Adversarial Moment-Matching Distillation of Large Language Models
作者: Chen Jia
分类: cs.CL, cs.LG
发布日期: 2024-06-05
💡 一句话要点
提出对抗矩匹配蒸馏方法,提升大语言模型知识蒸馏效果并达到SOTA
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 知识蒸馏 大型语言模型 模仿学习 对抗训练 行动价值矩
📋 核心要点
- 现有大语言模型知识蒸馏方法主要依赖于最小化师生模型概率预测的分布距离,忽略了模仿学习的潜力。
- 该论文提出了一种基于模仿学习的知识蒸馏方法,通过对抗训练匹配师生模型的行动价值矩,缩小模仿差距。
- 实验结果表明,该方法在指令跟随和特定任务上均表现出色,达到了新的state-of-the-art性能。
📝 摘要(中文)
知识蒸馏(KD)已被证明在用更大的教师模型指导学生模型方面非常有效,并在提高大型语言模型(LLM)的计算和内存效率方面实现了实际效益。LLM 最先进的 KD 方法主要依赖于最小化教师和学生概率预测之间的显式分布距离。我们探索了一种模仿学习策略来进行 LLM 的 KD,而不是优化这些强制性的行为克隆目标。特别地,我们通过匹配教师行为的行动价值矩来最小化模仿差距,从在线和离线策略的角度来看。为了实现这个行动价值矩匹配目标,我们提出了一种对抗训练算法,以联合估计矩匹配距离并优化学生策略以最小化它。来自与任务无关的指令跟随实验和特定于任务的实验的结果证明了我们方法的有效性,并实现了新的最先进的性能。
🔬 方法详解
问题定义:现有大语言模型知识蒸馏方法主要采用行为克隆,即最小化学生模型和教师模型输出概率分布之间的距离。这种方法忽略了教师模型的决策过程,可能导致学生模型难以学习到教师模型的深层策略。此外,直接优化概率分布距离可能不是最优的模仿学习策略。
核心思路:该论文的核心思路是利用模仿学习,通过匹配教师模型的行动价值矩来指导学生模型的学习。行动价值矩能够反映教师模型在特定状态下采取特定行动的长期回报,从而更好地捕捉教师模型的策略。通过最小化师生模型行动价值矩之间的差异,可以有效地缩小模仿差距,提升学生模型的性能。
技术框架:该方法采用对抗训练框架。包含两个主要模块:学生模型(Student Policy)和一个判别器(Discriminator)。学生模型的目标是生成与教师模型相似的行动价值矩。判别器的目标是区分学生模型和教师模型的行动价值矩。通过对抗训练,学生模型不断优化自身策略,使得其行动价值矩越来越接近教师模型,从而实现知识蒸馏。
关键创新:该方法的关键创新在于将对抗训练引入到大语言模型的知识蒸馏中,并利用行动价值矩作为模仿学习的目标。与传统的行为克隆方法相比,该方法能够更好地捕捉教师模型的策略,从而提升学生模型的性能。此外,对抗训练能够有效地解决模仿学习中的分布偏移问题。
关键设计:该方法使用对抗损失函数来训练学生模型和判别器。对抗损失函数基于Wasserstein距离,能够更好地衡量两个分布之间的差异。学生模型的训练目标是最小化对抗损失,判别器的训练目标是最大化对抗损失。此外,该方法还采用了梯度惩罚技术,以提高对抗训练的稳定性。具体的网络结构和参数设置未在摘要中提及,属于未知信息。
🖼️ 关键图片


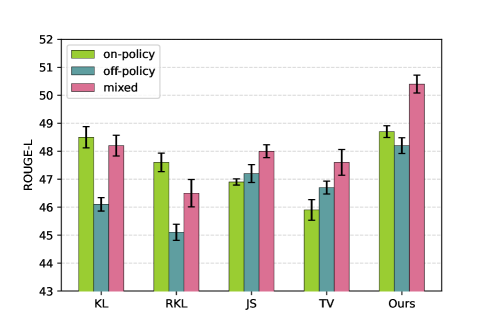
📊 实验亮点
该方法在任务无关的指令跟随实验和特定任务实验中均取得了显著的性能提升,达到了新的state-of-the-art水平。具体的性能数据和对比基线未在摘要中给出,属于未知信息。但结论表明,该方法在知识蒸馏方面具有很强的竞争力。
🎯 应用场景
该研究成果可广泛应用于大语言模型的压缩和加速,例如将大型预训练模型蒸馏到小型模型,从而降低计算成本和内存占用,使其能够在资源受限的设备上运行。这对于移动设备、嵌入式系统等应用场景具有重要意义。此外,该方法还可以用于提升模型的泛化能力和鲁棒性。
📄 摘要(原文)
Knowledge distillation (KD) has been shown to be highly effective in guiding a student model with a larger teacher model and achieving practical benefits in improving the computational and memory efficiency for large language models (LLMs). State-of-the-art KD methods for LLMs mostly rely on minimizing explicit distribution distance between teacher and student probability predictions. Instead of optimizing these mandatory behaviour cloning objectives, we explore an imitation learning strategy for KD of LLMs. In particular, we minimize the imitation gap by matching the action-value moments of the teacher's behavior from both on- and off-policy perspectives. To achieve this action-value moment-matching goal, we propose an adversarial training algorithm to jointly estimate the moment-matching distance and optimize the student policy to minimize it. Results from both task-agnostic instruction-following experiments and task-specific experiments demonstrate the effectiveness of our method and achieve new state-of-the-art performance.