Group Robust Preference Optimization in Reward-free RLHF
作者: Shyam Sundhar Ramesh, Yifan Hu, Iason Chaimalas, Viraj Mehta, Pier Giuseppe Sessa, Haitham Bou Ammar, Ilija Bogunovic
分类: cs.CL, cs.LG
发布日期: 2024-05-30
备注: Preprint
💡 一句话要点
提出GRPO方法,在无奖励RLHF中实现对不同群体偏好的鲁棒优化。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 强化学习 人类反馈 偏好优化 群体鲁棒性 大型语言模型
📋 核心要点
- 现有RLHF方法忽略了不同标注者群体的偏好差异,采用“一刀切”的策略,导致模型对所有群体不够鲁棒。
- GRPO的核心思想是寻找一种鲁棒策略,最大化最差情况下的群体表现,通过自适应地调整群体权重来实现。
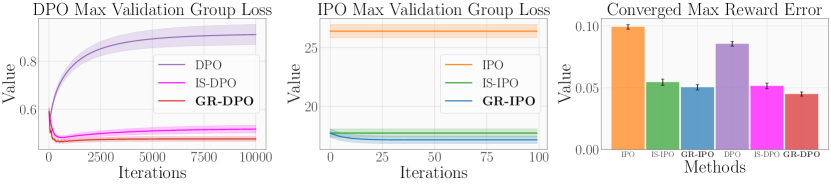
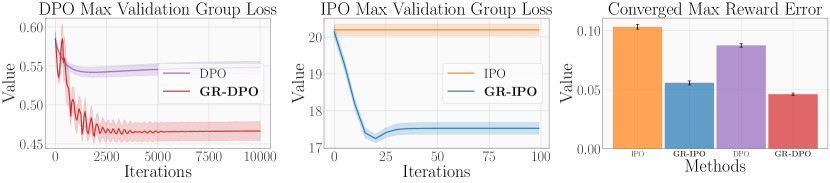
- 实验表明,GRPO显著提高了表现最差群体的性能,减少了群体间的损失不平衡,并提高了概率准确性。
📝 摘要(中文)
为了使大型语言模型(LLMs)适应特定任务,通常需要通过基于偏好数据的强化学习与人类反馈(RLHF)进行微调。然而,这些数据通常来自不同的标注者群体(例如,不同的统计人口、种族、公司团队等)。传统的RLHF方法采用“一刀切”的方式,不加区分地假设和优化单一偏好模型,因此无法应对不同群体的独特特征和需求。为了解决这一局限性,我们提出了一种新的群体鲁棒偏好优化(GRPO)方法,以稳健地将LLM与各个群体的偏好对齐。我们的方法建立在无奖励的直接偏好优化方法之上,但与以往的方法不同,它寻求一种鲁棒的策略,以最大化最差情况下的群体表现。为了实现这一目标,GRPO自适应地、顺序地对不同群体的重要性进行加权,优先考虑累积损失较差的群体。我们从理论上研究了GRPO的可行性,并分析了其对数线性策略类的收敛性。通过使用基于不同群体的全局意见数据,利用GRPO对LLM进行微调,我们显著提高了表现最差群体的性能,减少了群体间的损失不平衡,并提高了概率准确性,优于非鲁棒的基线方法。
🔬 方法详解
问题定义:论文旨在解决在RLHF中,现有方法无法有效处理来自不同群体的偏好差异,导致模型对所有群体不够鲁棒的问题。现有方法通常假设所有数据来自同一分布,忽略了不同群体之间可能存在的偏好差异,从而影响了模型的公平性和整体性能。
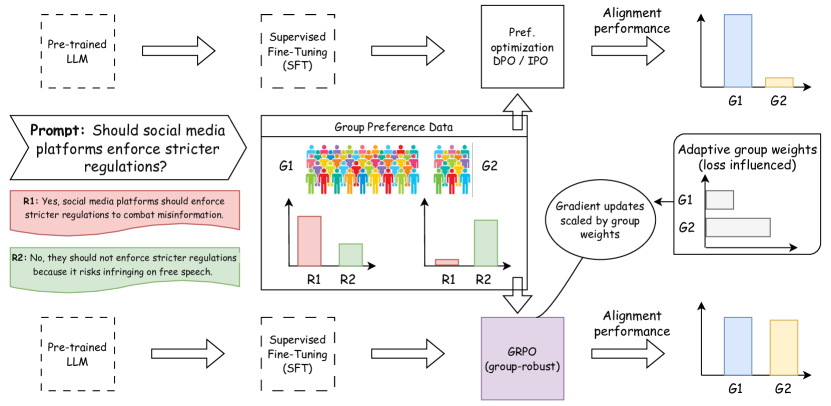
核心思路:论文的核心思路是寻找一个鲁棒的策略,该策略能够最大化所有群体中最差的表现。通过优化最差情况下的群体表现,可以确保模型对所有群体都具有较好的性能,从而提高模型的公平性和鲁棒性。这种方法避免了对所有群体采用单一偏好模型,而是针对每个群体进行优化。
技术框架:GRPO方法建立在无奖励的直接偏好优化方法之上。整体流程包括以下几个阶段:1)收集来自不同群体的偏好数据;2)初始化语言模型策略;3)迭代优化策略,在每次迭代中,计算每个群体的损失,并根据损失自适应地调整群体权重,优先考虑损失较大的群体;4)使用调整后的权重更新策略。该框架的核心是自适应权重调整机制,它能够动态地平衡不同群体之间的偏好。
关键创新:GRPO最重要的技术创新点在于其自适应的群体权重调整机制。与传统的RLHF方法不同,GRPO不是对所有群体采用相同的权重,而是根据每个群体的损失动态地调整权重。这种自适应的权重调整机制能够有效地平衡不同群体之间的偏好差异,从而提高模型的鲁棒性和公平性。
关键设计:GRPO的关键设计包括:1)损失函数的选择,用于衡量每个群体的表现;2)权重调整策略,用于自适应地调整群体权重;3)优化算法的选择,用于更新语言模型策略。论文理论分析了GRPO对数线性策略类的收敛性。具体实现细节(如损失函数、权重调整策略的具体公式)在论文中详细描述。
