Speculative Decoding via Early-exiting for Faster LLM Inference with Thompson Sampling Control Mechanism
作者: Jiahao Liu, Qifan Wang, Jingang Wang, Xunliang Cai
分类: cs.CL
发布日期: 2024-06-06
备注: Accepted by ACL 2024 (Findings)
💡 一句话要点
提出基于早退机制和Thompson采样的推测解码方法,加速LLM推理。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 推测解码 早退机制 Thompson采样 大型语言模型 LLM推理加速
📋 核心要点
- 现有LLM推理成本高昂,限制了其在实际场景中的应用,需要更高效的推理方法。
- 提出早退推测解码(EESD)方法,利用部分LLM生成草稿tokens,并通过早退结构加速推理。
- 实验结果表明,EESD方法在13B和70B模型上均能显著加速token解码速度。
📝 摘要(中文)
大型语言模型(LLMs)的快速发展带来了显著的进步,但随之而来的高昂推理成本给实际应用带来了挑战。为了解决这些问题,我们提出了一种名为早退推测解码(EESD)的新方法,实现了无损加速。具体来说,EESD利用LLM的一部分来生成草稿tokens,并在前N层之后加入早退结构。为了提高草稿tokens的质量,我们整合了一种自蒸馏方法。这种早退设计不仅降低了部署和训练成本,还显著提高了token生成速度。此外,我们引入了一种新的采样机制,利用Thompson采样来调节生成过程,自动确定每轮草稿tokens的数量。然后,原始LLM通过单次前向传播来验证这些草稿tokens,从而保证最终输出文本保持与原始自回归解码一致的分布。在13B和70B模型上的实验结果表明,与先前的方法相比,我们的方法以明显更快的速度解码tokens,证明了我们方法的有效性。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLMs)推理成本高的问题。现有自回归解码方法计算复杂度高,导致推理速度慢,难以满足实际应用的需求。
核心思路:论文的核心思路是利用一个较小的模型(LLM的一部分)快速生成草稿tokens,然后使用原始LLM验证这些草稿tokens。通过这种推测解码的方式,减少原始LLM的计算量,从而加速推理过程。早退机制进一步减少了小模型的计算量。
技术框架:EESD包含以下主要模块:1. 草稿模型:由原始LLM的前N层加上早退结构组成,用于快速生成草稿tokens。2. 自蒸馏模块:用于提高草稿模型生成的草稿tokens的质量。3. Thompson采样模块:用于动态调整每轮生成的草稿tokens数量。4. 验证模型:原始LLM,用于验证草稿tokens的正确性。整体流程是:首先,草稿模型生成草稿tokens;然后,Thompson采样模块决定草稿tokens的数量;最后,验证模型验证这些草稿tokens,并输出最终结果。
关键创新:论文的关键创新点在于:1. 早退结构:在草稿模型中引入早退结构,进一步减少计算量。2. Thompson采样:使用Thompson采样动态调整草稿tokens的数量,平衡了推理速度和准确性。3. 自蒸馏:提升草稿模型生成token的质量。
关键设计:早退结构的设计是在LLM的前N层后添加额外的分类器,用于预测下一个token。Thompson采样使用Beta分布来建模每个token被接受的概率,并根据采样结果动态调整草稿tokens的数量。自蒸馏模块使用原始LLM的输出作为目标,训练草稿模型,提高其生成token的质量。
