How Multilingual Are Large Language Models Fine-Tuned for Translation?
作者: Aquia Richburg, Marine Carpuat
分类: cs.CL, cs.LG
发布日期: 2024-05-30
💡 一句话要点
研究翻译微调对大型语言模型多语言翻译能力的影响
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 机器翻译 多语言翻译 零样本学习 微调
📋 核心要点
- 现有机器翻译方法依赖于大量平行语料,而直接微调大型语言模型展现出更优越的性能,但其多语言能力尚不明确。
- 该研究通过评估TOWER模型家族在多种翻译任务上的表现,考察翻译微调对零样本语言和语言对的影响。
- 实验结果表明,翻译微调平均而言可以提升零样本语言的翻译质量,但不同语言对之间的效果存在差异。
📝 摘要(中文)
机器翻译领域涌现了一种新范式:在平行文本上微调大型语言模型(LLM)已被证明优于在更大规模平行数据上以监督方式训练的专用翻译系统。然而,这种范式是否能够实现大规模多语言机器翻译,或者是否需要为少量语言对微调专用模型,仍然不清楚。翻译微调如何影响LLM在零样本语言、零样本语言对以及不涉及英语的翻译任务中的机器翻译能力?为了解决这些问题,我们对TOWER系列语言模型在FLORES-200数据集的132个翻译任务上进行了广泛的实证评估。我们发现,平均而言,即使对于零样本语言,翻译微调也能提高翻译质量,但其影响因所涉及的语言对而异。这些结果呼吁进一步研究,以有效实现LLM的大规模多语言翻译。
🔬 方法详解
问题定义:论文旨在研究在平行语料上微调大型语言模型(LLM)后,其多语言翻译能力如何。现有方法,即专门训练的翻译系统,虽然在特定语言对上表现良好,但需要大量平行数据,且难以泛化到零样本语言或语言对。因此,如何利用LLM实现高效且通用的多语言翻译是一个关键问题。
核心思路:核心思路是通过对LLM进行翻译微调,使其具备更好的翻译能力,并考察这种微调对不同语言对,特别是零样本语言对的影响。通过分析微调后模型在不同翻译任务上的表现,评估其多语言翻译的泛化能力。
技术框架:该研究主要基于TOWER系列语言模型,并使用FLORES-200数据集进行评估。FLORES-200包含大量语言对的平行语料,涵盖132个翻译任务。研究人员对TOWER模型进行翻译微调,然后在FLORES-200数据集上进行测试,评估其在不同语言对上的翻译质量。
关键创新:该研究的关键创新在于系统性地评估了翻译微调对LLM多语言翻译能力的影响,特别是对零样本语言和语言对的性能。通过大规模实验,揭示了翻译微调在不同语言对上的效果差异,为进一步研究LLM的多语言翻译能力提供了重要依据。
关键设计:研究中使用了TOWER系列语言模型,具体模型细节未知。评估指标未知。微调的具体参数设置未知。损失函数未知。网络结构未知。
🖼️ 关键图片
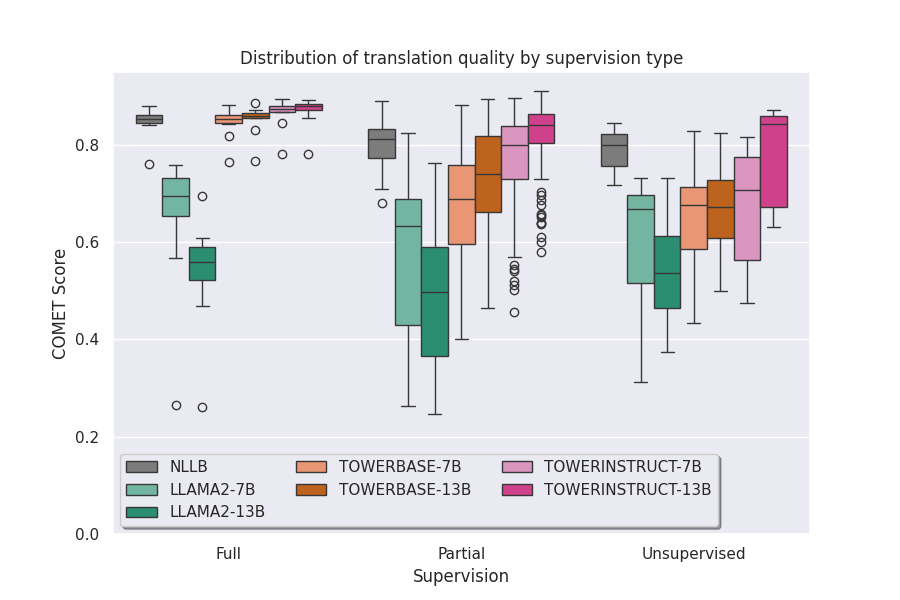


📊 实验亮点
实验结果表明,翻译微调平均而言可以提高零样本语言的翻译质量,但不同语言对之间的效果存在显著差异。具体性能数据未知,但该研究揭示了翻译微调对LLM多语言翻译能力的复杂影响,为后续研究提供了重要参考。
🎯 应用场景
该研究成果可应用于开发更高效、更通用的多语言机器翻译系统,尤其是在资源匮乏的语言对上。通过优化LLM的翻译微调策略,可以降低对大规模平行语料的依赖,实现低成本、高质量的机器翻译服务,促进跨语言交流和信息共享。
📄 摘要(原文)
A new paradigm for machine translation has recently emerged: fine-tuning large language models (LLM) on parallel text has been shown to outperform dedicated translation systems trained in a supervised fashion on much larger amounts of parallel data (Xu et al., 2024a; Alves et al., 2024). However, it remains unclear whether this paradigm can enable massively multilingual machine translation or whether it requires fine-tuning dedicated models for a small number of language pairs. How does translation fine-tuning impact the MT capabilities of LLMs for zero-shot languages, zero-shot language pairs, and translation tasks that do not involve English? To address these questions, we conduct an extensive empirical evaluation of the translation quality of the TOWER family of language models (Alves et al., 2024) on 132 translation tasks from the multi-parallel FLORES-200 data. We find that translation fine-tuning improves translation quality even for zero-shot languages on average, but that the impact is uneven depending on the language pairs involved. These results call for further research to effectively enable massively multilingual translation with LLMs.