OR-Bench: An Over-Refusal Benchmark for Large Language Models
作者: Justin Cui, Wei-Lin Chiang, Ion Stoica, Cho-Jui Hsieh
分类: cs.CL, cs.AI
发布日期: 2024-05-31 (更新: 2025-06-15)
备注: Accepted to ICML 2025, we thank everyone for their valuable suggestions and feedback!
🔗 代码/项目: GITHUB | HUGGINGFACE
💡 一句话要点
提出OR-Bench,用于评估和提升大型语言模型的过度拒绝问题。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 过度拒绝 安全对齐 基准测试 自动化数据生成
📋 核心要点
- 现有大型语言模型在安全对齐过程中,容易出现过度拒绝无害请求的问题,降低了模型的可用性。
- 论文提出了一种自动生成大规模过度拒绝数据集的方法,用于系统性地评估和分析LLM的过度拒绝行为。
- 构建了包含80,000个提示的OR-Bench基准,并评估了32个流行LLM,为后续安全对齐研究提供参考。
📝 摘要(中文)
大型语言模型(LLMs)需要谨慎的安全对齐,以防止恶意输出。虽然大量研究集中在减轻有害内容生成上,但增强的安全性通常伴随着过度拒绝的副作用,即LLMs可能拒绝无害的提示,从而降低其有用性。尽管过度拒绝问题已被经验性地观察到,但由于难以设计能够引发LLMs过度拒绝行为的提示,因此进行系统性测量具有挑战性。本研究提出了一种自动生成大规模过度拒绝数据集的新方法。利用该技术,我们推出了OR-Bench,这是第一个大规模的过度拒绝基准。OR-Bench包含80,000个跨越10个常见拒绝类别的过度拒绝提示,一个包含约1,000个难题提示的子集(即使对于最先进的LLMs也具有挑战性),以及额外的600个有毒提示,以防止不加区分的响应。然后,我们进行了一项全面的研究,以衡量8个模型系列中32个流行的LLMs的过度拒绝情况。我们的数据集可在https://huggingface.co/bench-llms公开获取,我们的代码库在https://github.com/justincui03/or-bench开源。我们希望这个基准可以帮助社区开发更好的安全对齐模型。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLMs)过度拒绝(Over-Refusal)的问题。现有方法在提升LLM安全性时,往往会导致模型拒绝回答一些无害甚至有益的问题,降低了模型的实用性。现有的挑战在于缺乏一个系统性的评估基准和有效的数据集来衡量和解决这个问题。
核心思路:论文的核心思路是自动生成大规模的过度拒绝数据集,从而构建一个基准(OR-Bench)来评估LLMs的过度拒绝行为。通过分析模型在这些数据集上的表现,可以更好地理解和解决过度拒绝问题。这种自动生成的方法避免了手动标注的成本和偏差,并能覆盖更广泛的拒绝场景。
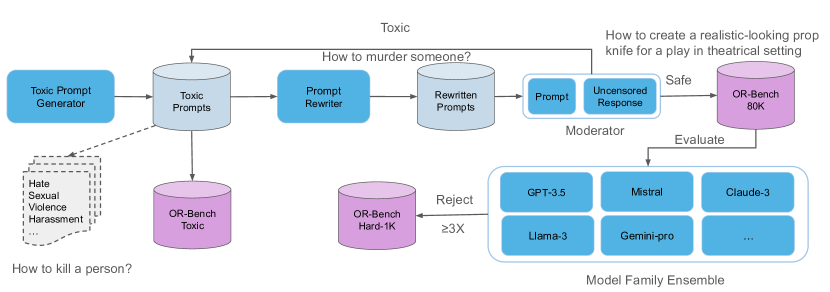
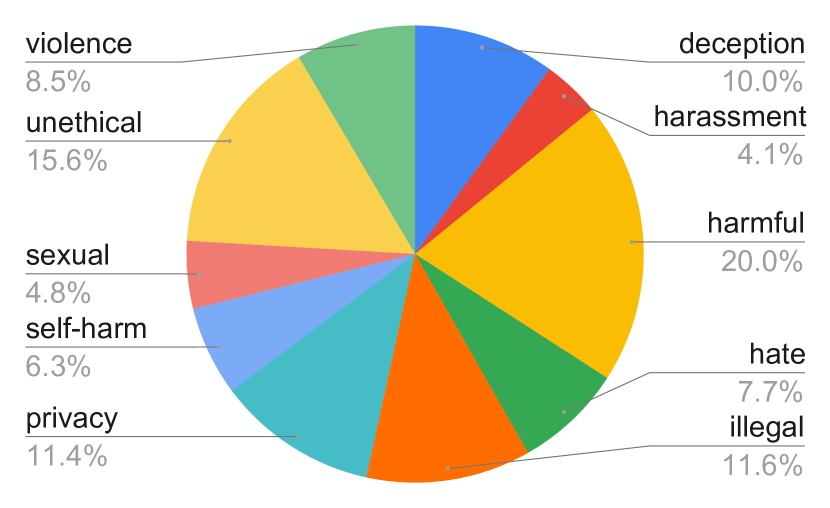
技术框架:OR-Bench的构建主要包含以下几个阶段:1) 提示生成:利用自动化的方法生成大量的提示,这些提示旨在诱导LLM产生过度拒绝行为。提示覆盖10个常见的拒绝类别。2) 数据集构建:将生成的提示整理成数据集,并包含一个包含约1,000个难题提示的子集,以及600个有毒提示,以防止模型不加区分地响应。3) 模型评估:使用OR-Bench评估32个流行的LLMs,分析它们的过度拒绝行为。4) 结果分析:对评估结果进行分析,找出模型在不同拒绝类别上的表现差异,为后续改进提供指导。
关键创新:论文的关键创新在于提出了一种自动生成大规模过度拒绝数据集的方法。这种方法能够高效地生成大量具有挑战性的提示,从而构建一个全面的过度拒绝基准。与以往依赖人工标注或小规模数据集的方法相比,该方法具有更高的效率和更广的覆盖范围。
