Self-Control of LLM Behaviors by Compressing Suffix Gradient into Prefix Controller
作者: Min Cai, Yuchen Zhang, Shichang Zhang, Fan Yin, Dan Zhang, Difan Zou, Yisong Yue, Ziniu Hu
分类: cs.CL, cs.AI
发布日期: 2024-06-04 (更新: 2024-10-12)
备注: Website: https://llm-self-control.github.io/
💡 一句话要点
SelfControl:通过梯度压缩实现大语言模型行为的无监督自控
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型控制 梯度优化 自监督学习 行为引导 推理时控制
📋 核心要点
- 现有大语言模型缺乏细粒度行为控制,依赖人工标注数据进行微调,成本高昂且难以适应新场景。
- SelfControl利用梯度信息,无需人工标注,通过控制LLM的潜在表示来引导生成过程,实现行为控制。
- 实验表明,SelfControl在解毒、提升真实性、控制情绪和保护隐私等方面显著优于现有方法。
📝 摘要(中文)
本文提出SelfControl,一种推理时模型控制方法,利用梯度来控制大型语言模型(LLM)的行为,无需显式的人工标注。给定一个以自然语言后缀字符串表示的期望行为,SelfControl计算LLM对该后缀的自评估关于其潜在表示的梯度。这些梯度被用于直接控制自回归生成过程,使其朝着期望的行为发展,从而消除了人工监督,实现了精确和透明的控制,并提供了即时适应性。为了进一步提高效率,我们引入了SelfControl_{Prefix},一个紧凑的模块,将从梯度中学习到的表示封装到SelfControl_{Prefix}中,从而实现高效的推理时控制,与原始模型相比没有延迟,并允许同时控制多种行为。实验表明,SelfControl在多个领域都有效,在解毒方面比SOTA提高了8.3%,在提高真实性方面提高了3.1%,在控制情绪方面提高了4%~10%,在隐私保护方面提高了48.2%,即完全消除了隐私泄露问题。此外,我们证明了SelfControl可以用于数据合成和提高推理能力。
🔬 方法详解
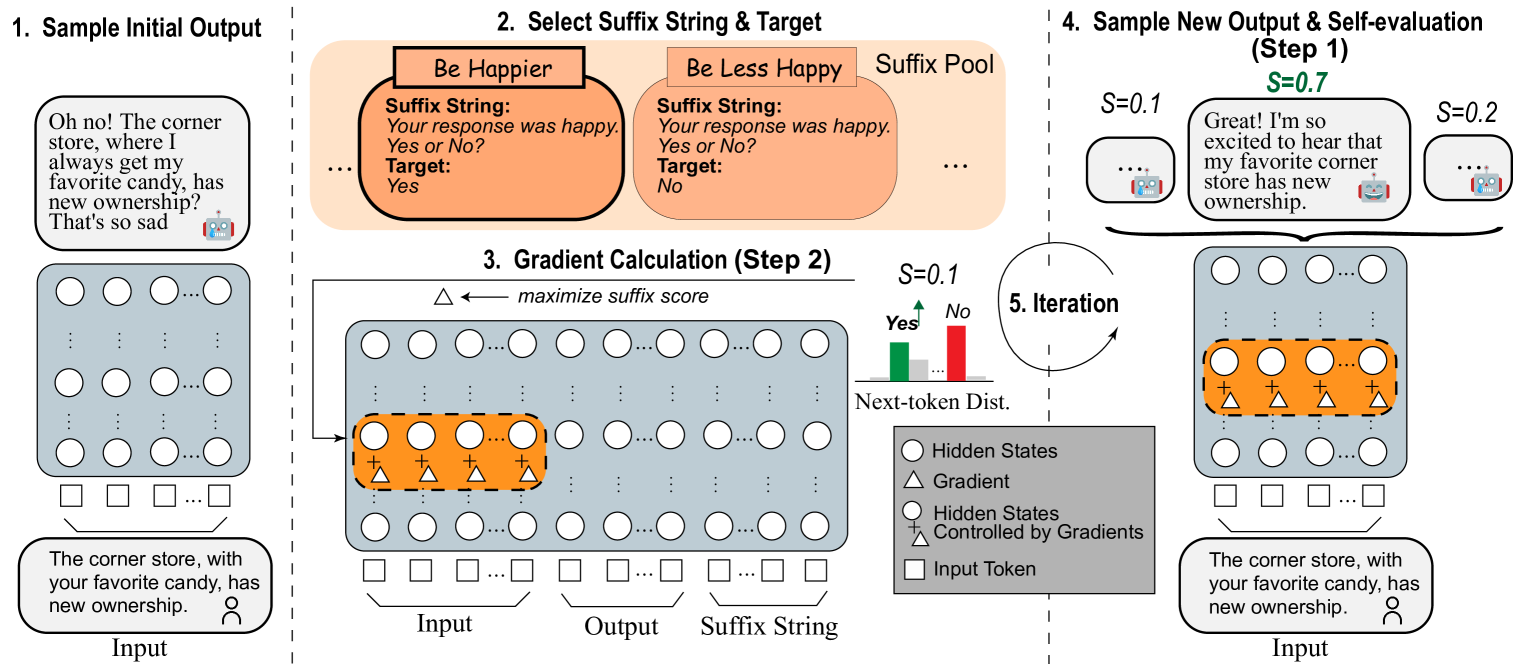
问题定义:现有的大语言模型行为控制方法通常依赖于大量人工标注数据进行微调,这不仅成本高昂,而且难以泛化到新的场景和行为。此外,这些方法往往缺乏透明性和可解释性,难以理解模型行为背后的原因。因此,如何实现一种无需人工标注、精确、透明且可适应的LLM行为控制方法是一个重要的挑战。
核心思路:SelfControl的核心思路是利用LLM自身的能力来评估其生成的文本是否符合期望的行为,并基于此评估结果计算梯度。这些梯度反映了LLM潜在表示对期望行为的影响,因此可以用来指导生成过程,使其朝着期望的行为发展。通过这种方式,SelfControl实现了无需人工标注的自监督行为控制。
技术框架:SelfControl的整体框架包括以下几个步骤:1) 给定输入提示和期望行为的自然语言后缀;2) LLM生成文本;3) LLM对生成的文本进行自评估,判断其是否符合期望行为;4) 计算自评估结果关于LLM潜在表示的梯度;5) 利用梯度调整LLM的生成过程,使其朝着期望的行为发展。为了提高效率,SelfControl还引入了SelfControl_{Prefix}模块,将学习到的梯度信息压缩到一个紧凑的prefix中,从而实现高效的推理时控制。
关键创新:SelfControl最重要的技术创新点在于利用梯度信息实现了无需人工标注的LLM行为控制。与现有方法相比,SelfControl具有以下优势:1) 无需人工标注,降低了成本;2) 控制过程透明可解释;3) 可即时适应新的场景和行为;4) 可以同时控制多种行为。
