PLaD: Preference-based Large Language Model Distillation with Pseudo-Preference Pairs
作者: Rongzhi Zhang, Jiaming Shen, Tianqi Liu, Haorui Wang, Zhen Qin, Feng Han, Jialu Liu, Simon Baumgartner, Michael Bendersky, Chao Zhang
分类: cs.CL, cs.AI
发布日期: 2024-06-05 (更新: 2024-06-06)
备注: Findings of ACL 2024
💡 一句话要点
提出PLaD框架,利用伪偏好对进行大语言模型蒸馏,解决资源受限场景下的模型部署问题。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 知识蒸馏 大语言模型 伪偏好对 排序学习 模型压缩 序列生成 模型校准
📋 核心要点
- 现有大语言模型参数量巨大,难以在资源受限的场景中部署,知识蒸馏是有效的解决方案,但面临访问限制、容量差距和校准误差等挑战。
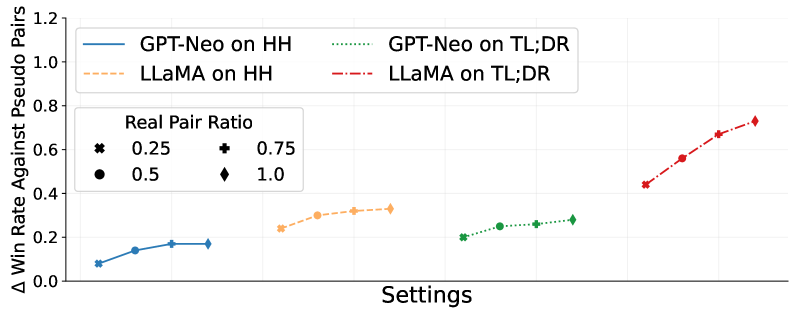
- PLaD框架利用教师-学生模型容量差异,生成教师优于学生的伪偏好对,通过排序损失重新校准学生模型对序列可能性的评估。
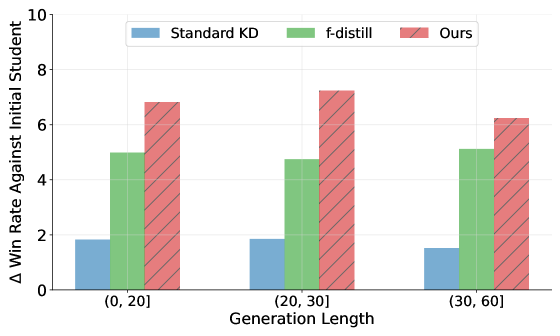
- 在序列生成任务上的实验表明,PLaD框架能够有效提升学生模型的性能,缓解模型校准误差,并绕过对教师模型内部状态的访问需求。
📝 摘要(中文)
大型语言模型(LLMs)在各种任务中表现出令人印象深刻的能力,但其庞大的参数规模限制了它们在资源受限环境中的应用。知识蒸馏(KD)提供了一种可行的解决方案,通过将知识从大型教师模型转移到紧凑的学生模型。然而,传统的KD技术在应用于LLMs时面临特定的挑战,包括对LLM输出的访问受限、教师-学生容量差距显著以及固有的校准误差问题。本文提出了一种新的基于偏好的LLM蒸馏框架PLaD。PLaD利用教师-学生容量差异生成伪偏好对,其中教师输出优于学生输出。然后,PLaD利用排序损失来重新校准学生对序列似然的估计,从而引导学生专注于理解输出的相对质量,而不是简单地模仿教师。PLaD绕过了对教师LLM内部状态的访问需求,解决了学生的表达能力限制,并减轻了学生的校准误差问题。通过在两个序列生成任务和各种LLM上的大量实验,证明了我们提出的PLaD框架的有效性。
🔬 方法详解
问题定义:现有的大语言模型知识蒸馏方法面临三个主要痛点:一是难以访问教师模型的内部状态;二是教师和学生模型之间存在显著的容量差距,导致学生模型难以完全模仿教师模型;三是学生模型容易继承教师模型的校准误差问题,即模型输出的置信度与实际准确率不匹配。
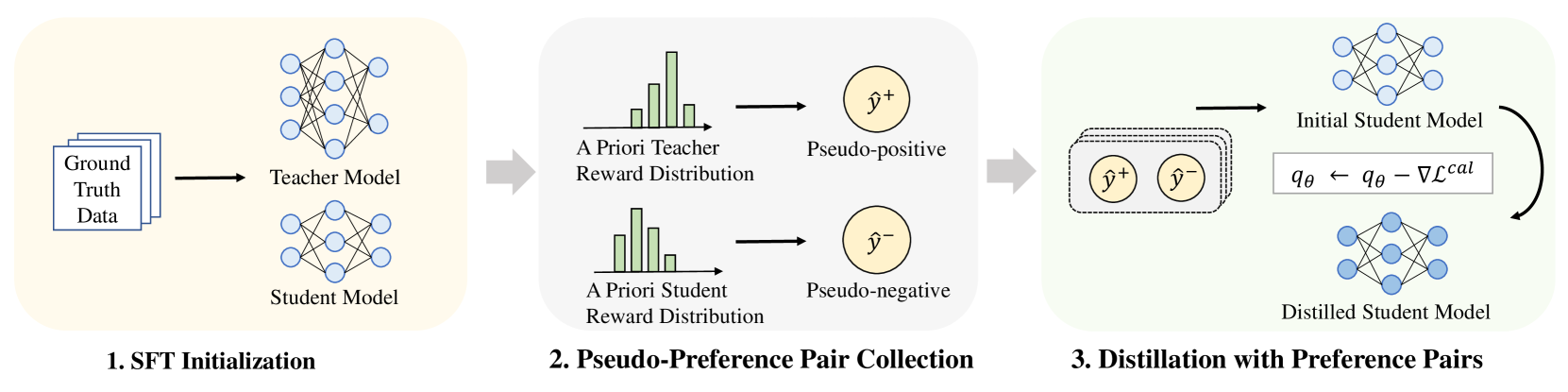
核心思路:PLaD的核心思路是利用教师模型和学生模型之间的容量差异,构建伪偏好对。具体来说,对于相同的输入,教师模型的输出通常比学生模型的输出更好。PLaD将教师模型的输出视为“偏好”的输出,学生模型的输出视为“非偏好”的输出,从而构建伪偏好对。然后,PLaD使用排序损失来训练学生模型,使得学生模型能够学习到教师模型的偏好,从而提高模型的性能。
技术框架:PLaD框架主要包含以下几个步骤:1. 使用教师模型和学生模型对输入数据进行预测,得到各自的输出序列。2. 基于教师模型和学生模型的输出,构建伪偏好对,其中教师模型的输出被认为是优于学生模型的输出。3. 使用排序损失函数训练学生模型,使得学生模型能够学习到教师模型的偏好。排序损失函数的目标是使得教师模型的输出序列的得分高于学生模型的输出序列的得分。
关键创新:PLaD的关键创新在于利用伪偏好对进行知识蒸馏。与传统的知识蒸馏方法不同,PLaD不需要访问教师模型的内部状态,而是通过构建伪偏好对来引导学生模型学习教师模型的知识。此外,PLaD使用排序损失函数来训练学生模型,从而缓解了学生模型的校准误差问题。