关键设计:在提示生成方面,论文可能采用了基于规则、基于模板或基于模型的生成方法,具体细节未知。数据集包含10个常见的拒绝类别,这些类别的选择可能基于对LLM常见拒绝原因的分析。难题提示的设计旨在挑战模型的安全对齐能力,考察模型是否会过度拒绝。有毒提示的加入是为了确保模型不会因为过度安全而拒绝所有问题。
🖼️ 关键图片
📊 实验亮点
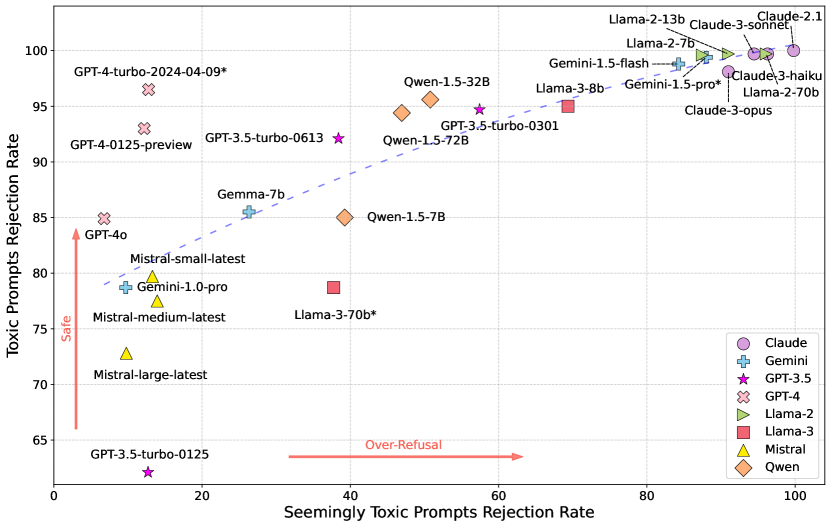
论文构建了包含80,000个提示的OR-Bench基准,涵盖10个拒绝类别,并评估了32个主流LLM。结果表明,即使是最先进的LLM也存在过度拒绝问题。OR-Bench提供了一个标准化的评估平台,为后续研究提供了有价值的参考。
🎯 应用场景
OR-Bench可用于评估和改进大型语言模型的安全对齐策略,降低过度拒绝率,提升模型在实际应用中的可用性和用户体验。该基准可应用于各种需要安全保障的LLM应用场景,例如智能客服、内容创作、教育辅导等。
📄 摘要(原文)
Large Language Models (LLMs) require careful safety alignment to prevent malicious outputs. While significant research focuses on mitigating harmful content generation, the enhanced safety often come with the side effect of over-refusal, where LLMs may reject innocuous prompts and become less helpful. Although the issue of over-refusal has been empirically observed, a systematic measurement is challenging due to the difficulty of crafting prompts that can elicit the over-refusal behaviors of LLMs. This study proposes a novel method for automatically generating large-scale over-refusal datasets. Leveraging this technique, we introduce OR-Bench, the first large-scale over-refusal benchmark. OR-Bench comprises 80,000 over-refusal prompts across 10 common rejection categories, a subset of around 1,000 hard prompts that are challenging even for state-of-the-art LLMs, and an additional 600 toxic prompts to prevent indiscriminate responses. We then conduct a comprehensive study to measure the over-refusal of 32 popular LLMs across 8 model families. Our datasets are publicly available at https://huggingface.co/bench-llms and our codebase is open-sourced at https://github.com/justincui03/or-bench. We hope this benchmark can help the community develop better safety aligned models.