LLM as a Scorer: The Impact of Output Order on Dialogue Evaluation
作者: Yi-Pei Chen, KuanChao Chu, Hideki Nakayama
分类: cs.CL
发布日期: 2024-06-05
备注: Presented in AAAI 2024 Spring Symposium. The first two authors contributed equally
💡 一句话要点
研究LLM作为评分器时,输出顺序对对话评估的影响
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 对话评估 提示工程 输出顺序 自然语言处理
📋 核心要点
- 现有对话评估方法主观性强,且难以捕捉对话的细微差别,LLM虽有潜力但提示工程仍具挑战。
- 该研究探索了不同提示结构对LLM对话评估的影响,特别是输出指令顺序和解释性原因的包含。
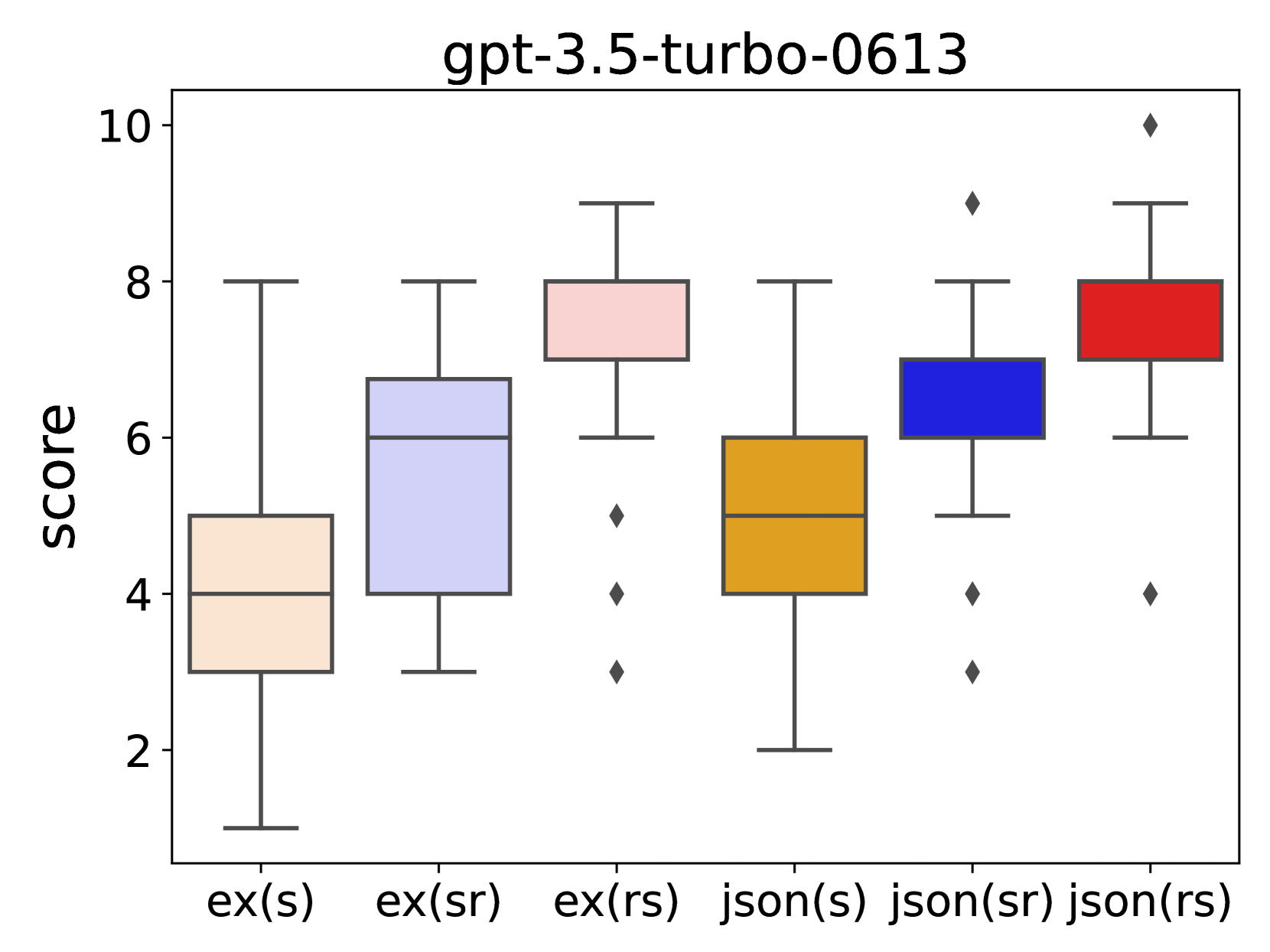
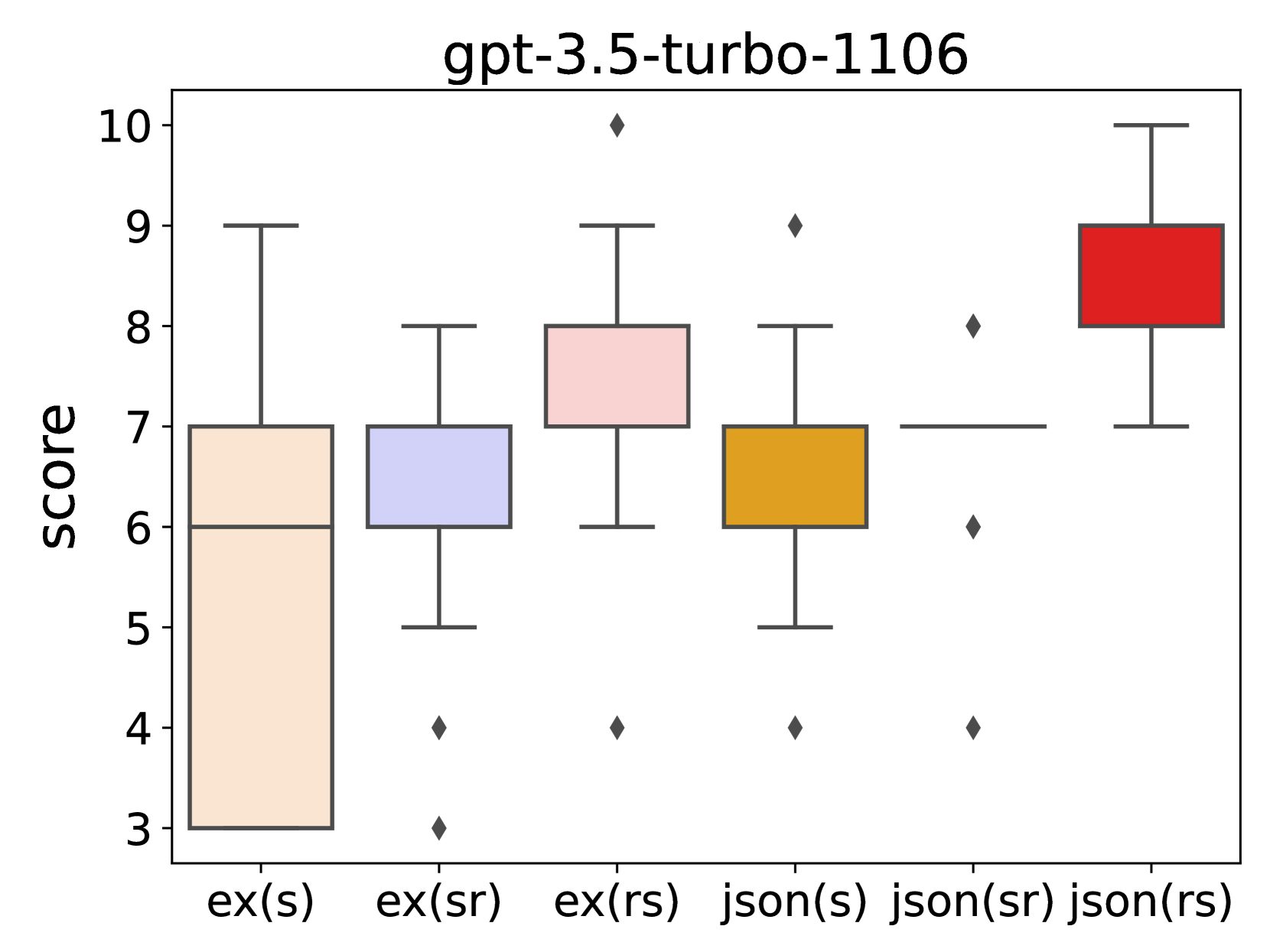
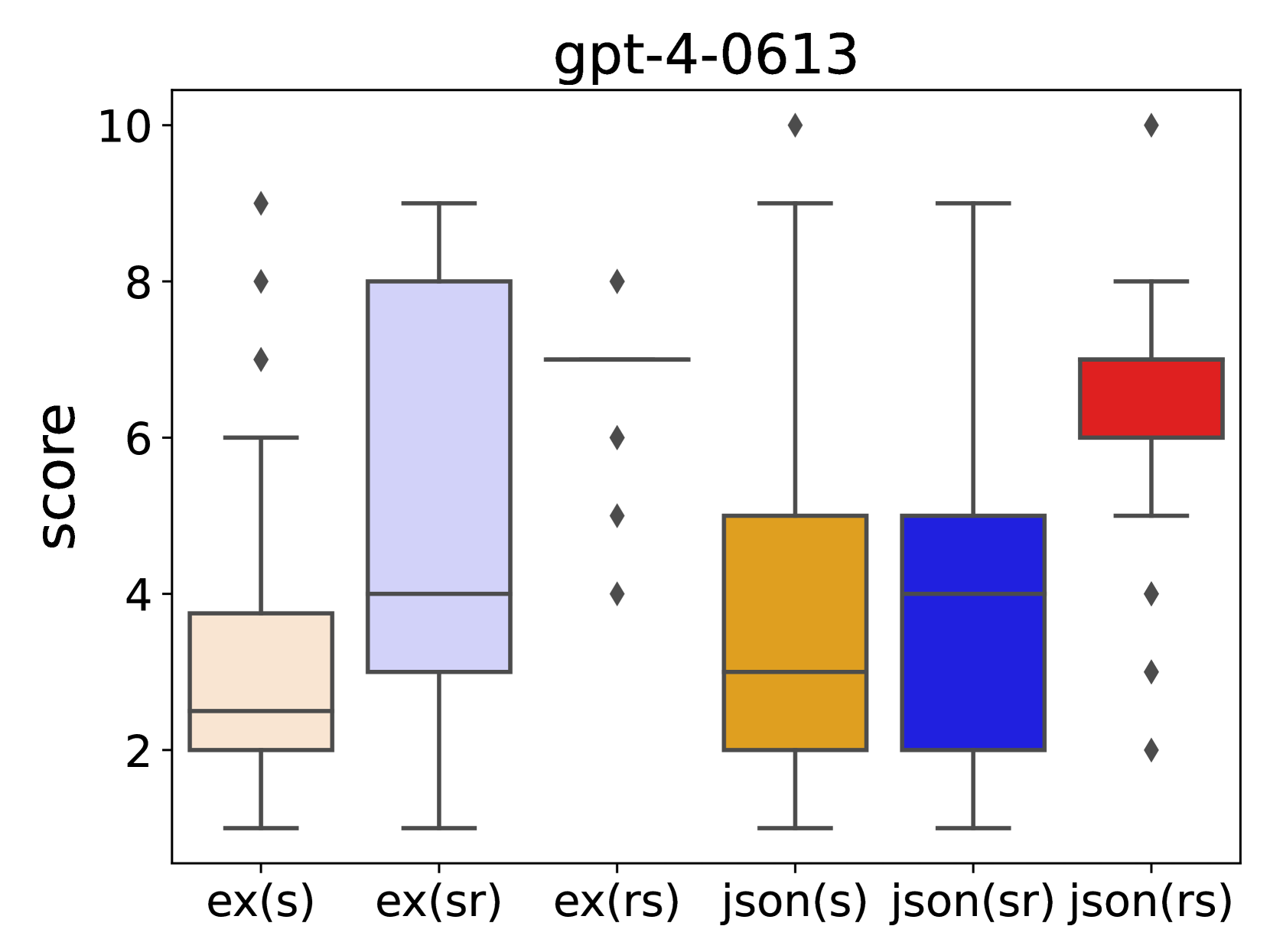
- 实验表明,'原因优先'的提示方法能使LLM进行更全面的评估,显著提升评估的准确性和一致性。
📝 摘要(中文)