🖼️ 关键图片
📊 实验亮点
实验结果表明,GRPO方法显著提高了表现最差群体的性能,减少了群体间的损失不平衡,并提高了概率准确性。与非鲁棒的基线方法相比,GRPO在多个指标上都取得了显著的提升,证明了其在处理群体偏好差异方面的有效性。具体的性能提升幅度在论文实验部分有详细数据。
🎯 应用场景
GRPO方法可应用于各种需要考虑不同群体偏好的场景,例如:个性化推荐系统、公平的AI助手、以及针对不同文化背景用户的语言模型。该研究有助于提升AI系统的公平性、鲁棒性和用户满意度,并为构建更负责任和可信赖的AI系统奠定基础。未来,该方法可以扩展到更复杂的群体结构和偏好模型。
📄 摘要(原文)
Adapting large language models (LLMs) for specific tasks usually involves fine-tuning through reinforcement learning with human feedback (RLHF) on preference data. While these data often come from diverse labelers' groups (e.g., different demographics, ethnicities, company teams, etc.), traditional RLHF approaches adopt a "one-size-fits-all" approach, i.e., they indiscriminately assume and optimize a single preference model, thus not being robust to unique characteristics and needs of the various groups. To address this limitation, we propose a novel Group Robust Preference Optimization (GRPO) method to align LLMs to individual groups' preferences robustly. Our approach builds upon reward-free direct preference optimization methods, but unlike previous approaches, it seeks a robust policy which maximizes the worst-case group performance. To achieve this, GRPO adaptively and sequentially weights the importance of different groups, prioritizing groups with worse cumulative loss. We theoretically study the feasibility of GRPO and analyze its convergence for the log-linear policy class. By fine-tuning LLMs with GRPO using diverse group-based global opinion data, we significantly improved performance for the worst-performing groups, reduced loss imbalances across groups, and improved probability accuracies compared to non-robust baselines.