What Languages are Easy to Language-Model? A Perspective from Learning Probabilistic Regular Languages
作者: Nadav Borenstein, Anej Svete, Robin Chan, Josef Valvoda, Franz Nowak, Isabelle Augenstein, Eleanor Chodroff, Ryan Cotterell
分类: cs.CL
发布日期: 2024-06-06 (更新: 2025-01-12)
备注: Accepted to ACL 2024
💡 一句话要点
研究RNN和Transformer语言模型学习概率正则语言的能力,揭示影响学习的关键因素。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 语言模型 正则语言 RNN Transformer 可学习性
📋 核心要点
- 现有工作主要关注语言模型学习的理论极限,缺乏对经验可学习性的深入研究。
- 本文通过研究RNN和Transformer学习概率正则语言的能力,评估语言模型的学习能力。
- 实验表明RLM的秩和采样字符串的预期长度是影响RNN和Transformer学习能力的关键因素。
📝 摘要(中文)
本文旨在研究大型语言模型(LM)的学习能力。从形式语言的角度,将此问题定义为字符串分布的可学习性问题。与侧重理论极限的前人工作不同,本文关注经验可学习性。不同于以往的经验研究,本文在神经LM的“主场”——学习概率语言——上评估它们,而非将它们作为形式语言的分类器。具体而言,本文研究了RNN和Transformer LM学习正则LM(RLM)的能力。通过实验测试了RLM的各种复杂性参数以及神经LM的隐藏状态大小对RLM可学习性的影响。研究发现,RLM的秩(对应于其条件分布的logits所跨越的线性空间的大小)和采样字符串的预期长度是RNN和Transformer学习能力的重要且显著的预测指标。其他一些预测指标也达到了显著性水平,但在RNN和Transformer之间存在不同的模式。
🔬 方法详解
问题定义:本文旨在研究大型语言模型(LLM)学习概率正则语言的能力。现有的研究主要集中在理论分析,缺乏对实际应用中LLM学习能力的经验评估。此外,以往的经验研究通常将LLM作为形式语言的分类器,而非直接评估其生成概率语言的能力。
