Self-Augmented Preference Optimization: Off-Policy Paradigms for Language Model Alignment
作者: Yueqin Yin, Zhendong Wang, Yujia Xie, Weizhu Chen, Mingyuan Zhou
分类: cs.CL, cs.LG
发布日期: 2024-05-31
🔗 代码/项目: GITHUB
💡 一句话要点
提出自增强偏好优化(SAPO),无需配对数据对语言模型进行对齐。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 语言模型对齐 偏好优化 自增强学习 离线策略学习 自博弈 无监督学习 LLM微调
📋 核心要点
- 现有语言模型对齐方法依赖静态配对偏好数据,限制了其适应性和实际应用。
- SAPO基于自博弈和离线策略学习,无需配对数据即可实现语言模型对齐。
- 实验表明,SAPO在多个基准测试中与或优于DPO等基线方法,并超越SPIN。
📝 摘要(中文)
传统的语言模型对齐方法,如直接偏好优化(DPO),受限于对静态、预先收集的配对偏好数据的依赖,这阻碍了它们的适应性和实际应用。为了克服这个限制,我们引入了自增强偏好优化(SAPO),这是一种有效且可扩展的训练范式,不需要现有的配对数据。基于自主生成负面响应的自博弈概念,我们进一步结合了离线策略学习流程,以增强数据探索和利用。具体来说,我们采用指数移动平均(EMA)模型与回放缓冲区相结合,以实现响应片段的动态更新,有效地将实时反馈与历史数据的见解相结合。我们对LLaMA3-8B和Mistral-7B模型在包括Open LLM Leaderboard、IFEval、AlpacaEval 2.0和MT-Bench在内的基准测试中的全面评估表明,SAPO与已建立的离线对比基线(如DPO和Odds Ratio Preference Optimization)相匹配或超过它们,并且优于离线自博弈方法(如SPIN)。我们的代码可在https://github.com/yinyueqin/SAPO 获取。
🔬 方法详解
问题定义:现有语言模型对齐方法,如DPO,需要预先收集的配对偏好数据。这种依赖性限制了模型的适应性和泛化能力,因为真实世界的偏好是动态变化的,难以完全通过静态数据捕捉。此外,收集高质量的配对偏好数据成本高昂,阻碍了这些方法的大规模应用。
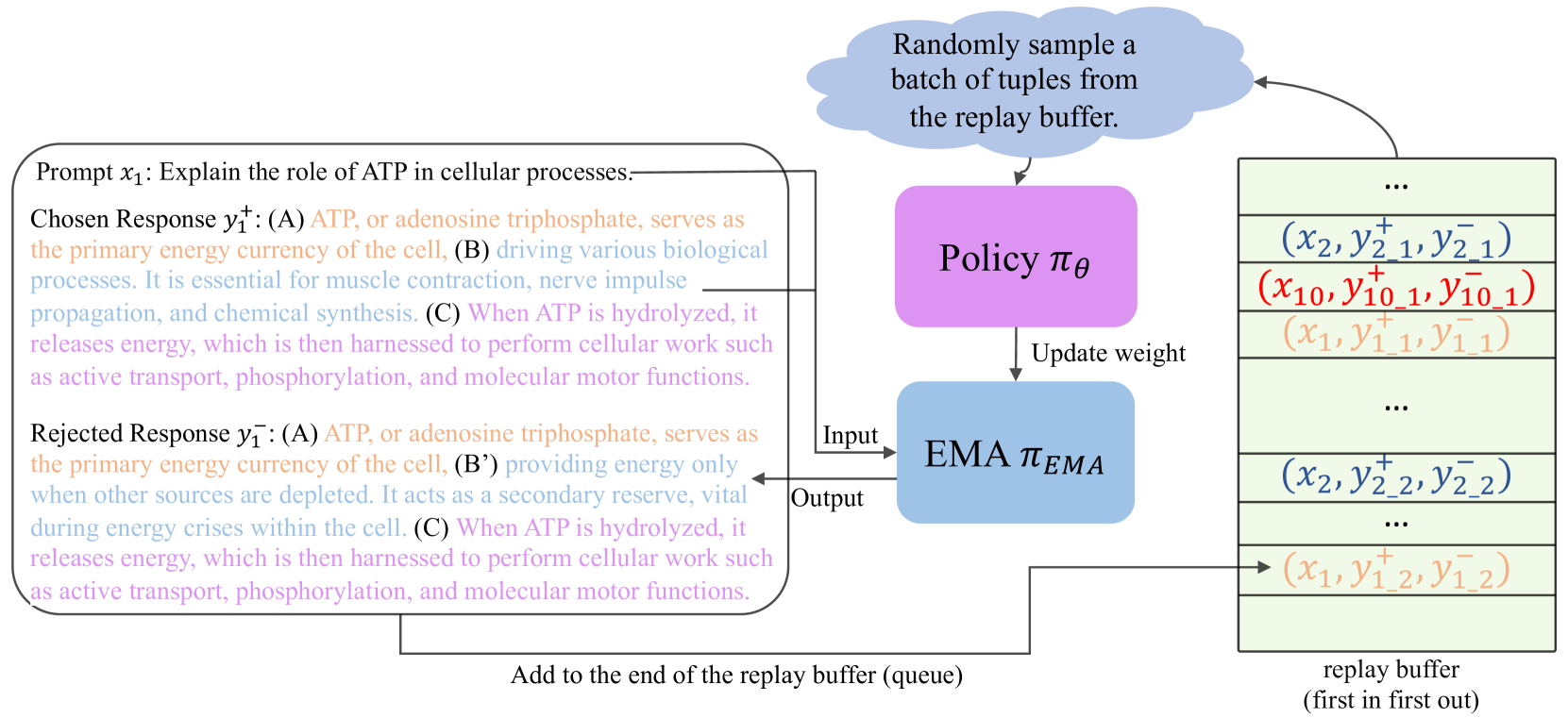
核心思路:SAPO的核心思路是通过自增强的方式,在训练过程中动态生成负样本,从而摆脱对预先收集的配对数据的依赖。它结合了自博弈和离线策略学习,利用模型自身生成的数据进行训练,并利用历史数据来稳定训练过程,提高数据利用率。
技术框架:SAPO的整体框架包括以下几个主要模块:1) 自博弈模块:使用当前模型生成正样本和负样本。2) 指数移动平均(EMA)模型:维护一个EMA模型,用于生成更稳定的负样本。3) 回放缓冲区:存储历史生成的样本,用于离线策略学习。4) 偏好优化模块:使用生成的样本和历史样本,通过偏好优化算法(如DPO)更新模型。
关键创新:SAPO的关键创新在于其自增强的训练范式,它无需预先收集的配对数据,而是通过自博弈和离线策略学习动态生成训练数据。这种方法能够更好地适应动态变化的偏好,并降低数据收集成本。此外,EMA模型和回放缓冲区的引入,进一步提高了训练的稳定性和数据利用率。
关键设计:SAPO的关键设计包括:1) EMA模型的衰减率:控制EMA模型对当前模型的依赖程度。2) 回放缓冲区的大小:决定了历史数据的保留量。3) 偏好优化算法的选择:可以使用DPO或其他偏好优化算法。4) 损失函数的设计:用于衡量模型生成的样本与目标偏好之间的差距。
