ArMeme: Propagandistic Content in Arabic Memes
作者: Firoj Alam, Abul Hasnat, Fatema Ahmed, Md Arid Hasan, Maram Hasanain
分类: cs.CL, cs.AI, cs.CV
发布日期: 2024-06-06 (更新: 2024-10-06)
备注: disinformation, misinformation, factuality, harmfulness, fake news, propaganda, multimodality, text, images
💡 一句话要点
构建阿拉伯语宣传模因数据集,为检测多模态有害信息提供资源。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 阿拉伯语模因 宣传内容检测 多模态分析 数据集构建 社交媒体分析
📋 核心要点
- 现有方法主要集中于英语等高资源语言,缺乏针对阿拉伯语等中低资源语言的多模态宣传内容检测研究。
- 本研究通过构建并标注包含约6K个阿拉伯语模因的数据集,为阿拉伯语多模态研究提供宝贵资源。
- 该数据集的发布旨在促进开发检测阿拉伯语模因中宣传内容的计算工具,从而减少有害信息传播。
📝 摘要(中文)
随着数字通信的兴起,模因已成为文化和政治表达的重要媒介,但常被用于误导受众。识别此类具有误导性和说服性的多模态内容变得越来越重要,社交媒体平台、政策制定者和广大社会都对此表示关注,因为它们经常对个人、组织和社会造成危害。虽然已经有针对资源丰富的语言(如英语)开发基于人工智能的自动系统的努力,但对于中低资源语言来说,这方面的研究相对较少甚至没有。本研究的重点是开发一个带有宣传内容手动注释的阿拉伯语模因数据集。我们从各种社交媒体平台收集并标注了约6K个阿拉伯语模因,这是阿拉伯语多模态研究的首个资源。我们提供了一个全面的分析,旨在开发用于检测它们(宣传内容)的计算工具。我们将向社区公开这些数据。
🔬 方法详解
问题定义:论文旨在解决阿拉伯语模因中宣传内容的自动识别问题。现有方法主要集中在高资源语言(如英语),缺乏针对阿拉伯语模因的有效检测方法。这导致阿拉伯语社交媒体平台上,具有误导性和煽动性的模因难以被有效识别和控制,对社会稳定和个人权益构成潜在威胁。
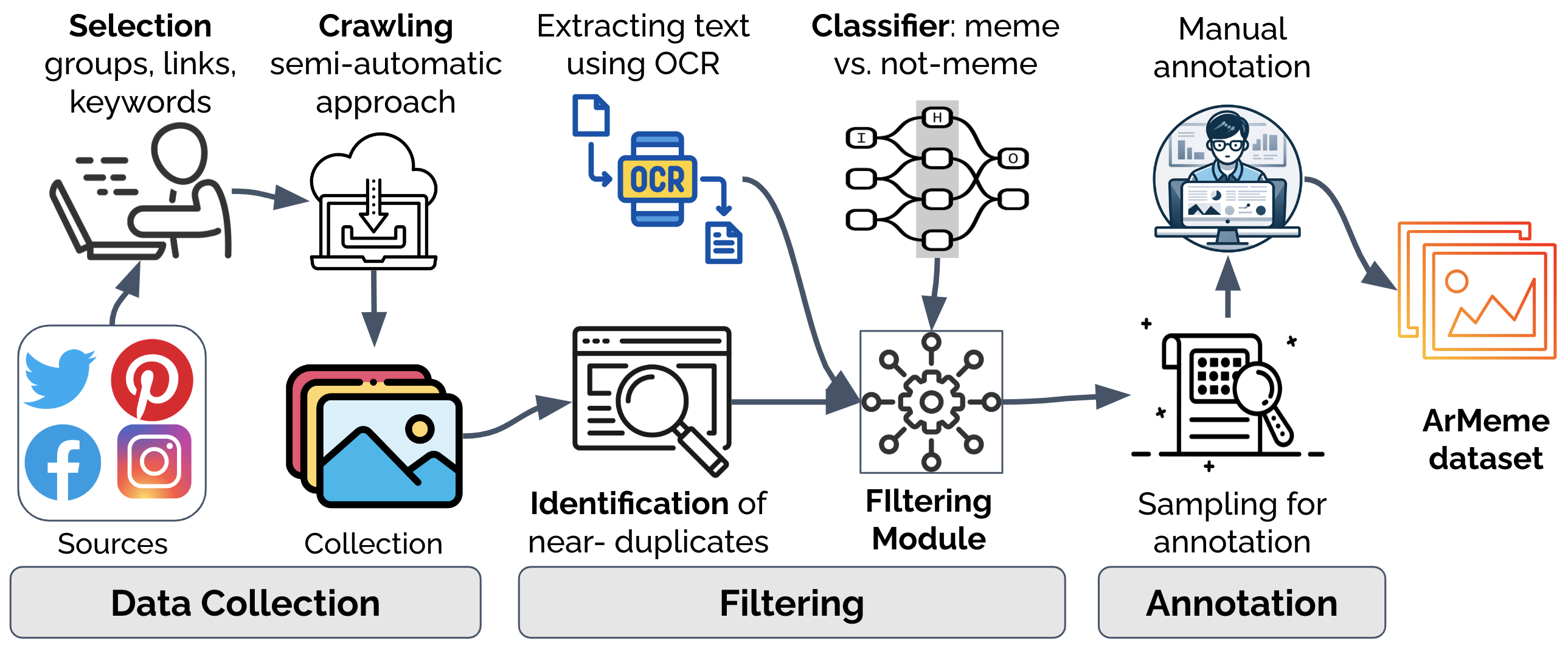
核心思路:论文的核心思路是通过构建一个带有手动标注的阿拉伯语模因数据集,为后续研究提供数据基础。该数据集包含约6000个阿拉伯语模因,并标注了其中的宣传内容。通过对该数据集进行分析,可以为开发自动检测阿拉伯语模因中宣传内容的计算工具提供指导。
技术框架:论文主要工作集中在数据集的构建和分析上,并未提出具体的模型框架。数据集构建流程包括:1) 从社交媒体平台收集阿拉伯语模因;2) 对模因进行清洗和预处理;3) 由人工标注员对模因中的宣传内容进行标注。论文对数据集进行了统计分析,例如宣传内容的类型分布、模因的来源分布等。
关键创新:该研究的关键创新在于构建了首个公开可用的、带有宣传内容标注的阿拉伯语模因数据集。这填补了阿拉伯语多模态研究领域的空白,为后续研究提供了宝贵的数据资源。
