Learning to Clarify: Multi-turn Conversations with Action-Based Contrastive Self-Training
作者: Maximillian Chen, Ruoxi Sun, Tomas Pfister, Sercan Ö. Arık
分类: cs.CL, cs.AI, cs.LG
发布日期: 2024-05-31 (更新: 2025-07-27)
备注: ICLR 2025; Code: https://github.com/google-research/google-research/tree/master/learning_to_clarify
💡 一句话要点
提出基于动作对比自训练的ACT方法,提升LLM在多轮对话中澄清用户意图的能力。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 对话系统 大型语言模型 消除歧义 对比学习 自训练
📋 核心要点
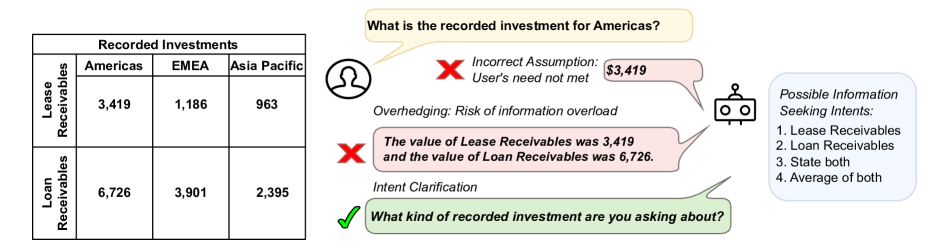
- 大型语言模型在对话中缺乏有效消除歧义的能力,常常猜测用户意图而非主动澄清。
- 提出Action-Based Contrastive Self-Training (ACT) 方法,通过对比学习提升模型对话策略。
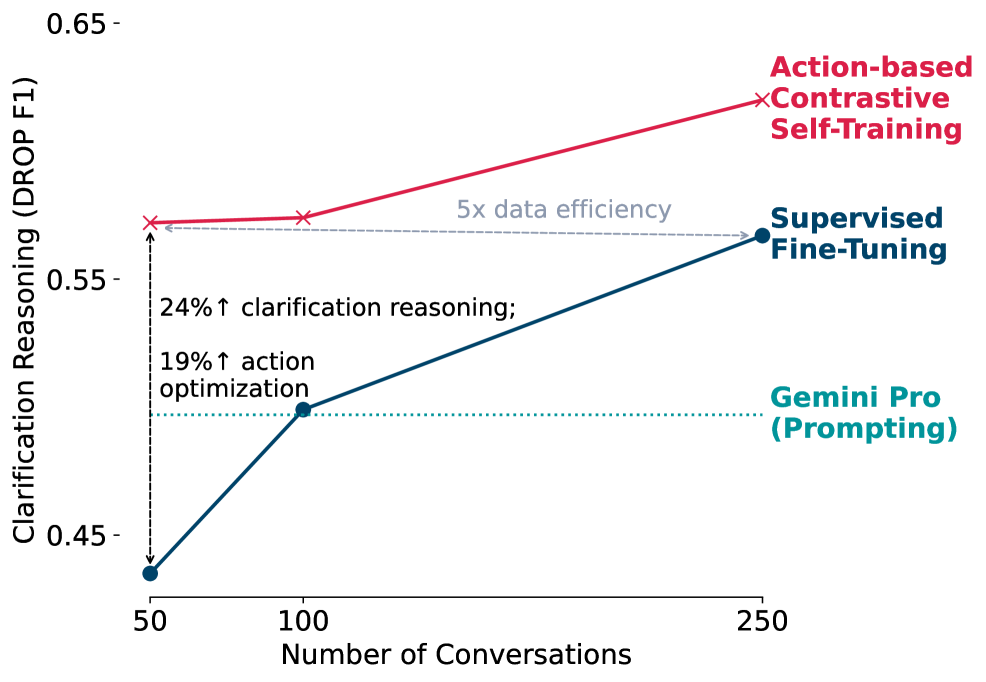
- 在表格问答、机器阅读理解和AmbigSQL等任务上,ACT显著优于监督微调和DPO等基线方法。
📝 摘要(中文)
大型语言模型(LLMs)通过人类反馈优化,已迅速成为开发智能对话助手的领先范例。然而,尽管它们在许多基准测试中表现出色,但基于LLM的代理可能仍然缺乏诸如消除歧义之类的对话技巧——当它们面临歧义时,它们通常会过度回避或隐式地猜测用户的真实意图,而不是提出澄清问题。在特定任务设置下,高质量的对话样本通常受到限制,这构成了LLM学习最佳对话动作策略的瓶颈。我们提出了一种基于动作对比自训练(ACT)的准在线偏好优化算法,该算法基于直接偏好优化(DPO),能够在多轮对话建模中实现数据高效的对话策略学习。我们通过多个真实世界的对话任务(表格问答、机器阅读理解和AmbigSQL)证明了ACT在数据高效调优场景下的有效性,即使没有可用的动作标签。此外,我们建议通过检查LLM是否可以隐式地识别和推理对话中的歧义来评估LLM作为对话代理的能力。ACT展示了相对于标准调优方法(如监督微调和DPO)的显著对话建模改进。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLMs)在多轮对话中消除歧义能力不足的问题。现有方法,如监督微调和直接偏好优化(DPO),在数据量有限的情况下难以学习到有效的对话策略,尤其是在需要主动澄清用户意图时,模型倾向于猜测或回避,影响对话质量。
核心思路:论文的核心思路是利用动作对比自训练(ACT)方法,通过对比学习的方式,让模型学习区分不同动作的优劣,从而优化对话策略。ACT基于DPO框架,但引入了动作的概念,使得模型能够更好地理解对话上下文,并根据当前状态选择合适的动作(例如,提出澄清问题)。
技术框架:ACT的整体框架基于DPO,包含以下主要阶段:1) 数据收集:收集包含对话历史、用户意图和模型动作的对话数据。2) 动作选择:模型根据对话历史选择一个动作。3) 偏好学习:使用对比学习的方式,让模型学习区分不同动作的优劣,即哪些动作更符合用户的意图。4) 策略优化:使用DPO算法,根据学习到的偏好信息,优化模型的对话策略。
关键创新:ACT的关键创新在于引入了动作的概念,并将对比学习应用于对话策略优化。与传统的DPO方法相比,ACT能够更好地利用对话上下文信息,学习到更有效的对话策略。此外,ACT还可以在没有动作标签的情况下进行训练,进一步提高了其适用性。
关键设计:ACT的关键设计包括:1) 动作空间的设计:需要定义一个合适的动作空间,包含模型可以采取的各种动作,例如,提出澄清问题、提供信息等。2) 对比损失函数的设计:需要设计一个合适的对比损失函数,用于衡量不同动作之间的优劣。3) DPO算法的参数设置:需要根据具体任务调整DPO算法的参数,以获得最佳性能。