本研究探讨了提示设计对使用大型语言模型(LLM)进行对话评估的影响。尽管LLM越来越多地用于对各种输入进行评分,但由于模型敏感性和对话评估的主观性,为对话评估创建有效的提示仍然具有挑战性。我们的研究尝试了不同的提示结构,改变了输出指令的顺序,并包括了解释性原因。我们发现,呈现原因和分数的顺序会显著影响LLM的评分,其中“原因优先”的方法可以产生更全面的评估。这一发现对于提高基于LLM的评估的准确性和一致性至关重要。
🔬 方法详解
问题定义:论文旨在解决如何更有效地利用大型语言模型(LLM)进行对话评估的问题。现有的对话评估方法存在主观性强、难以捕捉对话细微差别等痛点,而直接使用LLM进行评估时,模型对提示语的敏感性以及评估结果的不一致性成为新的挑战。因此,如何设计有效的提示语,以提高LLM对话评估的准确性和可靠性是本研究要解决的核心问题。
核心思路:论文的核心思路是通过改变提示语的结构,特别是输出指令的顺序,来影响LLM的评估行为。研究者假设,先要求LLM给出评估原因,再给出分数,可以促使模型进行更深入的分析和思考,从而产生更全面、更合理的评估结果。这种“原因优先”的方法旨在引导LLM更像人类专家一样进行评估。
技术框架:该研究的技术框架主要包括以下几个步骤:1) 构建包含对话样本和不同提示语的测试数据集;2) 使用LLM(具体模型未明确指出)对每个对话样本进行评估,采用不同的提示语结构;3) 分析LLM的输出结果,比较不同提示语结构下的评估分数和评估理由;4) 通过统计分析和人工评估,评估不同提示语结构对评估准确性和一致性的影响。