关键设计:SelfControl的关键设计包括:1) 使用自然语言后缀来表达期望行为,使得控制更加灵活和直观;2) 利用LLM自身的自评估能力来计算梯度,避免了对外部评估器的依赖;3) 引入SelfControl_{Prefix}模块来提高推理效率,减少延迟;4) 使用梯度裁剪和正则化等技术来稳定训练过程。
🖼️ 关键图片


📊 实验亮点
实验结果表明,SelfControl在多个领域都取得了显著的性能提升。例如,在解毒方面,SelfControl比SOTA提高了8.3%;在提高真实性方面,提高了3.1%;在控制情绪方面,提高了4%~10%;在隐私保护方面,完全消除了隐私泄露问题(提升48.2%)。这些结果表明,SelfControl是一种有效且通用的LLM行为控制方法。
🎯 应用场景
SelfControl具有广泛的应用前景,例如:1) 内容生成:可以控制LLM生成符合特定风格、情感或主题的文本;2) 对话系统:可以控制LLM生成安全、礼貌和有帮助的回复;3) 数据增强:可以利用SelfControl生成高质量的训练数据,提高模型的性能;4) 隐私保护:可以防止LLM泄露敏感信息。
📄 摘要(原文)
We propose SelfControl, an inference-time model control method utilizing gradients to control the behavior of large language models (LLMs) without explicit human annotations. Given a desired behavior expressed in a natural language suffix string concatenated to the input prompt, SelfControl computes gradients of the LLM's self-evaluation of the suffix with respect to its latent representations. The gradients are used to directly control the auto-regressive generation process towards desired behaviors, which eliminates human supervision, achieves precise and transparent control, and offers on-the-fly adaptability. To further enhance efficiency, we introduce SelfControl_{Prefix}, a compact module that encapsulates the learned representations from gradients into a SelfControl_{Prefix}, facilitating efficient inference-time control with no latency compared to the original model and allowing control for multiple behaviors simultaneously. Our experiments demonstrate SelfControl's efficacy across multiple domains, where it improves over SOTA for 8.3% in detoxification, 3.1% in truthfulness enhancement, 4%~10% in controlling on emotion tones, and 48.2% in privacy protection, i.e., completely remove privacy leakage issue. Additionally, we demonstrate that SelfControl can be used for data synthesis and to improve reasoning abilities.