Assessing the Emergent Symbolic Reasoning Abilities of Llama Large Language Models
作者: Flavio Petruzzellis, Alberto Testolin, Alessandro Sperduti
分类: cs.CL, cs.AI, cs.LG, cs.NE
发布日期: 2024-06-05
备注: Accepted at 33rd International Conference on Artificial Neural Networks (ICANN24)
💡 一句话要点
评估Llama大型语言模型在符号推理方面的涌现能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 符号推理 数学推理 Llama 2 模型评估
📋 核心要点
- 大型语言模型在数学推理等任务中展现出涌现能力,但对其能力边界和影响因素尚需深入研究。
- 本文通过系统评估Llama 2系列模型在不同难度数学公式上的表现,分析模型规模和微调对性能的影响。
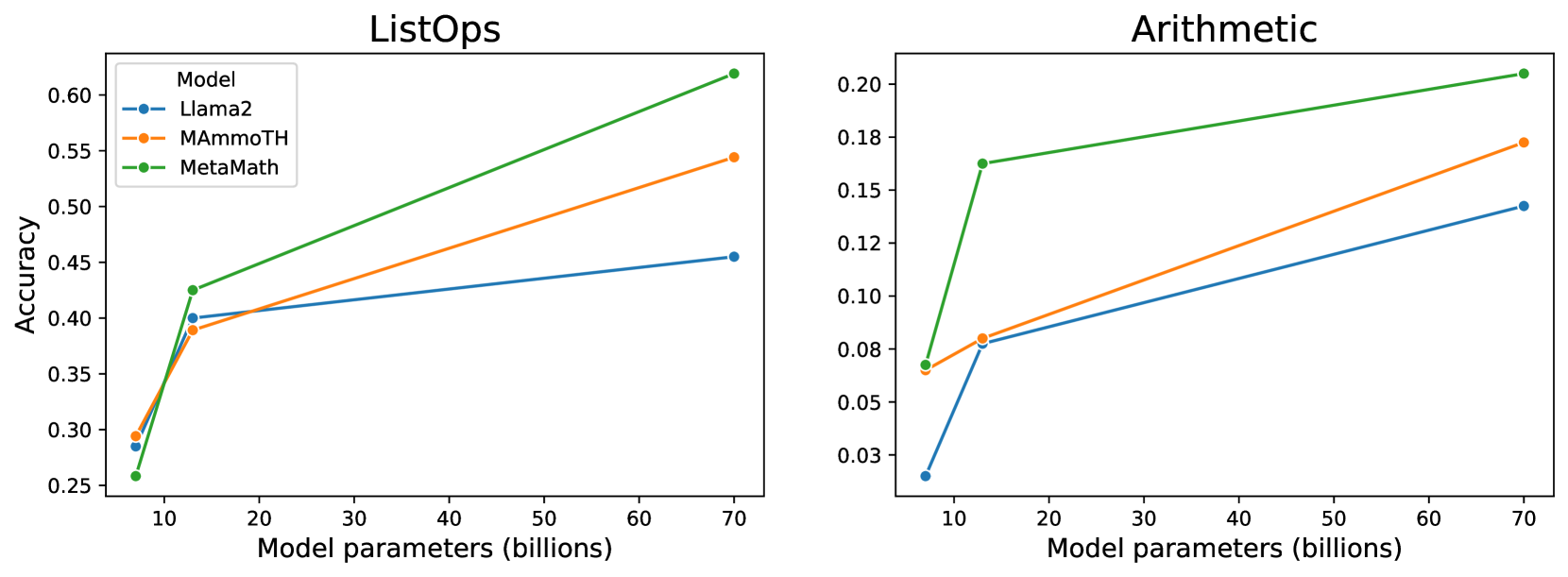
- 实验结果表明,增大模型规模和针对数学问题进行微调能显著提升性能,但复杂公式仍具挑战。
📝 摘要(中文)
大型语言模型(LLMs)在广泛的任务中表现出令人印象深刻的性能,即使它们通常仅以流畅地与用户聊天为目标进行训练。LLMs在数学推理基准测试中展现出涌现能力,这些能力可以通过适当的提示方法来激发。本文系统地研究了流行的开源LLMs在不同符号推理任务中的能力和局限性。我们评估了Llama 2系列的三个模型在两个需要解决不同难度数学公式的数据集上的表现。我们测试了一个通用LLM(Llama 2 Chat)以及Llama 2的两个微调版本(MAmmoTH和MetaMath),它们专门用于解决数学问题。我们观察到,增加模型规模和在相关任务上对其进行微调都会带来显著的性能提升。此外,使用细粒度的评估指标,我们发现这种性能提升主要体现在复杂度较低的数学公式上,但即使对于最大的微调模型来说,这些公式仍然具有挑战性。
🔬 方法详解
问题定义:论文旨在评估和分析大型语言模型(LLMs)在符号推理,特别是数学公式求解方面的能力。现有方法缺乏对开源LLM在不同难度数学问题上的系统性评估,难以了解模型的能力边界和影响因素。
核心思路:论文的核心思路是通过设计一系列符号推理任务,并选择不同规模和经过特定微调的Llama 2模型进行评估,从而量化模型在解决数学问题方面的能力,并分析模型规模和微调策略对性能的影响。
技术框架:论文的整体框架包括:1) 选择Llama 2系列的三个模型(Llama 2 Chat, MAmmoTH, MetaMath);2) 选择两个包含不同难度数学公式的数据集;3) 设计实验方案,评估模型在不同难度公式上的求解能力;4) 使用细粒度的评估指标分析模型性能,并探讨模型规模和微调的影响。
关键创新:论文的关键创新在于对开源LLM在符号推理任务上的系统性评估,并细致分析了模型规模和微调策略对性能的影响。通过细粒度的评估指标,揭示了模型在不同难度公式上的表现差异,为后续研究提供了参考。