🖼️ 关键图片

📊 实验亮点
实验结果表明,SAPO在LLaMA3-8B和Mistral-7B模型上取得了显著的性能提升。在Open LLM Leaderboard、IFEval、AlpacaEval 2.0和MT-Bench等基准测试中,SAPO与DPO和Odds Ratio Preference Optimization等离线对比基线相匹配或超过它们,并且优于SPIN。这证明了SAPO在无需配对数据的情况下,能够有效地对齐语言模型。
🎯 应用场景
SAPO具有广泛的应用前景,可用于各种需要语言模型对齐的场景,例如对话系统、文本生成、代码生成等。它尤其适用于数据稀缺或偏好动态变化的场景,能够降低数据收集成本,提高模型性能和适应性。未来,SAPO可以进一步扩展到多模态场景,实现更复杂的人工智能任务。
📄 摘要(原文)
Traditional language model alignment methods, such as Direct Preference Optimization (DPO), are limited by their dependence on static, pre-collected paired preference data, which hampers their adaptability and practical applicability. To overcome this limitation, we introduce Self-Augmented Preference Optimization (SAPO), an effective and scalable training paradigm that does not require existing paired data. Building on the self-play concept, which autonomously generates negative responses, we further incorporate an off-policy learning pipeline to enhance data exploration and exploitation. Specifically, we employ an Exponential Moving Average (EMA) model in conjunction with a replay buffer to enable dynamic updates of response segments, effectively integrating real-time feedback with insights from historical data. Our comprehensive evaluations of the LLaMA3-8B and Mistral-7B models across benchmarks, including the Open LLM Leaderboard, IFEval, AlpacaEval 2.0, and MT-Bench, demonstrate that SAPO matches or surpasses established offline contrastive baselines, such as DPO and Odds Ratio Preference Optimization, and outperforms offline self-play methods like SPIN. Our code is available at https://github.com/yinyueqin/SAPO