Lean Workbook: A large-scale Lean problem set formalized from natural language math problems
作者: Huaiyuan Ying, Zijian Wu, Yihan Geng, Zheng Yuan, Dahua Lin, Kai Chen
分类: cs.CL
发布日期: 2024-06-06 (更新: 2025-06-18)
🔗 代码/项目: GITHUB | HUGGINGFACE
💡 一句话要点
提出Lean Workbook,用于解决形式化语言数学定理证明中训练数据稀缺问题
🎯 匹配领域: 支柱五:交互与反应 (Interaction & Reaction) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 形式化语言 数学定理证明 大型语言模型 合成数据 数据增强
📋 核心要点
- 现有大型语言模型在形式化语言数学定理证明方面能力不足,主要瓶颈在于缺乏高质量的训练数据。
- 论文提出一种迭代式的合成数据生成和过滤pipeline,用于将自然语言数学问题与Lean 4形式化语句相互翻译。
- 实验结果表明,该合成数据pipeline能够有效提升大型语言模型在理解和翻译复杂数学问题及证明方面的性能。
📝 摘要(中文)
大型语言模型在各种自然语言处理任务中表现出了令人印象深刻的能力,尤其是在解决数学问题方面。然而,大型语言模型并不擅长使用像Lean这样的形式化语言进行数学定理证明。该领域的一个重大挑战是这些形式化语言中可用的训练数据稀缺。为了解决这个问题,我们提出了一种新颖的pipeline,它迭代地生成和过滤合成数据,以将自然语言数学问题翻译成Lean 4语句,反之亦然。我们的结果表明,合成数据pipeline可以提供有用的训练数据,并提高LLM在翻译和理解复杂的数学问题和证明方面的性能。我们最终的数据集包含大约57K个形式-非形式问题对,以及从数学竞赛论坛搜索到的证明和21个新的IMO问题。我们在https://github.com/InternLM/InternLM-Math开源了我们的代码,并在https://huggingface.co/datasets/InternLM/Lean-Workbook开源了我们的数据。
🔬 方法详解
问题定义:现有的大型语言模型在解决自然语言数学问题方面取得了显著进展,但在使用形式化语言(如Lean)进行数学定理证明时表现不佳。主要原因是缺乏足够规模且高质量的训练数据,这限制了模型学习和掌握形式化推理能力。
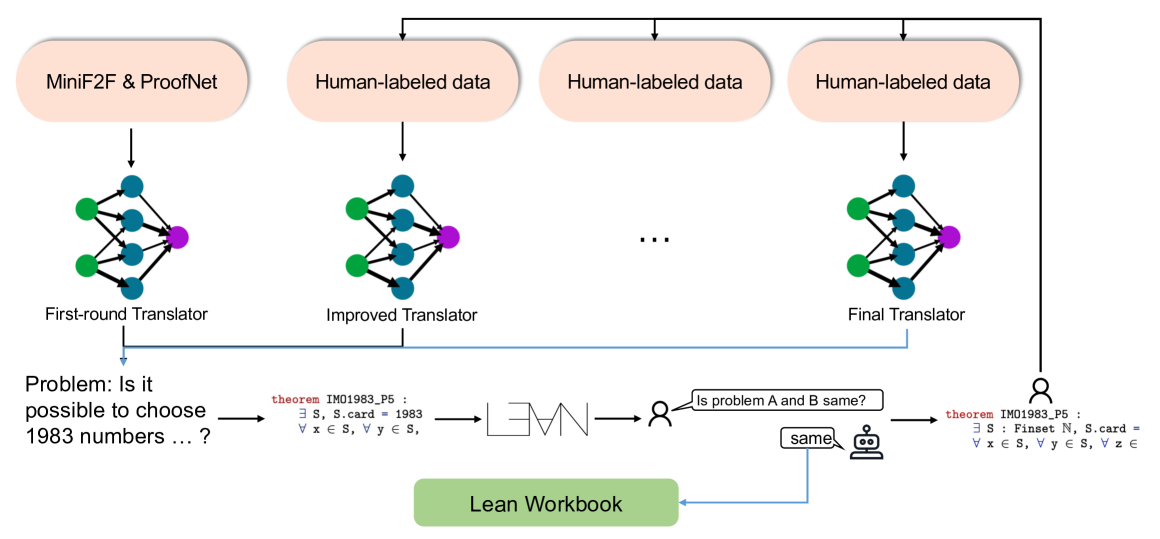
核心思路:论文的核心思路是通过合成数据来缓解训练数据稀缺的问题。具体而言,设计一个pipeline,能够自动地将自然语言描述的数学问题转化为Lean 4形式化语句,反之亦然。通过迭代生成和过滤合成数据,可以构建一个大规模的、包含形式化和非形式化问题对的数据集。
技术框架:该pipeline包含两个主要阶段:数据生成和数据过滤。在数据生成阶段,利用大型语言模型将自然语言数学问题翻译成Lean 4语句,或者将Lean 4语句翻译成自然语言。在数据过滤阶段,使用一系列规则和模型来评估生成数据的质量,并去除低质量的数据。整个过程迭代进行,不断扩充和优化数据集。
关键创新:该方法的主要创新在于提出了一种有效的合成数据生成和过滤pipeline,能够自动构建大规模的、包含形式化和非形式化数学问题对的数据集。这种方法避免了人工标注的成本和时间,并且可以灵活地扩展到不同的数学领域和形式化语言。
关键设计:数据生成阶段使用了大型语言模型,并针对数学问题的特点进行了微调。数据过滤阶段使用了多种规则和模型,例如语法检查器、语义相似度模型等,以确保生成数据的质量。此外,论文还设计了一种迭代式的训练策略,逐步提高模型的翻译和推理能力。
🖼️ 关键图片

📊 实验亮点
论文构建了一个包含约57K个形式-非形式问题对的数据集,并开源了代码和数据。实验结果表明,使用该数据集训练的大型语言模型在翻译和理解复杂数学问题和证明方面取得了显著的性能提升。此外,该数据集还包含了从数学竞赛论坛搜索到的证明和21个新的IMO问题,为相关研究提供了宝贵的资源。
🎯 应用场景
该研究成果可应用于自动化定理证明、数学教育、形式化验证等领域。通过提供高质量的训练数据,可以提升大型语言模型在形式化推理方面的能力,从而实现更智能的数学问题求解和定理证明系统。此外,该方法还可以推广到其他形式化语言和领域,促进人工智能在科学研究中的应用。
📄 摘要(原文)
Large language models have demonstrated impressive capabilities across various natural language processing tasks, especially in solving mathematical problems. However, large language models are not good at math theorem proving using formal languages like Lean. A significant challenge in this area is the scarcity of training data available in these formal languages. To address this issue, we propose a novel pipeline that iteratively generates and filters synthetic data to translate natural language mathematical problems into Lean 4 statements, and vice versa. Our results indicate that the synthetic data pipeline can provide useful training data and improve the performance of LLMs in translating and understanding complex mathematical problems and proofs. Our final dataset contains about 57K formal-informal question pairs along with searched proof from the math contest forum and 21 new IMO questions. We open-source our code at https://github.com/InternLM/InternLM-Math and our data at https://huggingface.co/datasets/InternLM/Lean-Workbook.