关键创新:该研究的关键创新在于发现了输出顺序对LLM对话评估结果的显著影响。以往的研究主要关注提示语的内容和风格,而忽略了输出指令的顺序。本研究表明,通过简单地改变输出顺序,就可以显著提高LLM评估的质量。这种发现为LLM提示工程提供了新的思路。
关键设计:研究的关键设计在于对提示语结构的精细控制。具体来说,研究者设计了多种提示语,这些提示语在内容上基本一致,但输出指令的顺序不同,例如,有的提示语先要求LLM给出评估分数,再给出评估理由,而有的提示语则相反。通过比较这些不同提示语下的评估结果,研究者可以有效地评估输出顺序对LLM评估行为的影响。具体的参数设置、损失函数、网络结构等技术细节未在摘要中提及。
🖼️ 关键图片
📊 实验亮点
研究发现,“原因优先”的提示方法显著提高了LLM对话评估的准确性和一致性。具体性能数据未在摘要中给出,但研究强调了输出顺序对评估结果的显著影响,表明通过优化提示语结构可以有效提升LLM在对话评估任务中的表现。
🎯 应用场景
该研究成果可广泛应用于各种需要自动对话评估的场景,例如聊天机器人开发、在线客服质量监控、对话系统性能测试等。通过优化提示语设计,可以提高LLM对话评估的准确性和效率,降低人工评估的成本,并为对话系统的改进提供更有价值的反馈。
📄 摘要(原文)
This research investigates the effect of prompt design on dialogue evaluation using large language models (LLMs). While LLMs are increasingly used for scoring various inputs, creating effective prompts for dialogue evaluation remains challenging due to model sensitivity and subjectivity in dialogue assessments. Our study experimented with different prompt structures, altering the sequence of output instructions and including explanatory reasons. We found that the order of presenting reasons and scores significantly influences LLMs' scoring, with a "reason-first" approach yielding more comprehensive evaluations. This insight is crucial for enhancing the accuracy and consistency of LLM-based evaluations.