关键设计:论文的关键设计包括:1) 选择具有代表性的Llama 2系列模型,涵盖通用模型和数学专用模型;2) 选择包含不同难度数学公式的数据集,以评估模型在不同复杂度问题上的表现;3) 使用准确率等指标评估模型性能,并进行统计分析,以量化模型规模和微调的影响。
🖼️ 关键图片


📊 实验亮点
实验结果表明,增大模型规模和针对数学问题进行微调能显著提升性能。例如,经过数学微调的模型在低复杂度公式上的准确率明显高于通用模型。然而,即使是最大的微调模型,在高复杂度公式上的表现仍然有限,表明LLM在复杂符号推理方面仍有提升空间。
🎯 应用场景
该研究成果可应用于提升LLM在数学、科学计算等领域的应用能力。通过了解模型在符号推理方面的优势和局限性,可以指导模型训练和微调,使其更好地解决实际问题,例如自动化公式推导、科学数据分析等。
📄 摘要(原文)
Large Language Models (LLMs) achieve impressive performance in a wide range of tasks, even if they are often trained with the only objective of chatting fluently with users. Among other skills, LLMs show emergent abilities in mathematical reasoning benchmarks, which can be elicited with appropriate prompting methods. In this work, we systematically investigate the capabilities and limitations of popular open-source LLMs on different symbolic reasoning tasks. We evaluate three models of the Llama 2 family on two datasets that require solving mathematical formulas of varying degrees of difficulty. We test a generalist LLM (Llama 2 Chat) as well as two fine-tuned versions of Llama 2 (MAmmoTH and MetaMath) specifically designed to tackle mathematical problems. We observe that both increasing the scale of the model and fine-tuning it on relevant tasks lead to significant performance gains. Furthermore, using fine-grained evaluation measures, we find that such performance gains are mostly observed with mathematical formulas of low complexity, which nevertheless often remain challenging even for the largest fine-tuned models.