Large Language Models Make Sample-Efficient Recommender Systems
作者: Jianghao Lin, Xinyi Dai, Rong Shan, Bo Chen, Ruiming Tang, Yong Yu, Weinan Zhang
分类: cs.IR, cs.CL
发布日期: 2024-06-04
备注: Accepted by Frontier of Computer Science
💡 一句话要点
提出Laser框架,验证大语言模型提升推荐系统在小样本学习场景下的性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 推荐系统 大型语言模型 小样本学习 特征工程 样本效率
📋 核心要点
- 传统推荐模型因特征稀疏性,需要大量训练数据,导致样本效率低下。
- 提出Laser框架,利用LLM自身能力及作为特征生成器/编码器的能力,提升推荐系统样本效率。
- 实验表明,Laser仅用少量训练样本即可达到甚至超越传统模型在全量数据上的性能。
📝 摘要(中文)
大型语言模型(LLM)在自然语言处理(NLP)领域取得了显著进展,在生成类似人类语言的文本方面表现出卓越的能力,为将其应用于推荐系统(RS)开辟了新的机会。本文重点研究了LLM增强的推荐系统的样本效率,即模型在有限的训练数据量下获得卓越性能的能力。传统的推荐模型(CRM)由于特征和交互的稀疏性,通常需要大量的训练数据。因此,我们提出并验证了我们的核心观点:大型语言模型能够提升推荐系统的样本效率。我们提出了一个简单而有效的框架(即Laser)来从两个方面验证这一观点:(1)LLM本身就是样本高效的推荐器;(2)LLM作为特征生成器和编码器,使CRM更具样本效率。在两个公共数据集上的大量实验表明,Laser仅需一小部分训练样本即可匹配甚至超过在整个训练集上训练的CRM,从而展示出卓越的样本效率。
🔬 方法详解
问题定义:传统推荐模型(CRM)在数据稀疏性问题下,需要大量的训练数据才能达到较好的性能。这在数据获取成本高昂或者用户行为数据本身就稀疏的场景下,是一个很大的挑战。因此,如何提升推荐系统在小样本学习场景下的性能,是一个亟待解决的问题。
核心思路:论文的核心思路是利用大型语言模型(LLM)强大的语言理解和生成能力,来提升推荐系统的样本效率。具体来说,LLM既可以作为独立的推荐器直接进行推荐,也可以作为特征生成器和编码器,为传统的推荐模型提供更丰富、更有效的特征表示。
技术框架:Laser框架主要包含两个方面:(1) LLM作为独立的推荐器:直接利用LLM的文本生成能力,根据用户历史行为和物品信息生成推荐结果。(2) LLM作为特征生成器和编码器:利用LLM生成物品的文本描述或用户行为的文本表示,然后将这些文本信息输入到传统的推荐模型中进行训练。整体流程是先利用LLM进行特征增强,然后使用增强后的特征训练推荐模型。
关键创新:论文的关键创新在于将大型语言模型引入到推荐系统中,并验证了LLM在提升推荐系统样本效率方面的潜力。与传统的推荐模型相比,Laser框架能够利用LLM的先验知识和强大的泛化能力,从而在小样本场景下取得更好的性能。
关键设计:在LLM作为独立推荐器时,关键在于如何设计合适的prompt,引导LLM生成准确的推荐结果。在LLM作为特征生成器和编码器时,关键在于如何选择合适的LLM,以及如何将LLM生成的文本信息有效地融入到传统的推荐模型中。论文中具体使用了不同的prompt模版,并尝试了不同的LLM模型。损失函数方面,主要采用交叉熵损失函数。