🖼️ 关键图片

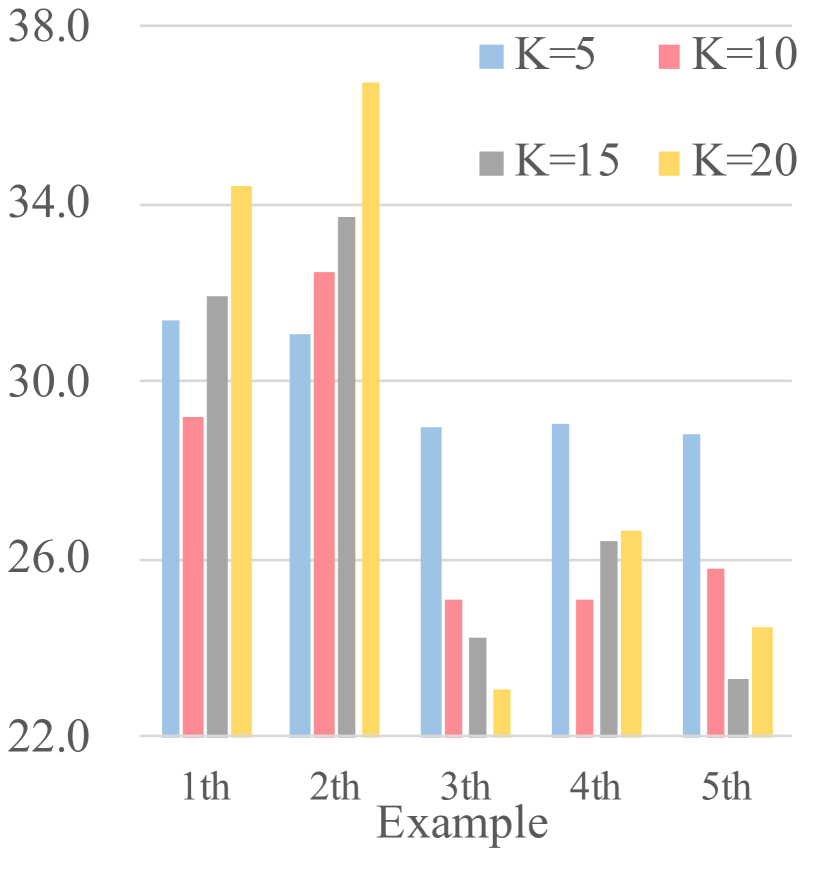
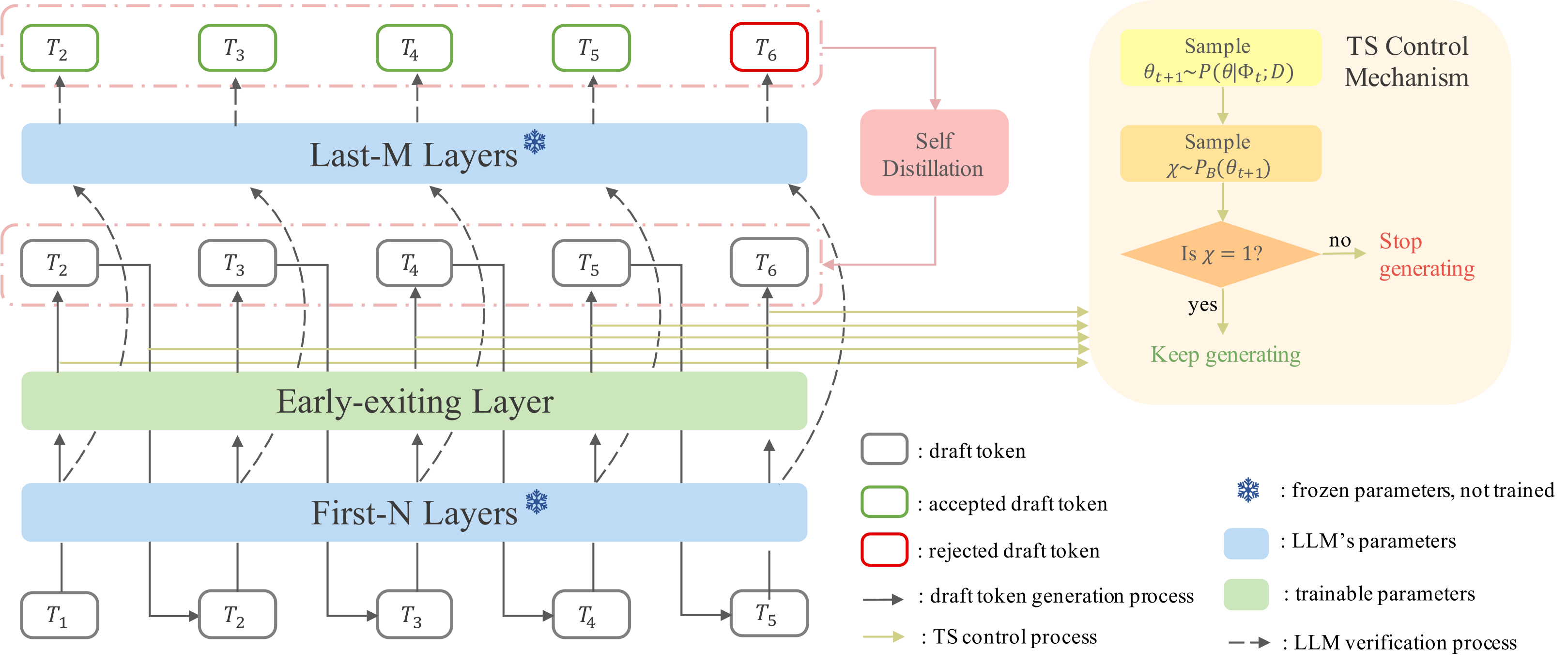
📊 实验亮点
实验结果表明,EESD方法在13B和70B模型上均能显著加速token解码速度,优于现有的推测解码方法。具体性能数据未知,但摘要强调了其加速效果明显。
🎯 应用场景
该研究成果可广泛应用于需要快速LLM推理的场景,例如实时对话系统、在线文本生成、快速机器翻译等。通过降低LLM的推理成本,可以促进LLM在资源受限设备上的部署,并加速LLM在各个领域的应用。
📄 摘要(原文)
The recent advancements in large language models (LLMs) have been extraordinary, yet the escalating inference costs associated with them present challenges in real-world applications. To address these challenges, we propose a novel approach called Early-exiting Speculative Decoding (EESD) with lossless acceleration. Specifically, EESD utilizes a segment of the LLM to generate draft tokens, incorporating Early-exiting structures after the first N layers. To enhance the quality of draft tokens, a self-distillation method is integrated. This early-exiting design not only reduces deployment and training costs but also significantly accelerates the token generation speed. Moreover, we introduce a novel sampling mechanism that leverages Thompson Sampling to regulate the generation processes, automatically determining the quantity of draft tokens in each round. The original LLM is then employed to validate these draft tokens through a single forward pass, and thus guarantees that the final output text maintains a distribution consistent with vanilla auto-regressive decoding. The experimental results on both 13B and 70B models demonstrate that our approach decodes tokens at a markedly accelerated rate compared to prior methods, showing the effectiveness of our approach.