Benchmark Data Contamination of Large Language Models: A Survey
作者: Cheng Xu, Shuhao Guan, Derek Greene, M-Tahar Kechadi
分类: cs.CL
发布日期: 2024-06-06
备注: 31 pages, 7 figures, 3 tables
💡 一句话要点
综述大型语言模型基准数据污染问题,并探讨缓解策略与未来方向
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 基准数据污染 模型评估 自然语言处理 综述研究
📋 核心要点
- 大型语言模型评估面临基准数据污染的挑战,导致评估结果失真,无法准确反映模型的真实能力。
- 该综述旨在全面分析基准数据污染问题,并探讨可行的替代评估方法,以提高评估的可靠性。
- 文章深入研究了缓解基准数据污染风险的挑战和未来发展方向,为后续研究提供了有价值的参考。
📝 摘要(中文)
GPT-4、Claude-3和Gemini等大型语言模型(LLMs)的快速发展极大地推动了自然语言处理领域。然而,这也带来了一个重要问题,即基准数据污染(BDC)。当语言模型无意中从其训练数据中包含了评估基准信息时,就会发生这种情况,导致评估阶段的性能不准确或不可靠。本文综述了LLM评估中BDC这一复杂挑战,并探讨了替代评估方法,以减轻与传统基准相关的风险。本文还研究了缓解BDC风险的挑战和未来方向,强调了该问题的复杂性以及对创新解决方案的需求,以确保LLM评估在实际应用中的可靠性。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLMs)评估中存在的基准数据污染(Benchmark Data Contamination, BDC)问题。现有方法在评估LLMs时,由于模型可能在训练过程中接触过评估数据集,导致评估结果虚高,无法真实反映模型的泛化能力。现有方法难以有效检测和缓解这种污染,使得评估结果的可靠性受到质疑。
核心思路:论文的核心思路是对现有关于LLM基准数据污染的研究进行系统性的综述,分析BDC产生的原因、影响以及现有的缓解策略。通过梳理现有研究,找出当前方法的不足之处,并探讨未来可能的研究方向,从而为解决BDC问题提供指导。
技术框架:该论文属于综述性质,没有提出新的技术框架。其主要框架是对现有文献进行分类和总结,包括:BDC的定义和影响、BDC的检测方法、BDC的缓解策略以及未来研究方向。论文通过对这些方面的深入分析,为读者提供一个全面的BDC问题理解。
关键创新:该论文的关键创新在于对现有关于LLM基准数据污染的研究进行了系统的整理和分析,并指出了当前研究的不足之处和未来可能的研究方向。它并没有提出新的技术方法,而是通过综述的方式,为后续研究者提供了一个清晰的研究路线图。