🖼️ 关键图片

📊 实验亮点
实验结果表明,ACT在表格问答、机器阅读理解和AmbigSQL等任务上均取得了显著的性能提升。例如,在AmbigSQL任务上,ACT相较于DPO方法取得了显著的提升,证明了其在消除歧义方面的有效性。即使在没有动作标签的情况下,ACT仍然能够取得良好的性能,进一步验证了其鲁棒性。
🎯 应用场景
该研究成果可应用于各种对话系统,例如智能客服、虚拟助手和任务型对话系统。通过提升模型消除歧义的能力,可以显著改善用户体验,提高对话效率,并减少人工干预的需求。未来,该方法有望扩展到更复杂的对话场景,例如多模态对话和个性化对话。
📄 摘要(原文)
Large language models (LLMs), optimized through human feedback, have rapidly emerged as a leading paradigm for developing intelligent conversational assistants. However, despite their strong performance across many benchmarks, LLM-based agents might still lack conversational skills such as disambiguation -- when they are faced with ambiguity, they often overhedge or implicitly guess users' true intents rather than asking clarification questions. Under task-specific settings, high-quality conversation samples are often limited, constituting a bottleneck for LLMs' ability to learn optimal dialogue action policies. We propose Action-Based Contrastive Self-Training (ACT), a quasi-online preference optimization algorithm based on Direct Preference Optimization (DPO), that enables data-efficient dialogue policy learning in multi-turn conversation modeling. We demonstrate ACT's efficacy under in data-efficient tuning scenarios, even when there is no action label available, using multiple real-world conversational tasks: tabular-grounded question-answering, machine reading comprehension, and AmbigSQL, a novel task for disambiguating information-seeking requests for complex SQL generation towards data analysis agents. Additionally, we propose evaluating LLMs' ability to function as conversational agents by examining whether they can implicitly recognize and reason about ambiguity in conversation. ACT demonstrates substantial conversation modeling improvements over standard tuning approaches like supervised fine-tuning and DPO.