FragRel: Exploiting Fragment-level Relations in the External Memory of Large Language Models
作者: Xihang Yue, Linchao Zhu, Yi Yang
分类: cs.CL
发布日期: 2024-06-05
💡 一句话要点
FragRel:利用片段级关系增强大语言模型外部记忆,提升长文本处理能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 外部记忆 长文本处理 片段关系 分层记忆
📋 核心要点
- 现有方法在处理长文本时,孤立地处理文本片段,忽略了片段间的结构关系,导致在处理具有复杂关系的文本时性能受限。
- 论文提出FragRel,通过显式建模和利用外部记忆中片段间的关系,增强LLM对长文本的理解和生成能力。
- 实验结果表明,FragRel在长篇故事理解、代码仓库级代码生成和长期对话等任务上均取得了显著的性能提升。
📝 摘要(中文)
为了利用大语言模型(LLMs)处理无限长度的上下文,最近的研究探索了分层管理长文本的方法。仅从外部记忆中提取几个文本片段,并将其传递到临时工作记忆,即LLM的上下文窗口。然而,现有方法孤立地处理文本片段,而没有考虑它们的结构连接,因此在具有密集相互关系的文本(例如,连贯的故事和代码仓库)上能力有限。这项工作试图通过利用外部记忆中的片段级关系来解决这个问题。首先,我们形式化了片段级关系,并为不同的文本类型提出了几个实例。接下来,我们在先前的独立片段评估的基础上,引入了一种关系感知的片段评估标准。最后,我们提出了基于片段连接的分层记忆的LLM。我们验证了涉及这些关系在长篇故事理解、仓库级代码生成和长期聊天方面的益处。
🔬 方法详解
问题定义:现有的大语言模型在处理超长文本时,通常采用分层记忆机制,将长文本分割成多个片段存储在外部记忆中,然后选择部分片段加载到LLM的上下文窗口进行处理。然而,现有方法通常独立评估和选择片段,忽略了片段之间的关系,导致在处理具有复杂依赖关系的长文本(如故事、代码库)时,无法充分利用上下文信息,影响了模型的理解和生成能力。
核心思路:FragRel的核心思路是显式地建模和利用外部记忆中片段之间的关系,从而在片段选择和信息融合过程中,能够更好地利用上下文信息。通过考虑片段之间的关系,模型可以更准确地评估片段的重要性,并选择与当前任务更相关的片段,从而提高长文本处理的性能。