🖼️ 关键图片
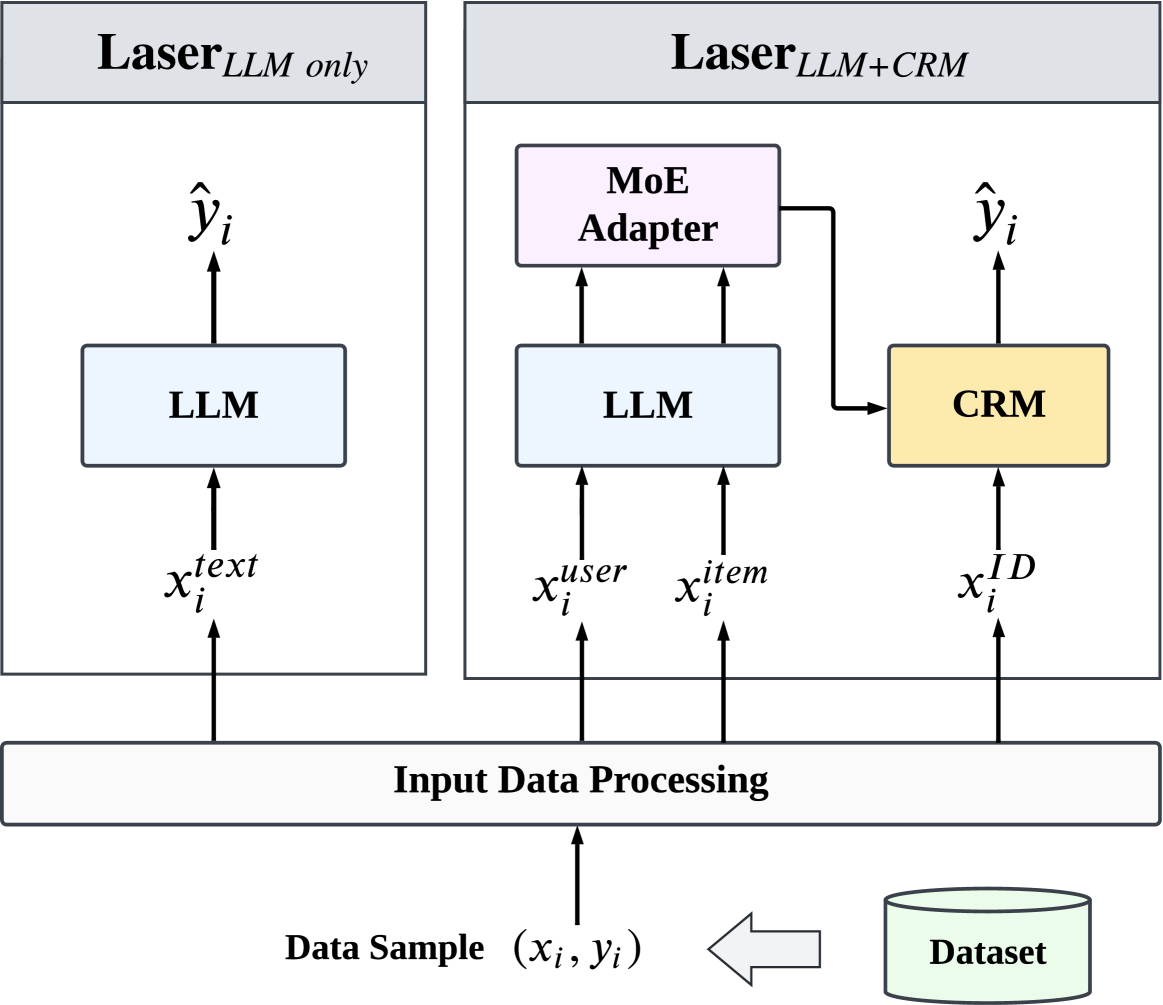
📊 实验亮点
实验结果表明,Laser框架在两个公共数据集上都取得了显著的性能提升。例如,在某个数据集上,Laser仅使用10%的训练数据,就能达到甚至超过传统推荐模型在全量数据上的性能。这充分证明了LLM在提升推荐系统样本效率方面的潜力。
🎯 应用场景
该研究成果可应用于各种推荐系统场景,尤其是在冷启动、长尾物品推荐等数据稀疏的场景下。通过利用LLM的知识和推理能力,可以有效提升推荐系统的准确性和用户体验。此外,该方法还可以应用于个性化教育、智能客服等领域,为用户提供更加精准和个性化的服务。
📄 摘要(原文)
Large language models (LLMs) have achieved remarkable progress in the field of natural language processing (NLP), demonstrating remarkable abilities in producing text that resembles human language for various tasks. This opens up new opportunities for employing them in recommender systems (RSs). In this paper, we specifically examine the sample efficiency of LLM-enhanced recommender systems, which pertains to the model's capacity to attain superior performance with a limited quantity of training data. Conventional recommendation models (CRMs) often need a large amount of training data because of the sparsity of features and interactions. Hence, we propose and verify our core viewpoint: Large Language Models Make Sample-Efficient Recommender Systems. We propose a simple yet effective framework (i.e., Laser) to validate the viewpoint from two aspects: (1) LLMs themselves are sample-efficient recommenders; and (2) LLMs, as feature generators and encoders, make CRMs more sample-efficient. Extensive experiments on two public datasets show that Laser requires only a small fraction of training samples to match or even surpass CRMs that are trained on the entire training set, demonstrating superior sample efficiency.