核心思路:本文的核心思路是将语言模型学习问题形式化为字符串分布的可学习性问题,并重点关注概率正则语言(RLM)。通过控制RLM的复杂度和LLM的结构参数,研究它们之间的关系,从而揭示影响LLM学习能力的关键因素。这种方法能够更直接地评估LLM在生成概率语言方面的能力。
技术框架:本文的实验框架主要包括以下几个步骤:1) 生成不同复杂度的RLM,复杂度的衡量指标包括RLM的秩和采样字符串的预期长度等;2) 使用RNN和Transformer语言模型对生成的RLM进行训练;3) 评估训练后的语言模型在生成RLM上的性能,例如使用困惑度(perplexity)作为评估指标;4) 分析RLM的复杂度参数与语言模型性能之间的关系,从而确定影响学习能力的关键因素。
关键创新:本文最重要的技术创新在于其研究视角,即从概率正则语言的可学习性角度来评估语言模型的学习能力。与以往将语言模型作为分类器的研究不同,本文直接评估语言模型生成概率语言的能力,从而更直接地反映了语言模型的本质。此外,本文还发现了RLM的秩和采样字符串的预期长度是影响RNN和Transformer学习能力的关键因素。
关键设计:在实验设计方面,本文精心选择了RLM的复杂度参数,例如RLM的秩和采样字符串的预期长度,这些参数能够有效地反映RLM的复杂程度。在模型选择方面,本文选择了RNN和Transformer两种经典的语言模型,并控制了它们的隐藏状态大小等参数。在评估指标方面,本文使用了困惑度(perplexity)作为评估指标,该指标能够有效地衡量语言模型生成概率语言的能力。
🖼️ 关键图片
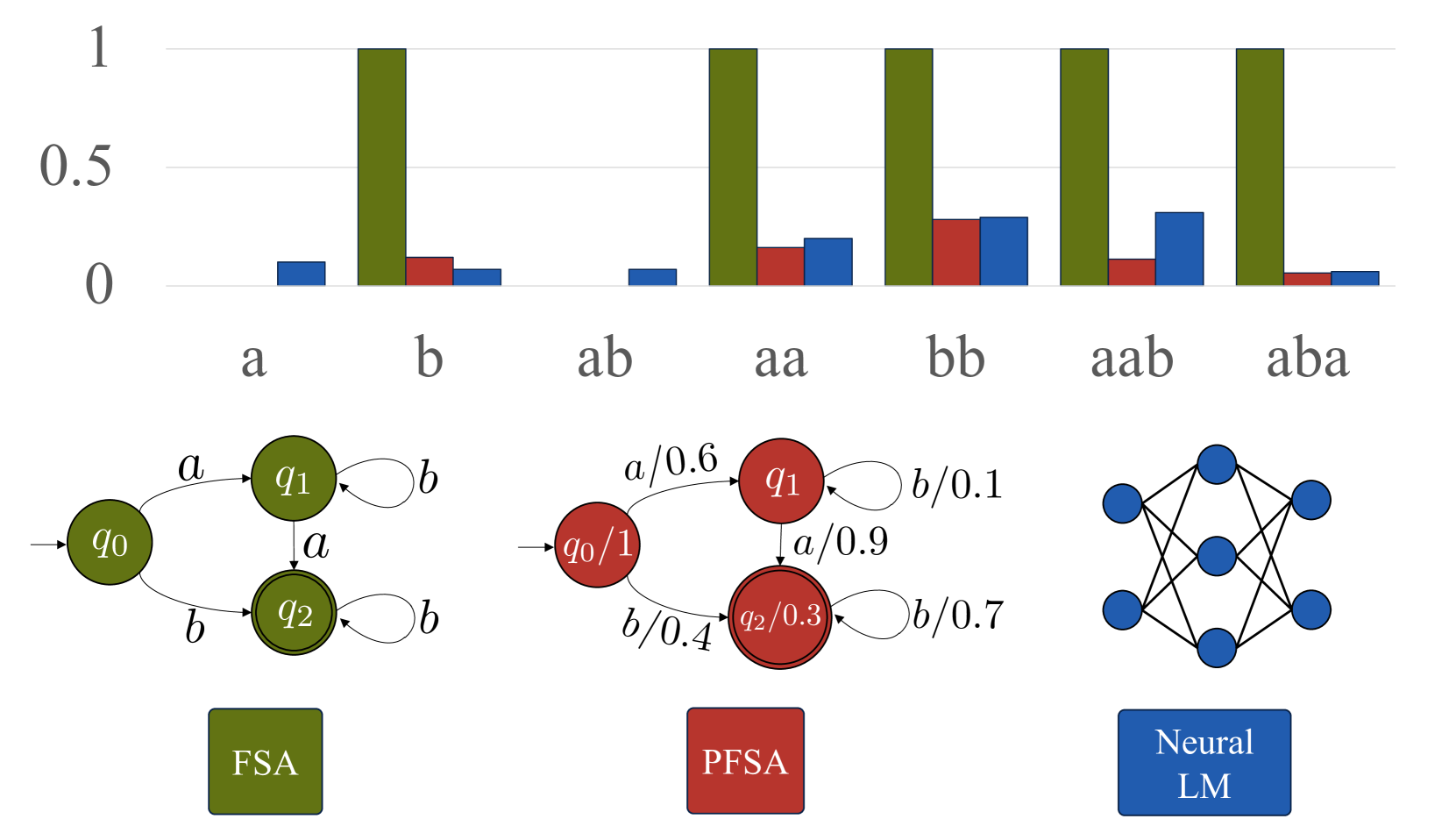
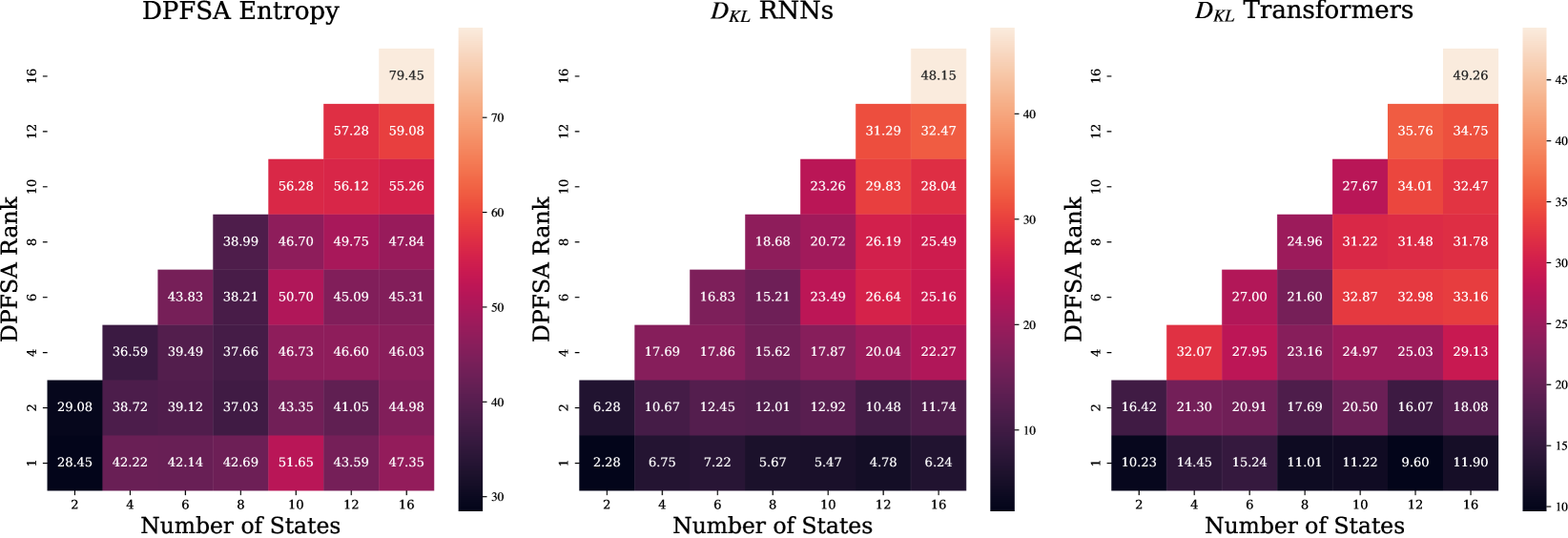
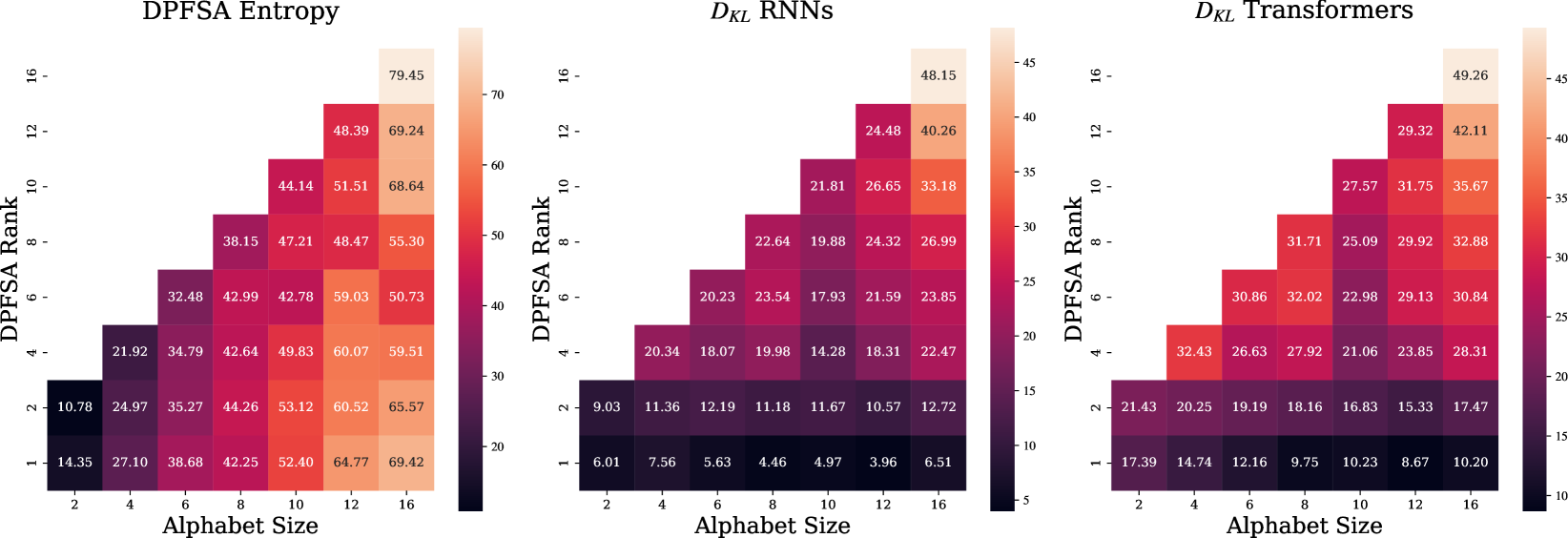
📊 实验亮点
实验结果表明,RLM的秩和采样字符串的预期长度是影响RNN和Transformer学习能力的关键因素。具体来说,当RLM的秩较高或采样字符串的预期长度较长时,RNN和Transformer的学习难度都会增加。此外,研究还发现RNN和Transformer在学习不同类型的RLM时表现出不同的模式。
🎯 应用场景
该研究成果有助于理解大型语言模型的学习机制和能力边界,为设计更有效的语言模型和训练策略提供理论指导。此外,该研究还可以应用于自然语言生成、语音识别等领域,提高相关任务的性能。
📄 摘要(原文)
What can large language models learn? By definition, language models (LM) are distributions over strings. Therefore, an intuitive way of addressing the above question is to formalize it as a matter of learnability of classes of distributions over strings. While prior work in this direction focused on assessing the theoretical limits, in contrast, we seek to understand the empirical learnability. Unlike prior empirical work, we evaluate neural LMs on their home turf-learning probabilistic languages-rather than as classifiers of formal languages. In particular, we investigate the learnability of regular LMs (RLMs) by RNN and Transformer LMs. We empirically test the learnability of RLMs as a function of various complexity parameters of the RLM and the hidden state size of the neural LM. We find that the RLM rank, which corresponds to the size of linear space spanned by the logits of its conditional distributions, and the expected length of sampled strings are strong and significant predictors of learnability for both RNNs and Transformers. Several other predictors also reach significance, but with differing patterns between RNNs and Transformers.