关键设计:论文的关键设计在于数据集的标注规范。标注规范需要清晰明确,以保证标注质量的一致性和可靠性。具体的标注细节(例如,宣传内容的类型、标注人员的培训等)在论文中未详细描述,属于未知信息。
🖼️ 关键图片


📊 实验亮点
该研究构建了首个包含约6K个阿拉伯语模因,并带有宣传内容标注的数据集。该数据集的发布为阿拉伯语多模态研究提供了宝贵资源,为后续开发自动检测阿拉伯语模因中宣传内容的计算工具奠定了基础。具体的实验结果和性能数据在摘要中未提及,属于未知信息。
🎯 应用场景
该研究成果可应用于社交媒体平台的内容审核、舆情监控和虚假信息检测等领域。通过自动识别阿拉伯语模因中的宣传内容,可以有效减少有害信息的传播,维护社会稳定和公共利益。未来,该数据集可用于训练更强大的多模态分类模型,提升阿拉伯语宣传内容检测的准确率。
📄 摘要(原文)
With the rise of digital communication, memes have become a significant medium for cultural and political expression that is often used to mislead audiences. Identification of such misleading and persuasive multimodal content has become more important among various stakeholders, including social media platforms, policymakers, and the broader society as they often cause harm to individuals, organizations, and/or society. While there has been effort to develop AI-based automatic systems for resource-rich languages (e.g., English), it is relatively little to none for medium to low resource languages. In this study, we focused on developing an Arabic memes dataset with manual annotations of propagandistic content. We annotated ~6K Arabic memes collected from various social media platforms, which is a first resource for Arabic multimodal research. We provide a comprehensive analysis aiming to develop computational tools for their detection. We will make them publicly available for the community.