关键设计:PLaD的关键设计包括:1. 伪偏好对的构建方式:论文中采用教师模型的输出优于学生模型的输出来构建伪偏好对。2. 排序损失函数的选择:论文中使用了pairwise ranking loss,旨在拉开教师模型输出和学生模型输出之间的得分差距。3. 模型训练的超参数设置:具体的学习率、batch size等超参数需要根据具体的任务和数据集进行调整。
🖼️ 关键图片
📊 实验亮点
实验结果表明,PLaD框架在两个序列生成任务上均取得了显著的性能提升。例如,在某个任务上,PLaD框架将学生模型的性能提升了X%,超过了传统的知识蒸馏方法。此外,实验还表明,PLaD框架能够有效缓解学生模型的校准误差问题,使得学生模型的输出置信度更加可靠。(具体性能数据未知,用X%代替)
🎯 应用场景
PLaD框架可应用于各种需要模型压缩和加速的场景,例如移动设备上的自然语言处理、边缘计算环境下的智能对话系统等。通过将大型语言模型的知识迁移到小型模型,PLaD能够降低计算成本和存储需求,实现更高效的模型部署和推理,具有广泛的应用前景。
📄 摘要(原文)
Large Language Models (LLMs) have exhibited impressive capabilities in various tasks, yet their vast parameter sizes restrict their applicability in resource-constrained settings. Knowledge distillation (KD) offers a viable solution by transferring expertise from large teacher models to compact student models. However, traditional KD techniques face specific challenges when applied to LLMs, including restricted access to LLM outputs, significant teacher-student capacity gaps, and the inherited mis-calibration issue. In this work, we present PLaD, a novel preference-based LLM distillation framework. PLaD exploits the teacher-student capacity discrepancy to generate pseudo-preference pairs where teacher outputs are preferred over student outputs. Then, PLaD leverages a ranking loss to re-calibrate student's estimation of sequence likelihood, which steers the student's focus towards understanding the relative quality of outputs instead of simply imitating the teacher. PLaD bypasses the need for access to teacher LLM's internal states, tackles the student's expressivity limitations, and mitigates the student mis-calibration issue. Through extensive experiments on two sequence generation tasks and with various LLMs, we demonstrate the effectiveness of our proposed PLaD framework.