TopViewRS: Vision-Language Models as Top-View Spatial Reasoners
作者: Chengzu Li, Caiqi Zhang, Han Zhou, Nigel Collier, Anna Korhonen, Ivan Vulić
分类: cs.CL, cs.CV, cs.LG
发布日期: 2024-06-04
备注: 9 pages, 3 figures, 3 tables (21 pages, 4 figures, 15 tables including references and appendices)
💡 一句话要点
提出TopViewRS数据集,评估视觉-语言模型在鸟瞰视角下的空间推理能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉-语言模型 空间推理 鸟瞰视角 数据集 多模态学习
📋 核心要点
- 现有视觉-语言模型在空间推理能力方面仍有待探索,尤其是在模拟人类地图理解的鸟瞰视角下。
- 论文提出TopViewRS数据集,旨在评估和提升视觉-语言模型在鸟瞰视角下的空间关系理解和推理能力。
- 实验结果表明,现有视觉-语言模型在TopViewRS数据集上的表现与人类水平差距显著,有很大的提升空间。
📝 摘要(中文)
本文研究了大型视觉-语言模型(VLMs)在鸟瞰视角下理解和推理空间关系的能力。鸟瞰视角是人类理解地图和进行定位导航的关键方式。为此,作者构建了TopViewRS数据集,包含11384个多项选择题,使用真实或语义的鸟瞰地图作为视觉输入。该数据集用于评估VLMs在不同复杂度的感知和推理任务中的表现。对10个代表性的开源和闭源VLMs的评估表明,其性能与人类平均水平相比差距超过50%,甚至低于随机基线。尽管思维链推理可以平均提升模型能力5.82%,但VLMs的总体性能仍然有限。研究结果强调了增强模型在鸟瞰空间推理能力方面的迫切需求,并为未来研究VLMs在现实世界多模态任务中达到人类水平的熟练程度奠定了基础。
🔬 方法详解
问题定义:论文旨在解决视觉-语言模型在鸟瞰视角下的空间推理能力不足的问题。现有方法缺乏针对鸟瞰视角的专门评估和训练,导致模型难以理解和推理地图中的空间关系。
核心思路:论文的核心思路是构建一个专门用于评估和训练视觉-语言模型在鸟瞰视角下空间推理能力的数据集TopViewRS。通过设计不同复杂度的感知和推理任务,系统性地评估模型的各项能力。
技术框架:TopViewRS数据集包含真实和语义两种类型的鸟瞰地图,以及基于这些地图生成的多项选择题。题目涵盖四个不同复杂度的任务:识别特定对象、理解对象之间的相对位置、进行空间推理和导航。研究者使用该数据集评估了10个代表性的视觉-语言模型。
关键创新:TopViewRS数据集是该研究的关键创新点。它提供了一个标准化的平台,用于评估和比较不同视觉-语言模型在鸟瞰视角下的空间推理能力。数据集的设计考虑了不同层次的空间推理能力,可以更细粒度地分析模型的优缺点。
关键设计:TopViewRS数据集包含11384个多项选择题,分为四个任务:对象识别、相对位置理解、空间推理和导航。数据集的构建过程中,作者精心设计了问题的难度和类型,以确保能够全面评估模型的空间推理能力。此外,作者还探索了思维链推理方法对模型性能的影响。
🖼️ 关键图片
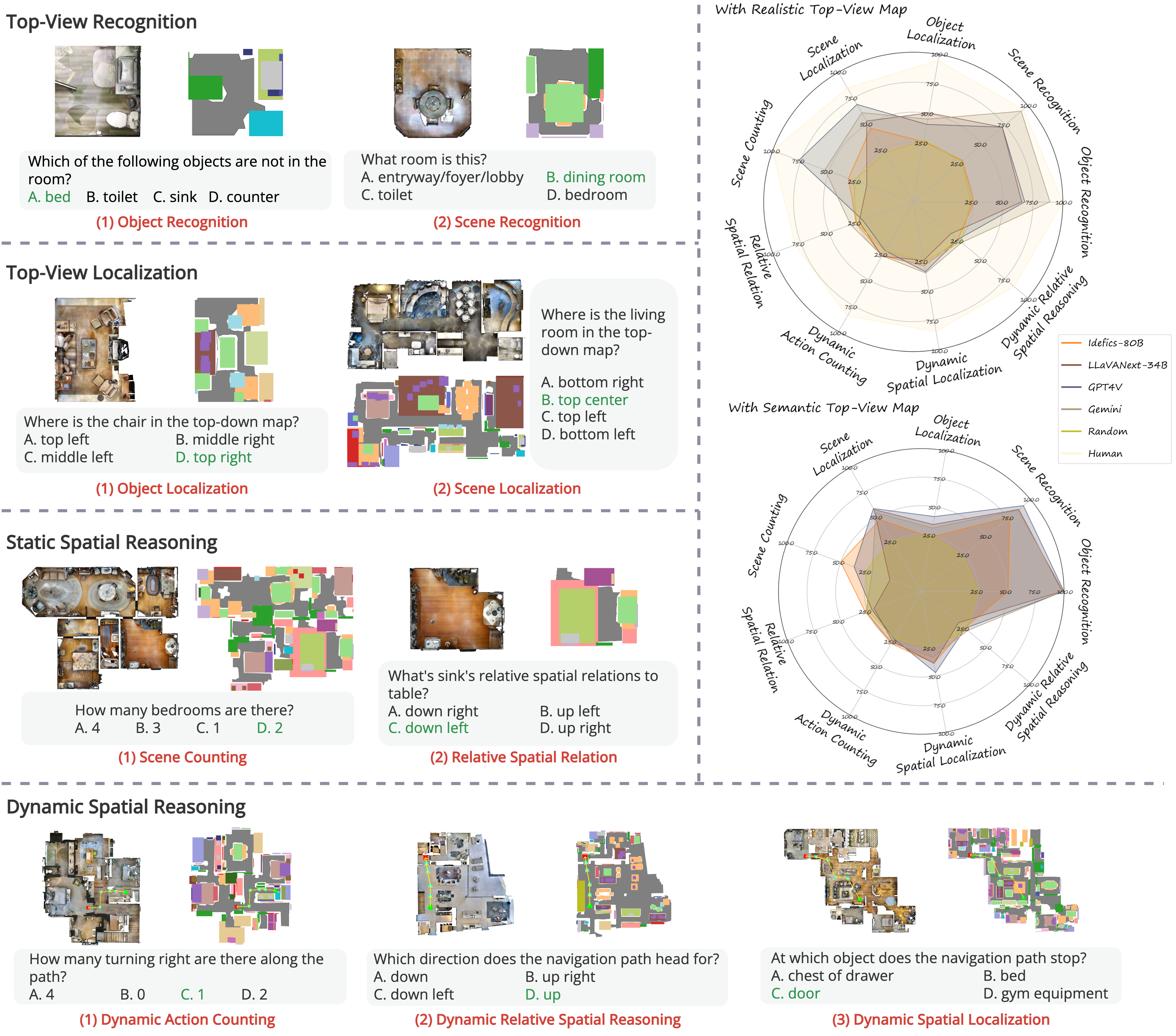


📊 实验亮点
实验结果表明,现有视觉-语言模型在TopViewRS数据集上的表现与人类平均水平相比差距超过50%,甚至低于随机基线。尽管思维链推理可以平均提升模型能力5.82%,但总体性能仍然有限。这些结果突显了现有模型在鸟瞰空间推理方面的不足,并为未来的研究方向提供了重要启示。
🎯 应用场景