关键设计:由于是综述论文,没有涉及具体的参数设置、损失函数或网络结构等技术细节。论文的关键设计在于其对现有文献的分类和总结方式,以及对未来研究方向的展望。
🖼️ 关键图片
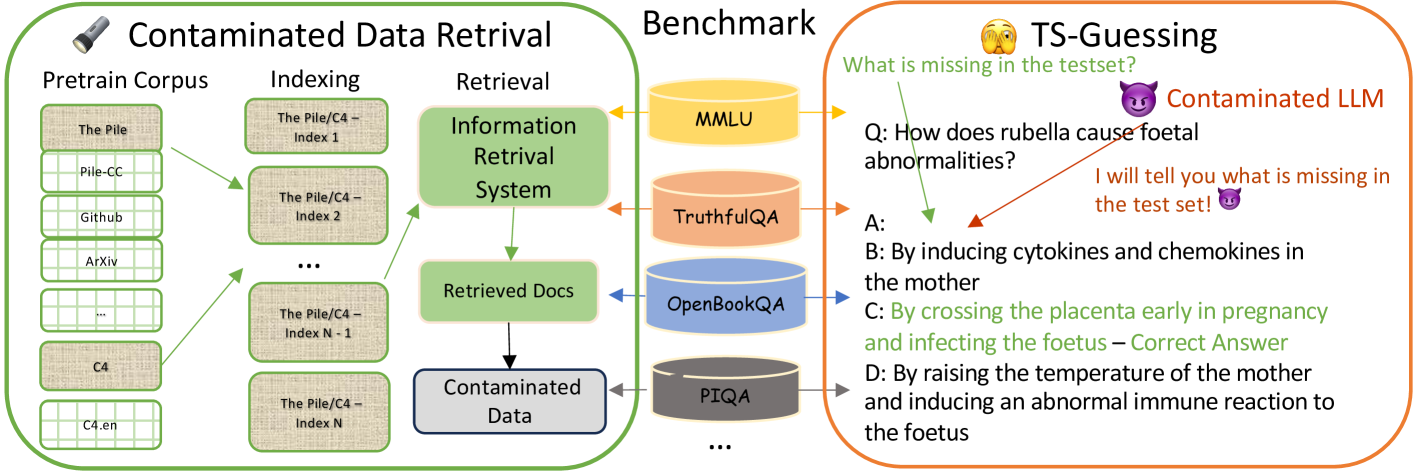
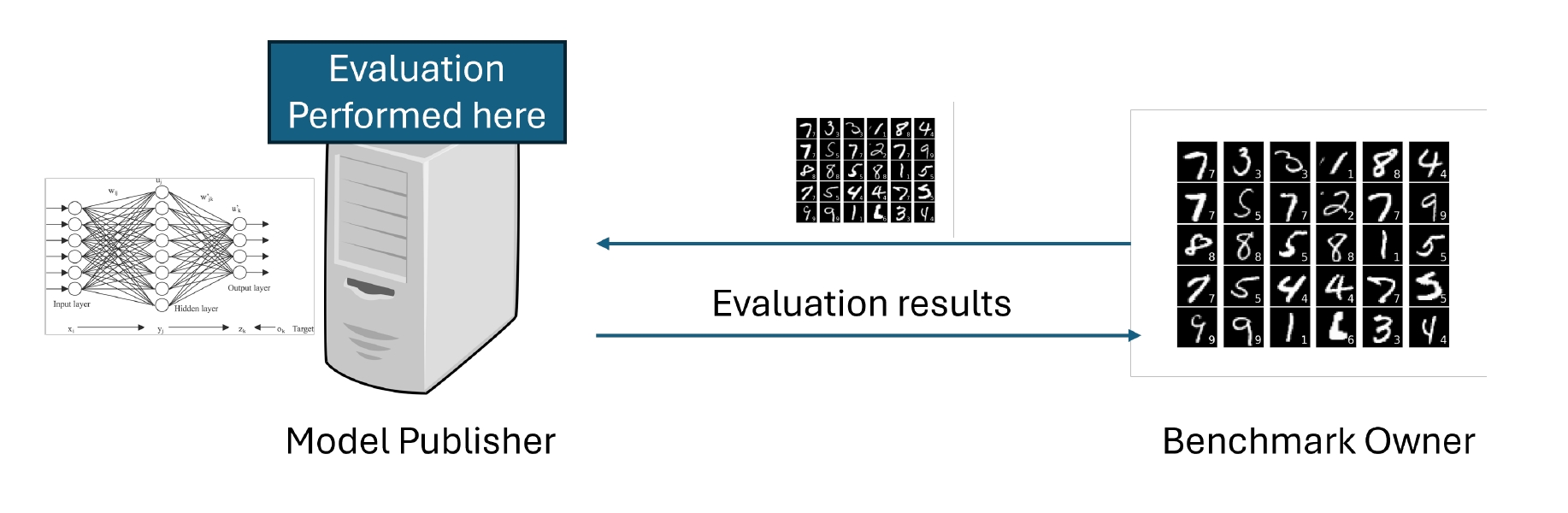

📊 实验亮点
该论文系统性地综述了大型语言模型基准数据污染问题,总结了现有检测和缓解策略,并指出了未来研究方向。虽然没有提供具体的实验数据,但其对现有研究的梳理和分析为后续研究提供了重要的参考价值,有助于推动该领域的发展。
🎯 应用场景
该研究对大型语言模型的开发和评估具有重要意义。通过更好地理解和缓解基准数据污染问题,可以提高LLM评估的可靠性,从而推动LLM在各个领域的应用,例如智能客服、机器翻译、文本生成等。更可靠的评估方法能够帮助开发者选择更合适的模型,并更好地了解模型的优缺点,从而开发出更强大的LLM。
📄 摘要(原文)
The rapid development of Large Language Models (LLMs) like GPT-4, Claude-3, and Gemini has transformed the field of natural language processing. However, it has also resulted in a significant issue known as Benchmark Data Contamination (BDC). This occurs when language models inadvertently incorporate evaluation benchmark information from their training data, leading to inaccurate or unreliable performance during the evaluation phase of the process. This paper reviews the complex challenge of BDC in LLM evaluation and explores alternative assessment methods to mitigate the risks associated with traditional benchmarks. The paper also examines challenges and future directions in mitigating BDC risks, highlighting the complexity of the issue and the need for innovative solutions to ensure the reliability of LLM evaluation in real-world applications.