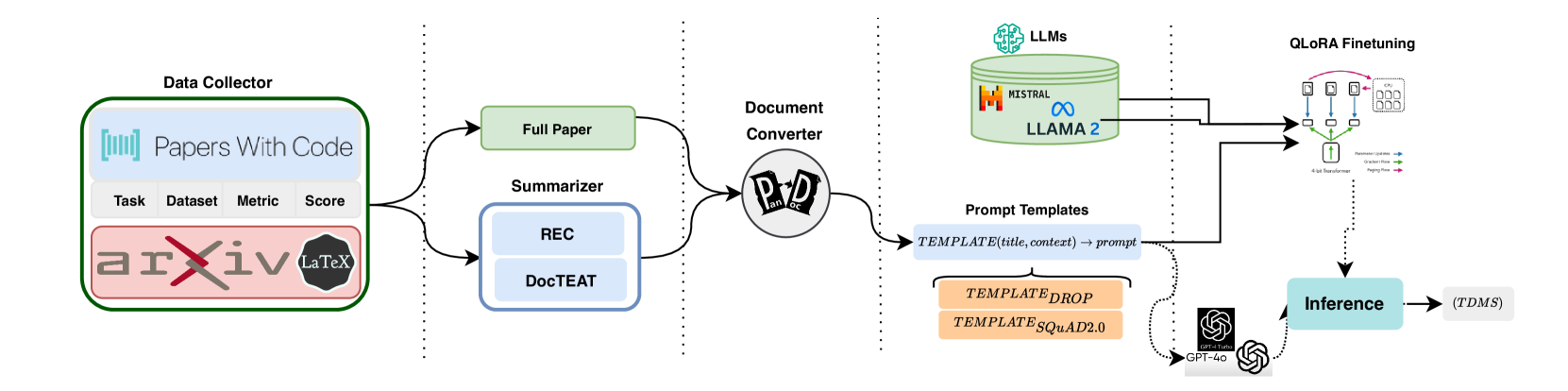
技术框架:整体流程包括以下几个步骤:1) 选择目标AI研究论文;2) 准备不同类型的上下文输入,包括DocTAET、DocREC和DocFULL;3) 将上下文输入提供给不同的LLM(Mistral 7B、Llama-2、GPT-4-Turbo和GPT-4);4) LLM生成包含排行榜信息的四元组;5) 评估生成的四元组的准确性和完整性。
关键创新:论文的关键创新在于探索了不同类型的上下文输入对LLM性能的影响。通过比较DocTAET、DocREC和DocFULL三种上下文类型,揭示了哪些信息对于LLM提取排行榜信息至关重要。此外,论文还比较了不同LLM在同一任务上的表现,为选择合适的LLM提供了指导。
关键设计:论文的关键设计包括:1) 选择合适的LLM,如Mistral 7B、Llama-2、GPT-4-Turbo和GPT-4;2) 设计不同类型的上下文输入,如DocTAET、DocREC和DocFULL;3) 使用合适的评估指标,如准确率和召回率,来评估生成的四元组的质量;4) 对LLM的prompt进行优化,以提高生成四元组的准确性和完整性。
🖼️ 关键图片

📊 实验亮点
实验结果表明,不同的LLM和上下文类型在排行榜信息提取任务上表现出不同的优势。例如,GPT-4在大多数情况下表现最佳,但计算成本较高。DocTAET上下文在某些情况下也能取得较好的效果,且计算成本较低。论文详细对比了不同模型和上下文类型的性能,为实际应用提供了参考。
🎯 应用场景
该研究成果可应用于自动化AI研究评估、构建AI模型排行榜、辅助科研人员快速了解领域进展等方面。通过自动提取论文中的关键信息,可以大大提高科研效率,加速AI技术的发展。未来,该技术还可以扩展到其他领域,如医疗、金融等,实现更广泛的知识抽取和应用。
📄 摘要(原文)
The rapid advancements in Large Language Models (LLMs) have opened new avenues for automating complex tasks in AI research. This paper investigates the efficacy of different LLMs-Mistral 7B, Llama-2, GPT-4-Turbo and GPT-4.o in extracting leaderboard information from empirical AI research articles. We explore three types of contextual inputs to the models: DocTAET (Document Title, Abstract, Experimental Setup, and Tabular Information), DocREC (Results, Experiments, and Conclusions), and DocFULL (entire document). Our comprehensive study evaluates the performance of these models in generating (Task, Dataset, Metric, Score) quadruples from research papers. The findings reveal significant insights into the strengths and limitations of each model and context type, providing valuable guidance for future AI research automation efforts.