该研究成果可应用于自动驾驶、机器人导航、智能城市规划等领域。通过提升视觉-语言模型在鸟瞰视角下的空间推理能力,可以提高机器人在复杂环境中的定位、导航和决策能力,从而实现更安全、更高效的智能化应用。
📄 摘要(原文)
Top-view perspective denotes a typical way in which humans read and reason over different types of maps, and it is vital for localization and navigation of humans as well as of `non-human' agents, such as the ones backed by large Vision-Language Models (VLMs). Nonetheless, spatial reasoning capabilities of modern VLMs remain unattested and underexplored. In this work, we thus study their capability to understand and reason over spatial relations from the top view. The focus on top view also enables controlled evaluations at different granularity of spatial reasoning; we clearly disentangle different abilities (e.g., recognizing particular objects versus understanding their relative positions). We introduce the TopViewRS (Top-View Reasoning in Space) dataset, consisting of 11,384 multiple-choice questions with either realistic or semantic top-view map as visual input. We then use it to study and evaluate VLMs across 4 perception and reasoning tasks with different levels of complexity. Evaluation of 10 representative open- and closed-source VLMs reveals the gap of more than 50% compared to average human performance, and it is even lower than the random baseline in some cases. Although additional experiments show that Chain-of-Thought reasoning can boost model capabilities by 5.82% on average, the overall performance of VLMs remains limited. Our findings underscore the critical need for enhanced model capability in top-view spatial reasoning and set a foundation for further research towards human-level proficiency of VLMs in real-world multimodal tasks.