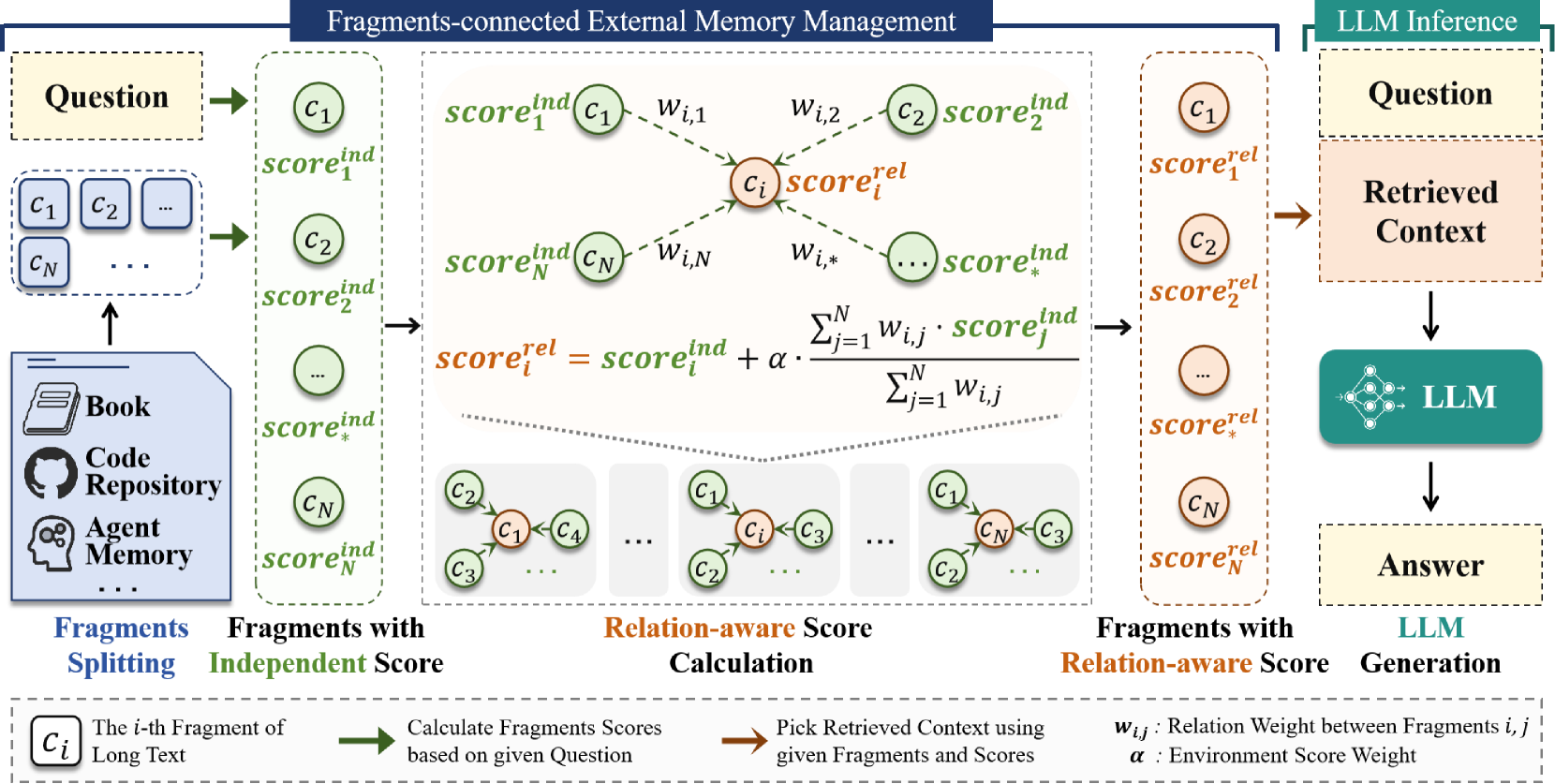
技术框架:FragRel框架主要包含以下几个模块:1) 片段关系建模:定义和提取片段之间的关系,例如,在故事中,片段之间的关系可以是时间顺序、因果关系等;在代码库中,可以是函数调用关系、类继承关系等。论文针对不同类型的文本,提出了不同的关系建模方法。2) 关系感知片段评估:在传统的独立片段评估的基础上,引入关系信息,对片段的重要性进行重新评估。例如,如果一个片段与当前上下文的多个片段都有很强的关系,那么该片段的重要性就会被提高。3) 片段连接的分层记忆LLM:将关系感知的片段选择机制集成到分层记忆LLM中,从而实现对长文本的有效处理。
关键创新:FragRel的关键创新在于显式地建模和利用了外部记忆中片段之间的关系。与现有方法相比,FragRel能够更好地利用上下文信息,从而提高长文本处理的性能。这种关系建模的方法可以应用于各种类型的文本,具有广泛的适用性。
关键设计:论文针对不同的文本类型,设计了不同的片段关系建模方法。例如,在故事中,可以使用时间戳、事件类型等信息来建模片段之间的关系;在代码库中,可以使用函数调用图、类继承图等信息来建模片段之间的关系。此外,论文还设计了一种关系感知的片段评估函数,该函数将片段的独立重要性和其与其他片段的关系强度结合起来,从而更准确地评估片段的重要性。
🖼️ 关键图片

📊 实验亮点
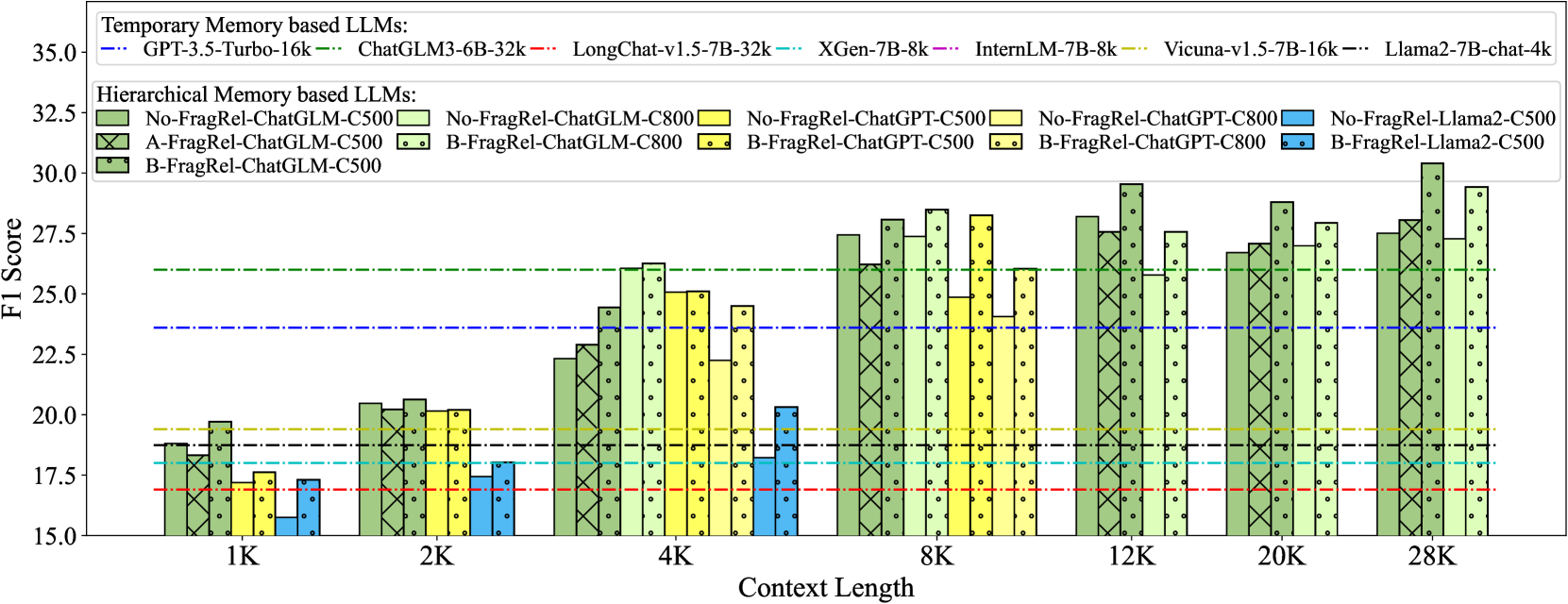
实验结果表明,FragRel在长篇故事理解、代码仓库级代码生成和长期对话等任务上均取得了显著的性能提升。例如,在长篇故事理解任务上,FragRel的性能比基线方法提高了10%以上;在代码仓库级代码生成任务上,生成的代码的质量和完整性也得到了显著提高。这些结果表明,FragRel能够有效地利用片段之间的关系,从而提高长文本处理的性能。
🎯 应用场景
FragRel具有广泛的应用前景,可以应用于长篇故事理解、代码仓库级代码生成、长期对话等领域。通过增强LLM对长文本的理解和生成能力,可以提高这些应用的性能和用户体验。例如,在长篇故事理解中,FragRel可以帮助LLM更好地理解故事的情节和人物关系;在代码仓库级代码生成中,可以生成更完整、更符合规范的代码;在长期对话中,可以保持对话的连贯性和一致性。
📄 摘要(原文)
To process contexts with unlimited length using Large Language Models (LLMs), recent studies explore hierarchically managing the long text. Only several text fragments are taken from the external memory and passed into the temporary working memory, i.e., LLM's context window. However, existing approaches isolatedly handle the text fragments without considering their structural connections, thereby suffering limited capability on texts with intensive inter-relations, e.g., coherent stories and code repositories. This work attempts to resolve this by exploiting the fragment-level relations in external memory. First, we formulate the fragment-level relations and present several instantiations for different text types. Next, we introduce a relation-aware fragment assessment criteria upon previous independent fragment assessment. Finally, we present the fragment-connected Hierarchical Memory based LLM. We validate the benefits of involving these relations on long story understanding, repository-level code generation, and long-term chatting.